For a long time Bitnami containers and Helm charts have been widely considered the easiest and fastest way to get reliable, latest versions of popular applications built following container best practices. They also have some of the better docs on the internet for figuring out how to configure all this stuff.
However Broadcom, in their infinite capacity for short term gain over long term relationships, has decided to bring that to a close. On July 16th they informed their users that the platform was changing. Originally they were going to break a ton of workflows with only 43 days warning, but have expanded that out to a generous 75 days.
It's impossible to read these timelines as anything other than Broadcom knows that enterprise customers won't be able to switch off in 43 or 75 days and is using this to extort people into paying them the rumored $50,000 a year to keep using the images.
TL;DR: Bitnami is significantly reducing their free container image offerings and moving most existing images to a legacy repository with no future updates.
What's Changing:
Free Community Tier (Severely Limited):
Only a small subset of hardened images will remain free
Available only with "latest" tags (no version pinning)
All current Bitnami images (including versioned tags) move to docker.io/bitnamilegacy
No updates, patches, or support for legacy images
Use legacy repo only as temporary migration solution
Production Users:
Need to subscribe to "Bitnami Secure Images" for continued support
Includes security patches, LTS branches, and full version catalog
Action Items for DevOps Teams:
Before September 29th:
Audit your deployments - Check which Bitnami images you're using
Update CI/CD pipelines - Remove dependencies on deprecated images
Choose your path:
Development only: Migrate to the limited free tier (latest tags only)
Production: Subscribe to Bitnami Secure Images or find alternatives
Temporary fix: Update image references to bitnamilegacy/ (not recommended long-term)
Helm Charts:
Source code remains open source on GitHub
Existing OCI charts at docker.io/bitnamicharts won't receive updates
Charts will fail unless you override image repositories
Bottom Line:
If you're using Bitnami for anything beyond basic development with latest tags, you'll need to either pay for Bitnami Secure Images or migrate to alternative container images before September 29th.
So for years I've used Docker Compose as my stepping stone to k8s. If the project is small, or mostly for my own consumption OR if the business requirements don't really support the complexity of k8s, I use Compose. It's simple to manage with bash scripts for deployments, not hard to setup on fresh servers with cloud-init and the process of removing a server from a load balancer, pulling the new container, then adding it back in has been bulletproof for teams with limited headcount or services where uptime is less critical than cost control and ease of long-term maintenance. You avoid almost all of the complexity of really "running" a server while being able to scale up to about 20 VMs while still having a reasonable deployment time.
What are you talking about
Sure, so one common issue I hear is "we're a small team, k8s feels like overkill, what else is on the market"? The issue is there are tons and tons of ways to run containers on virtually every cloud platform, but a lot of them are locked to that cloud platform. They're also typically billed at premium pricing because they remove all the elements of "running a server".
That's fine but for small teams buying in too heavily to a vendor solution can be hard to get out of. Maybe they pick wrong and it gets deprecated, etc. So I try to push them towards a more simple stack that is more idiot-proof to manage. It varies by VPS provider but the basic stack looks like the following:
Debian servers setup with cloud-init to run all the updates, reboot, install the container manager of choice.
This also sets up Cloudflare tunnels so we can access the boxes securely and easily. Tailscale also works great/better for this. Avoids needing public IPs for each box.
Add a tag to each one of those servers so we know what it does (redis, app server, database)
Put them into a VPC together so they can communicate
Take the deploy script, have it SSH into the box and run the container update process
Linux updates involve a straightforward process of de-registering, destroying the VM and then starting fresh. Database is a bit more complicated but still doable. It's all easily done in simple scripts that you can tie to github actions if you are so inclined. Docker compose has been the glue that handles the actual launching and restarting of the containers for this sample stack.
When you outgrow this approach, you are big enough that you should have a pretty good idea of where to go now. Since everything is already in containers you haven't been boxed in and can migrate in whatever direction you want.
Why Not Docker
However I'm not thrilled with the current state of Docker as a full product. Even when I've paid for Docker Desktop I found it to be a profoundly underwhelming tool. It's slow, the UI is clunky, there's always an update pending, it's sort of expensive for what people use it for, Windows users seem to hate it. When I've compared Podman vs Docker on servers or my local machines, Podman is faster, seems better designed and just in general as a product is trending in a stronger direction. If I don't like Docker Desktop and prefer Podman Desktop, to me its worth migrating the entire stack over and just dumping Docker as a tool I use. Fewer things to keep track of.
Now the problem is that while podman has sort of a compatibility layer with Docker Compose, it's not a one to one replacement and you want to be careful using it. My testing showed it worked ok for basic examples, but more complex stuff and you started to run into problems. It also seems like work on the project has mostly been abandoned by the core maintainers. You can see it here: https://github.com/containers/podman-compose
I think podman-compose is the right solution for local dev, where you aren't using terribly complex examples and the uptime of the stack matters less. It's hard to replace Compose in this role because its just so straight-forward. As a production deployment tool I would stay away from it. This is important to note because right now the local dev container story often involves running k3 on your laptop. My experience is people loath Kubernetes for local development and will go out of their way to avoid it.
The people I know who are all-in on Podman pushed me towards Quadlet as an alternative which uses systemd to manage the entire stack. That makes a lot of sense to me, because my Linux servers already have systemd and it's already a critical piece of software that (as far as I can remember) works pretty much as expected. So the idea of building on top of that existing framework makes more sense to me than attempting to recreate the somewhat haphazard design of Compose.
Wait I thought this already existed?
Yeah I was also confused. So there was a command, podman-generate-systemd, that I had used previously to run containers with Podman using Systemd. That has been deprecated in favor of Quadlet, which are more powerful and offer more of the Compose functionality, but are also more complex and less magically generated.
So if all you want to do is run a container or pod using Systemd, then you can still usepodman-generate-systemd which in my testing worked fine and did exactly what it says on the box. However if you want to emulate the functionality of Compose with networks and volumes, then you want Quadlet.
What is Quadlet
The name comes from this excellent pun:
What do you get if you squash a Kubernetes kubelet?
A quadlet
Actually laughed out loud at that. Anyway Quadlet is a tool for running Podman containers under Systemd in a declarative way. It has been merged into Podman 4.4 so it now comes in the box with Podman. When you install Podman it registers a systemd-generator that looks for files in the following directories:
You put unit files in the directory you want (creating them if they aren't present which I assume they aren't) with the file extension telling you what you are looking at.
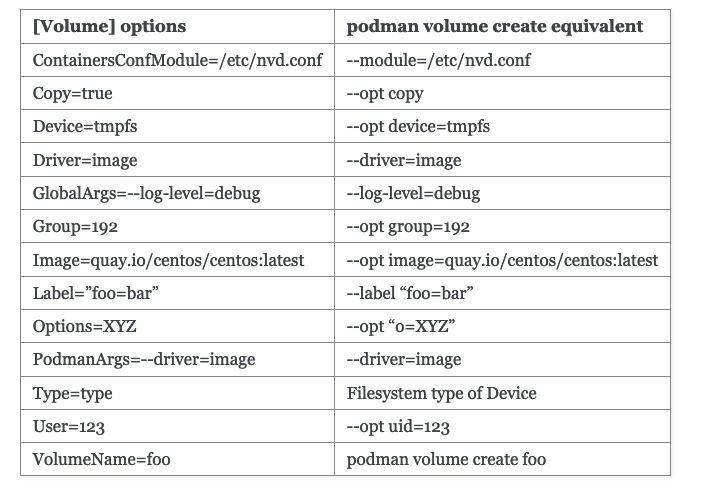
For example, if I wanted a simple volume I would make the following file:
and you should be able to use systemctl status to check all of these running processes. You don't need to run systemctl enable to get them to run on next boot IF you have the [Install] section defined. Also notice that when you are setting the dependencies (requires, after) that it is called name-of-thing.service, not name-of-thing.container or .volume. It threw me off at first but just wanted to call that out.
One thing I want to call out
Containers support AutoUpdate, which means if you just want Podman to pull down the freshest image from your registry that is supported out of the box. It's just AutoUpdate=registry. If you change that to local, Podman will restart when you trigger a new build of that image locally with a deployment. If you need more information about logging into registries with Podman you can find that here.
I find this very helpful for testing environments where I can tell servers to just run podman auto-update and just getting the newest containers. It's also great because it has options to help handle rolling back and failure scenarios, which are rare but can really blow up in your face with containers without k8s. You can see that here.
What if you don't store images somewhere?
So often with smaller apps it doesn't make sense to add a middle layer of build and storage the image in one place and then pull that image vs just building the image on the machine you are deploying to with docker compose up -d --no-deps --build myapp
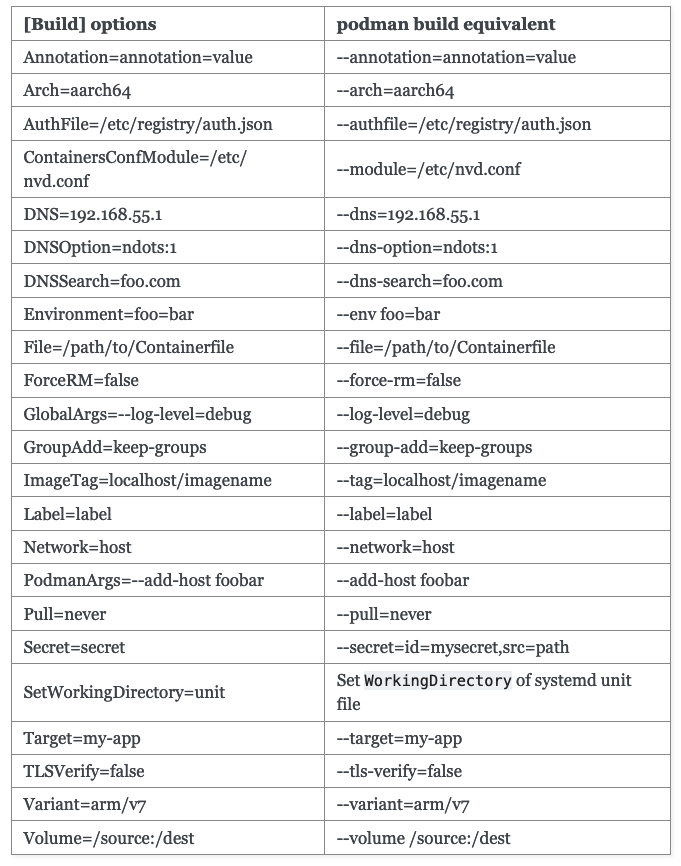
You can do the same thing with Quadlet build files. The unit files are similar to the ones above but with a .build extension and the documentation is pretty simple to figure out how to convert whatever you are looking at to it.
I found this nice for quick testing so I could easily rsync changes to my test box and trigger a fast rebuild with the container layers mostly getting pulled from cache and only my code changes making a difference.
How do secrets work?
So secrets are supported with Quadlets. Effectively they just build on top of podman secret or secrets in Kubernetes. Assuming you don't want to go the Kubernetes route for this purpose, you have a couple of options.
Make a secret from a local file (probably bad idea): podman secret create my_secret ./secret.txt
Make a secret from an environmental variable on the box (better idea): podman secret create --env=true my_secret MYSECRET
Use stdin: printf <secret> | podman secret create my_secret -
Then you can reference these secrets inside of the .container file with the Secret=name-of-podman-secret and then the options. By default these secrets are mounted to run/secrets/secretname as a file inside of the container. You can configure it to be an environmental variable (along with a bunch of other stuff) with the options outlined here.
Rootless
So my examples above were not rootless containers which are best practice. You can get them to work, but the behavior is more complicated and has problems I wanted to call out. You need to use default.target and not multi-user.target and then also it looks like you do need loginctl enable-linger to allow your user to start the containers without that user being logged in.
Also remember that all of the systemctl commands need the --user argument and that you might need to change your sysctl parameters to allow rootless containers to run on privileged ports.
So for rootless networking Podman previously used slirp4netns and now uses pasta. Pasta doesn't do NAT and instead copies the IP address from your main network interface to the container namespace. Main in this case is defined as whatever interface as the default route. This can cause (obvious) problems with inter-container connections since its all the same IP. You need to configure the containers.conf to get around this problem.
Also ping didn't work for me. You can fix that with the solution here.
That sounds like a giant pain in the ass.
Yeah I know. It's not actually the fault of the Podman team. The way rootless containers work is basically they use user_namespaces to emulate the privileges to create containers. Inside of the UserNS they can do things like mount namespaces and networking. Outgoing connections are tricky because vEth pairs cannot be created across UserNS boundaries without root. Inbound relies on port forwarding.
So tools like slirp and pasta are used since they can translate Ethernet packets to unprivileged socket system calls by making a tap interface available in the namespace. However the end result is you need to account for a lot of potential strangeness in the configuration file. I'm confident this will let less fiddly as time goes on.
Podman also has a tutorial on how to get it set up here: https://github.com/containers/podman/blob/main/docs/tutorials/rootless_tutorial.md which did work for me. If you do the work of rootless containers now you have a much easier security story for the rest of your app, so I do think it ultimately pays off even if it is annoying in the beginning.
Impressions
So as a replacement for Docker Compose on servers, I've really liked Quadlet. I find the logging to be easier to figure out since we're just using the standard systemctl commands, checking status is also easier and more straightforward. Getting the rootless containers running took....more time than I expected because I didn't think about how they wouldn't start by default until the user logged back in without the linger work.
It does stink that this is absolutely not a solution for local-dev for most places. I prefer that Podman remains daemonless and instead hooks into the existing functionality of Systemd but for people not running Linux as their local workstations (most people on Earth) you are either going to need to use the Podman Desktop Kubernetes functionality or use the podman-compose and just be aware that it's not something you should use in actual production deployments.
But if you are looking for something that scales well, runs containers and is super easy to manage and keep running, this has been a giant hit for me.
DevOps, like many trendy technology terms, has gone from the peak of optimism to the depths of exhaustion. While many of the fundamental ideas behind the concept have become second-nature for organizations, proving it did in fact have a measurable outcome, the difference between the initial intent and where we ended up is vast. For most organizations this didn't result in a wave of safer, easier to use software but instead encouraged new patterns of work that centralized risk and introduced delays and irritations that didn't exist before. We can move faster than before, but that didn't magically fix all our problems.
The cause of its death was a critical misunderstanding over what was causing software to be hard to write. The belief was by removing barriers to deployment, more software would get deployed and things would be easier and better. Effectively that the issue was that developers and operations teams were being held back by ridiculous process and coordination. In reality these "soft problems" of communication and coordination are much more difficult to solve than the technical problems around pushing more code out into the world more often.
What is DevOps?
DevOps, when it was introduced around 2007, was a pretty radical concept of removing the divisions between people who ran the hardware and people who wrote the software. Organizations still had giant silos between teams, with myself experiencing a lot of that workflow.
Since all computer nerds also love space, it was basically us cosplaying as NASA. Copying a lot of the procedures and ideas from NASA to try and increase the safety around pushing code out into the world. Different organizations would copy and paste different parts, but the basic premise was every release was as close to bug free as time allowed. You were typically shooting for zero exceptions.
When I worked for a legacy company around that time, the flow for releasing software looked as follows.
Development team would cut a release of the server software with a release number in conjunction with the frontend team typically packaged together as a full entity. They would test this locally on their machines, then it would go to dev for QA to test, then finally out to customers once the QA checks were cleared.
Operations teams would receive a playbook of effectively what the software was changing and what to do if it broke. This would include how it was supposed to be installed, if it did anything to the database, it was a whole living document. The idea was the people managing the servers, networking equipment and SANs had no idea what the software did or how to fix it so they needed what were effectively step by step instructions. Sometimes you would even get this as a paper document.
Since these happened often inside of your datacenter, you didn't have unlimited elasticity for growth. So, if possible, you would slowly roll out the update and stop to monitor at intervals. But you couldn't do what people see now as a blue/green deployment because rarely did you have enough excess server capacity to run two versions at the same time for all users. Some orgs did do different datacenters at different times and cut between them (which was considered to be sort of the highest tier of safety).
You'd pick a deployment day, typically middle of the week around 10 AM local time and then would monitor whatever metrics you had to see if the release was successful or not. These were often pretty basic metrics of success, including some real eyebrow raising stuff like "is support getting more tickets" and "are we getting more hits to our uptime website". Effectively "is the load balancer happy" and "are customers actively screaming at us".
You'd finish the deployment and then the on-call team would monitor the progress as you went.
Why Didn't This Work
Part of the issue was this design was very labor-intensive. You needed enough developers coordinating together to put together a release. Then you needed a staffed QA team to actually take that software and ensure, on top of automated testing which was jusssttttt starting to become a thing, that the software actually worked. Finally you needed a technical writer working with the development team to walk through what does a release playbook look like and then finally have the Operations team receive, review the book and then implement the plan.
It was also slow. Features would often be pushed for months even when they were done just because a more important feature had to go out first. Or this update was making major changes to the database and we didn't want to bundle in six things with the one possibly catastrophic change. It's effectively the Agile vs Waterfall design broken out to practical steps.
A lot of the lip service around this time that was given as to why organizations were changing was, frankly, bullshit. The real reason companies were so desperate to change was the following:
Having lots of mandatory technical employees they couldn't easily replace was a bummer
Recruitment was hard and expensive.
Sales couldn't easily inject whatever last-minute deal requirement they had into the release cycle since that was often set it stone.
It provided an amazing opportunity for SaaS vendors to inject themselves into the process by offloading complexity into their stack so they pushed it hard.
The change also emphasized the strengths of cloud platforms at the time when they were starting to gobble market share. You didn't need lots of discipline, just allocate more servers.
Money was (effectively) free so it was better to increase speed regardless of monthly bills.
Developers were understandably frustrated that minor changes could take weeks to get out the door while they were being blamed for customer complaints.
So executives went to a few conferences and someone asked them if they were "doing DevOps" and so we all changed our entire lives so they didn't feel like they weren't part of the cool club.
What Was DevOps?
Often this image is used to sum it up:
In a nutshell, the basic premise was that development teams and operations teams were now one team. QA was fired and replaced with this idea that because you could very quickly deploy new releases and get feedback on those releases, you didn't need a lengthy internal test period where every piece of functionality was retested and determined to still be relevant.
Often this is conflated with the concept of SRE from Google, which I will argue until I die is a giant mistake. SRE is in the same genre but a very different tune, with a much more disciplined and structured approach to this problem. DevOps instead is about the simplification of the stack such that any developer on your team can deploy to production as many times in a day as they wish with only the minimal amounts of control on that deployment to ensure it had a reasonably high chance of working.
In reality DevOps as a practice looks much more like how Facebook operated, with employees committing to production on their first day and relying extensively on real-world signals to determine success or failure vs QA and tightly controlled releases.
In practice it looks like this:
Development makes a branch in git and adds a feature, fix, change, etc.
They open up a PR and then someone else on that team looks at it, sees it passes their internal tests, approves it and then it gets merged into main. This is effectively the only safety step, relying on the reviewer to have perfect knowledge of all systems.
This triggers a webhook to the CI/CD system which starts the build (often of an entire container with this code inside) and then once the container is built, it's pushed to a container registry.
The CD system tells the servers that the new release exists, often through a Kubernetes deployment or pushing a new version of an internal package or using the internal CLI of the cloud providers specific "run a container as a service" platform. It then monitors and tells you about the success or failure of that deployment.
Finally there are release-aware metrics which allow that same team, who is on-call for their application, to see if something has changed since they released it. Is latency up, error count up, etc. This is often just a line in a graph saying this was old and this is new.
Depending on the system, this can either be something where every time the container is deployed it is on brand-new VMs or it is using some system like Kubernetes to deploy "the right number" of containers.
The sales pitch was simple. Everyone can do everything so teams no longer need as many specialized people. Frameworks like Rails made database operations less dangerous, so we don't need a team of DBAs. Hell, use something like Mongo and you never need a DBA!
DevOps combined with Agile ended up with a very different philosophy of programming which had the following conceits:
The User is the Tester
Every System Is Your Specialization
Speed Of Shipping Above All
Catch It In Metrics
Uptime Is Free, SSO Costs Money (free features were premium, expensive availability wasn't charged for)
Logs Are Business Intelligence
What Didn't Work
The first cracks in this model emerged pretty early on. Developers were testing on their local Mac and Windows machines and then deploying code to Linux servers configured from Ansible playbooks and left running for months, sometimes years. Inevitably small differences in the running fleet of production servers emerged, either from package upgrades for security reasons or just from random configuration events. This could be mitigated by frequently rotating the running servers by destroying and rebuilding them as fresh VMs, but in practice this wasn't done as often as it should have been.
Soon you would see things like "it's running fine on box 1,2, 4, 5, but 3 seems to be having problems". It wasn't clear in the DevOps model who exactly was supposed to go figure out what was happening or how. In the previous design someone who worked with Linux for years and with these specific servers would be monitoring the release, but now those team members often wouldn't even know a deployment was happening. Telling someone who is amazing at writing great Javascript to go "find the problem with a Linux box" turned out to be easier said than done.
Quickly feedback from developers started to pile up. They didn't want to have to spend all this time figuring out what Debian package they wanted for this or that dependency. It wasn't what they were interested in doing and also they weren't being rewarded for that work, since they were almost exclusively being measured for promotions by the software they shipped. This left the Operations folks in charge of "smoothing out" this process, which in practice often meant really wasteful practices.
You'd see really strange workflows around this time of doubling the number of production servers you were paying for by the hour during a deployment and then slowly scaling them down, all relying on the same AMI (server image) to ensure some baseline level of consistency. However since any update to the AMI required a full dev-stage-prod check, things like security upgrades took a very long time.
Soon you had just a pile of issues that became difficult to assign. Who "owned" platform errors that didn't result in problems for users? When a build worked locally but failed inside of Jenkins, what team needed to check that? The idea of we're all working on the same team broke down when it came to assigning ownership of annoying issues because someone had to own them or they'd just sit there forever untouched.
Enter Containers
DevOps got a real shot in the arm with the popularization of containers, which allowed the movement to progress past its awkward teenage years. Not only did this (mostly) solve the "it worked on my machine" thing but it also allowed for a massive simplification of the Linux server component part. Now servers were effectively dumb boxes running containers, either on their own with Docker compose or as part of a fleet with Kubernetes/ECS/App Engine/Nomad/whatever new thing that has been invented in the last two weeks.
Combined with you could move almost everything that might previous be a networking team problem or a SAN problem to configuration inside of the cloud provider through tools like Terraform and you saw a real flattening of the skill curve. This greatly reduced the expertise required to operate these platforms and allowed for more automation. Soon you started to see what we now recognize as the current standard for development which is "I push out a bajillion changes a day to production".
What Containers Didn't Fix
So there's a lot of other shit in that DevOps model we haven't talked about.
So far teams had improved the "build, test and deploy" parts. However operating the crap was still very hard. Observability was really really hard and expensive. Discoverability was actually harder than ever because stuff was constantly changing beneath your feet and finally the Planning part immediately collapsed into the ocean because now teams could do whatever they wanted all the time.
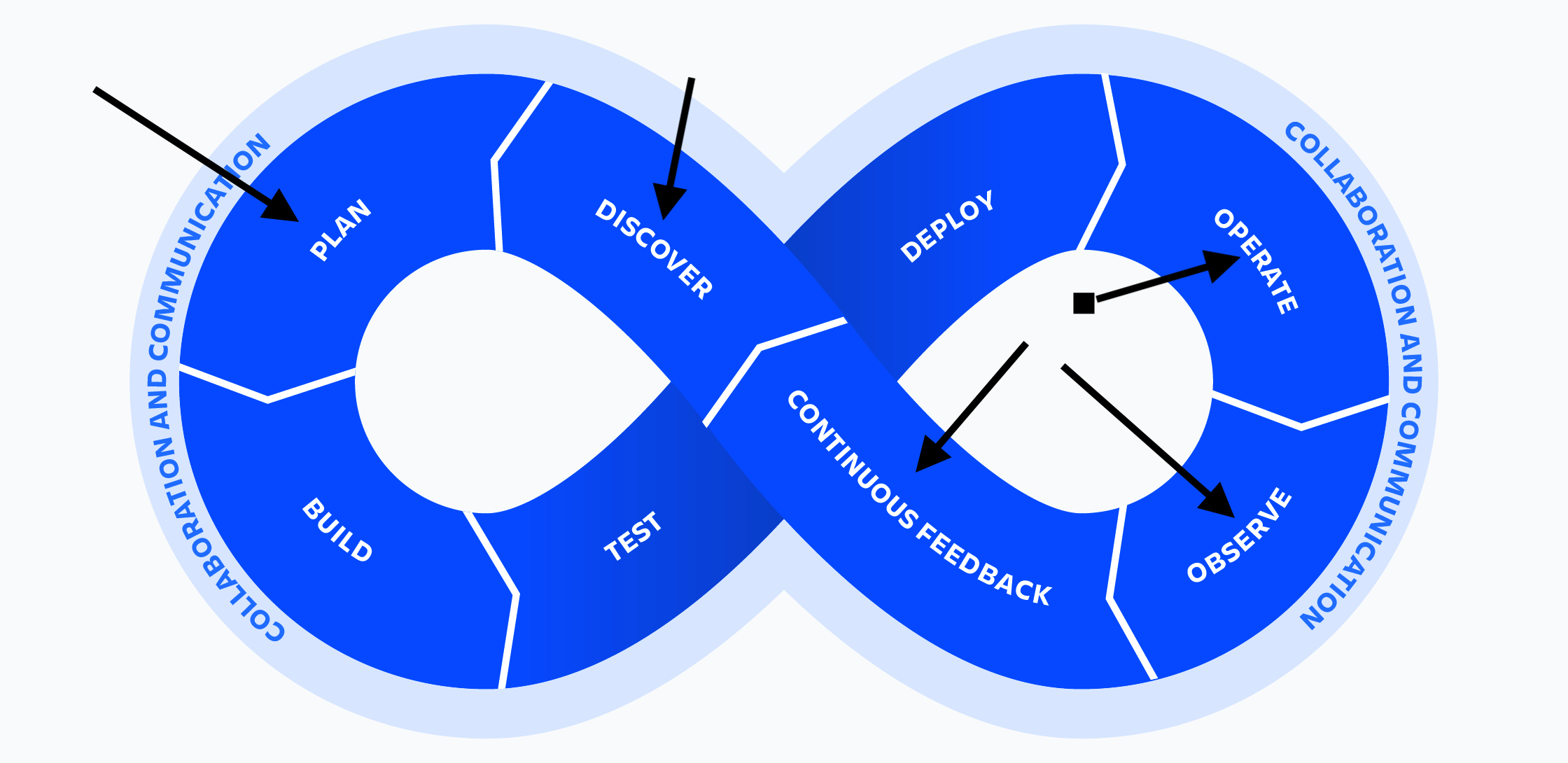
Operate
This meant someone going through and doing all the boring stuff. Upgrading Kubernetes, upgrading the host operating system, making firewall rules, setting up service meshes, enforcing network policies, running the bastion host, configuring the SSH keys, etc. What organizations quickly discovered was that this stuff was very time consuming to do and often required more specialization than the roles they had previously gotten rid of.
Before you needed a DBA, a sysadmin, a network engineer and some general Operations folks. Now you needed someone who not only understood databases but understood your specific cloud providers version of that database. You still needed someone with the sysadmin skills, but in addition they needed to be experts in your cloud platform in order to ensure you weren't exposing your database to the internet. Networking was still critical but now it all existed at a level outside of your control, meaning weird issues would sometimes have to get explained as "well that sometimes happens".
Often teams would delay maintenance tasks out of a fear of breaking something like k8s or their hosted database, but that resulted in delaying the pain and making their lives more difficult. This was the era where every startup I interviewed with basically just wanted someone to update all the stuff in their stack "safely". Every system was well past EOL and nobody knew how to Jenga it all together.
Observe
As applications shipped more often, knowing they worked became more important so you could roll back if it blew up in your face. However replacing simple uptime checks with detailed traces, metrics and logs was hard. These technologies are specialized and require detailed understanding of what they do and how they work. A syslog centralized box lasts to a point and then it doesn't. Prometheus scales to x amount of metrics and then no longer works on a single box. You needed someone who had a detailed understanding of how metrics, logs and traces worked and how to work with development teams in getting them sending the correct signal to the right places at the right amount of fidelity.
Or you could pay a SaaS a shocking amount to do it for you. The rise of companies like Datadog and the eye-watering bills that followed was proof that they understood how important what they were providing was. You quickly saw Observability bills exceed CPU and networking costs for organizations as one team would misconfigure their application logs and suddenly you have blown through your monthly quota in a week.
Developers were being expected to monitor with detailed precision what was happening with their applications without a full understanding of what they were seeing. How many metrics and logs were being dropped on the floor or sampled away, how did the platform work in displaying these logs to them, how do you write an query for terabytes of logs so that you can surface what you need quickly, all of this was being passed around in Confluence pages being written by desperate developers who were learning as they were getting paged at 2AM how all this shit works together.
Continuous Feedback
This to me is the same problem as Observe. It's about whether your deployment worked or not and whether you had signal from internal tests if it was likely to work. It's also about feedback from the team on what in this process worked and what didn't, but because nobody ever did anything with that internal feedback we can just throw that one directly in the trash.
I guess in theory this would be retros where we all complain about the same six things every sprint and then continue with our lives. I'm not an Agile Karate Master so you'll need to talk to the experts.
Discover
A big pitch of combining these teams was the idea of more knowledge sharing. Development teams and Operation teams would be able to cross-share more about what things did and how they worked. Again it's an interesting idea and there was some improvement to discoverability, but in practice that isn't how the incentives were aligned.
Developers weren't rewarded for discovering more about how the platform operated and Operations didn't have any incentive to sit down and figure out how the frontend was built. It's not a lack of intellectual curiosity by either party, just the finite amount of time we all have before we die and what we get rewarded for doing. Being surprised that this didn't work is like being surprised a mouse didn't go down the tunnel with no cheese just for the experience.
In practice I "discovered" that if NPM was down nothing worked and the frontend team "discovered" that troubleshooting Kubernetes was a bit like Warhammer 40k Adeptus Mechanicus waving incense in front of machines they didn't understand in the hopes that it would make the problem go away.
Try restarting the Holy Deployment
Plan
Maybe more than anything else, this lack of centralization impacted planning. Since teams weren't syncing on a regular basis anymore, things could continue in crazy directions unchecked. In theory PMs were syncing with each other to try and ensure there were railroad tracks in front of the train before it plowed into the ground at 100 MPH, but that was a lot to put on a small cadre of people.
We see this especially in large orgs with microservices where it is easier to write a new microservice to do something rather than figure out which existing microservice does the thing you are trying to do. This model was sustainable when money was free and cloud budgets were unlimited, but once that gravy train crashed into the mountain of "businesses need to be profitable and pay taxes" that stopped making sense.
The Part Where We All Gave Up
A lot of orgs solved the problems above by simply throwing bodies into the mix. More developers meant it was possible for teams to have someone (anyone) learn more about the systems and how to fix them. Adding more levels of PMs and overall planning staff meant even with the frantic pace of change it was...more possible to keep an eye on what was happening. While cloud bills continued to go unbounded, for the most part these services worked and allowed people to do the things they wanted to do.
Then layoffs started and budget cuts. Suddenly it wasn't acceptable to spend unlimited money with your logging platform and your cloud provider as well as having a full team. Almost instantly I saw the shift as organizations started talking about "going back to basics". Among this was a hard turn in the narrative around Kubernetes where it went from an amazing technology that lets you grow to Google-scale to a weight around an organizations neck nobody understood.
Platform Engineering
Since there are no new ideas, just new terms, a successor to the throne has emerged. No longer are development teams expected to understand and troubleshoot the platforms that run their software, instead the idea is that the entire process is completely abstracted away from them. They provide the container and that is the end of the relationship.
From a certain perspective this makes more sense since it places the ownership for the operation of the platform with the people who should have owned it from the beginning. It also removes some of the ambiguity over what is whose problem. The development teams are still on-call for their specific application errors, but platform teams are allowed to enforce more global rules.
Well at least in theory. In practice this is another expansion of roles. You went from needing to be a Linux sysadmin to being a cloud-certified Linux sysadmin to being a Kubernetes-certified multicloud Linux sysadmin to finally being an application developer who can create a useful webUI for deploying applications on top of a multicloud stack that runs on Kubernetes in multiple regions with perfect uptime and observability that doesn't blow the budget. I guess at some point between learning the difference between AWS and GCP we were all supposed to go out and learn how to make useful websites.
This division of labor makes no sense but at least it's something I guess. Feels like somehow Developers got stuck with a lot more work and Operation teams now need to learn 600 technologies a week. Surprisingly tech executives didn't get any additional work with this system. I'm sure the next reorg they'll chip in more.
Conclusion
We are now seeing a massive contraction of the Infrastructure space. Teams are increasingly looking for simple, less platform specific tooling. In my own personal circles it feels like a real return to basics, as small and medium organizations abandon technology like Kubernetes and adopt much more simple and easy-to-troubleshoot workflows like "a bash script that pulls a new container".
In some respects it's a positive change, as organizations stop pretending they needed a "global scale" and can focus on actually servicing the users and developers they have. In reality a lot of this technology was adopted by organizations who weren't ready for it and didn't have a great plan for how to use it.
However Platform Engineering is not a magical solution to the problem. It is instead another fabrication of an industry desperate to show monthly growth in cloud providers who know teams lack the expertise to create the kinds of tooling described by such practices. In reality organizations need to be more brutally honest about what they actually need vs what bullshit they've been led to believe they need.
My hope is that we keep the gains from the DevOps approach and focus on simplification and stability over rapid transformation in the Infrastructure space. I think we desperately need a return to basics ideology that encourages teams to stop designing with the expectation that endless growth is the only possible outcome of every product launch.
I was recently working on a new side project in Python with Kubernetes and I needed to inject a bunch of secrets. The problem with secret management in Kubernetes is you end up needing to set up a lot of it yourself and its time consuming. When I'm working on a new idea, I typically don't want to waste a bunch of hours setting up "the right way" to do something that isn't related to the core of the idea I'm trying out.
For the record, the right way to do secrets in Kubernetes is the following:
Turn on encryption at rest for ETCD
Carefully set up RBAC inside of Kubernetes to ensure the right users and service accounts can access the secrets
Give up on trying to do that and end up setting up Vault or paying your cloud provider for their Secret Management tool
However especially when you are trying ideas out, I wanted something more idiot proof that didn't require any setup. So I wrote something simple with Python Fernet encryption that I thought might be useful to someone else out there.
So the script works in a pretty straight forward way. It reads the .env file you generate as outlined in the README with secrets in the following format:
Make a .env file with the following parameters:
KEY=Make a fernet key: https://fernetkeygen.com/
CLUSTER_NAME=name_of_cluster_you_want_to_use
SECRET-TEST-1=9e68b558-9f6a-4f06-8233-f0af0a1e5b42
SECRET-TEST-2=a004ce4c-f22d-46a1-ad39-f9c2a0a31619
The KEY is the secret key and the CLUSTER_NAME tells the Kubernetes library what kubeconfig target you want to use. Then the tool finds anything with the word SECRET in the .env file and encrypts it, then writes it to the .csv file.
The .csv file looks like the following:
I really like to keep some sort of record of what secrets are injected into the cluster outside of the cluster just so you can keep track of the encrypted values. Then the script checks the namespace you selected to see if there are secrets with that name already and, if not, injects it for you.
Some quick notes about the script:
Secret names in Kubernetes need a specific format for the name. Lower case with words separated by - or . The script will take the uppercase in the .env and convert it into a lowercase. Just be aware it is doing that.
It does base64 encode the secret before it uploads it, so be aware that your application will need to decode it when it loads the secret.
Now the only secret you need to worry about is the Fernet secret that you can load into the application in a secure way. I find this is much easier to mentally keep track of than trying to build an infinitely scalable secret solution. Plus its cheaper since many secret managers charge per secret.
The secrets are immutable which means they are lightweight on the k8s API and fast. Just be aware you'll need to delete the secrets if you need to replace them. I prefer this approach because I'd rather store more things as encrypted secrets and not worry about load.
It is easy to specify which namespace you intend to load the secrets into and I recommend using a different Fernet secret per application.
Mounting the secret works like it always does in k8s
Inside of your application, you need to load the Fernet secret and decrypt the secrets. With Python that is pretty simple.
decrypt = fernet.decrypt(token)
Q+A
Why not SOPS? This is easier and also handles the process of making the API call to your k8s cluster to make the secret.
Is Fernet secure? As far as I can tell it's secure enough. Let me know if I'm wrong.
Would you make a CLI for this? If people actually use this thing and get value out of it, I would be more than happy to make it a CLI. I'd probably rewrite it in Golang if I did that, so if people ask it'll take me a bit of time to do it.
Imagine your job was to clean a giant office building. You go from floor to floor, opening doors, collecting trash, getting a vacuum out of the cleaning closet and putting it back. It's a normal job and part of that job is someone gives you a key. The key opens every door everywhere. Everyone understands the key is powerful, but they also understand you need to do your job.
Then your management hears about someone stealing janitor keys. So they take away your universal key and they say "you need to tell Suzie, our security engineer, which keys you need at which time". But the keys don't just unlock one door, some unlock a lot of doors and some desk drawers, some open the vault (imagine this is the Die Hard building), some don't open any doors but instead turn on the coffee machine. Obviously the keys have titles, but the titles mean nothing. Do you need the "executive_floor/admin" key or the "executive_floor/viewer" key?
But you are a good employee and understand that security is a part of the job. So you dutifully request the keys you think you need, try to do your job, open a new ticket when the key doesn't open a door you want, try it again, it still doesn't open the door you want so then there's another key. Soon your keyring is massive, just a clanging sound as you walk down the hallway. It mostly works, but a lot of the keys open stuff you don't need, which makes you think maybe this entire thing was pointless.
The company is growing and we need new janitors, but they don't want to give all the new janitors your key ring. So they roll out a new system which says "now the keys can only open doors that we have written down that this key can open, even if it says "executive_floor/admin". The problem is people move offices all the time, so even if the list of what doors that key opened was true when it was issued, it's not true tomorrow. The Security team and HR share a list, but the list sometimes drifts or maybe someone moves offices without telling the right people.
Soon nobody is really 100% sure what you can or cannot open, including you. Sure someone can audit it and figure it out, but the risk of removing access means you cannot do your job and the office doesn't get cleaned. So practically speaking the longer someone works as a janitor the more doors they can open until eventually they have the same level of access as your original master key even if that wasn't the intent.
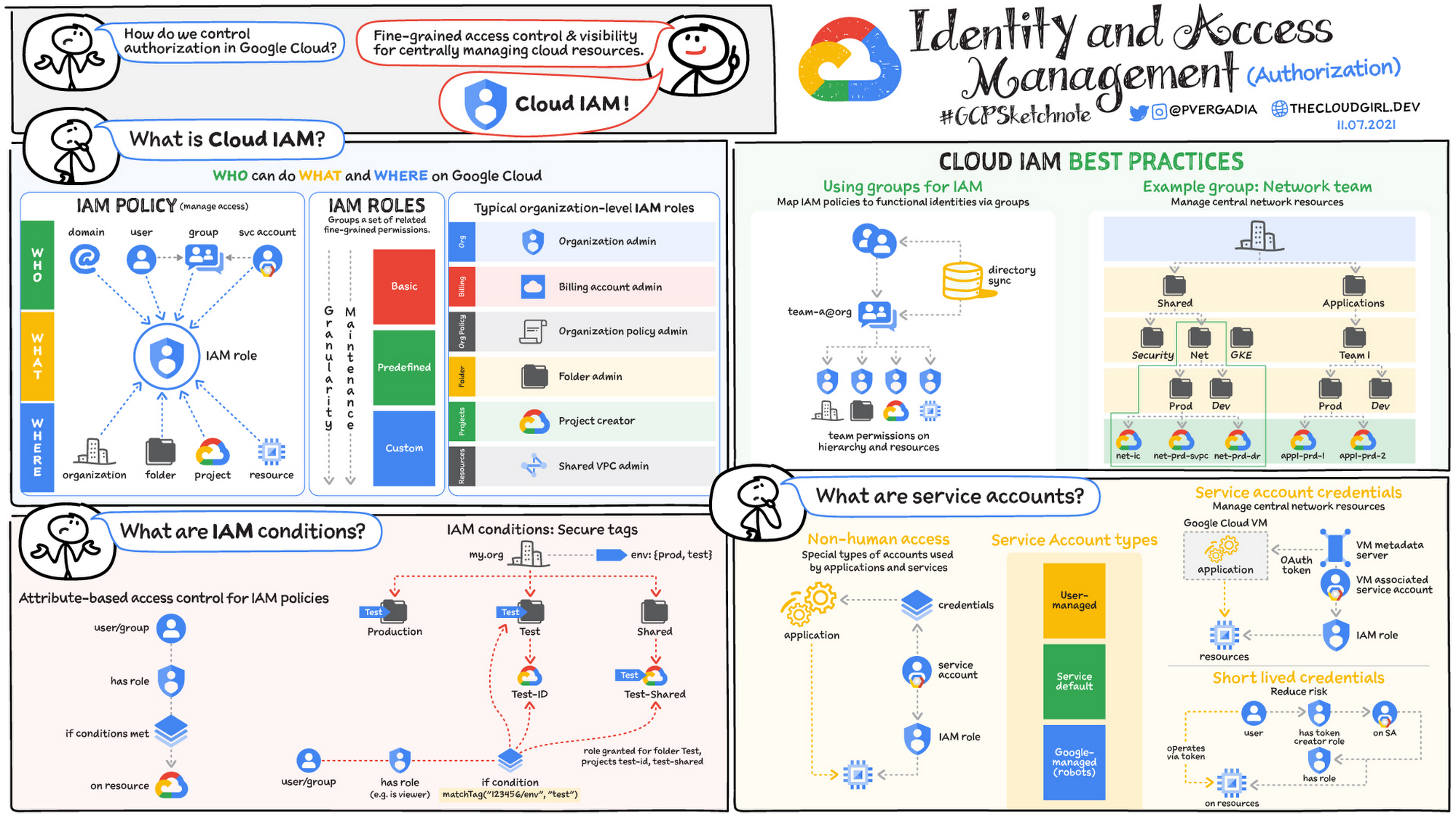
That's IAM (Identity and access management) in cloud providers today.
Stare Into Madness
AWS IAM Approval FlowGCP IAM Approval Flow
Honestly I don't even know why I'm complaining. Of course it's entirely reasonable to expect anyone working in a cloud environment to understand the dozen+ ways that they may or may not have access to a particular resource. Maybe they have permissions at a folder level, or an org level, but that permission is gated by specific resources.
Maybe they don't even have access but the tool they're interacting with the resource with has permission to do it, so they can do it but only as long as they are SSH'd into host01, not if they try to do it through some cloud shell. Possibly they had access to it before, but now they don't since they moved teams. Perhaps the members of this team were previously part of some existing group but now new employees aren't added to that group so some parts of the team can access X but others cannot. Or they actually have the correct permissions to the resource but the resource is located in another account and they don't have the right permission to traverse the networking link between the two VPCs.
Meanwhile someone is staring at these flowcharts trying to figure out what in hell is even happening here. As someone who has had to do this multiple times in my life, let me tell you the real-world workflow that ends up happening.
Developer wants to launch a new service using new cloud products. They put in a ticket for me to give them access to the correct "roles" to do this.
I need to look at two elements of it, both what are the permissions the person needs in order to see if the thing is working and then the permissions the service needs in order to complete the task it is trying to complete.
So I go through my giant list of roles and try to cobble together something that I think based on the names will do what I want. Do you feel like a roles/datastore.viewer or more of a roles/datastore.keyVisualizerViewer? To run backups is roles/datastore.backupsAdmin sufficient or do I need to add roles/datastore.backupSchedulesAdmin in there as well?
They try it and it doesn't work. Reopen the ticket with "I still get authorizationerror:foo". I switch that role with a different role, try it again. Run it through the simulator, it seems to work, but they report a new different error because actually in order to use service A you need to also have a role in service B. Go into bathroom, scream into the void and return to your terminal.
We end up cobbling together a custom role that includes all the permissions that this application needs and the remaining 90% of permissions are something it will never ever use but will just sit there as a possible security hole.
Because /* permissions are the work of Satan, I need to scope it to specific instances of that resource and just hope nobody ever adds a SQS queue without....checking the permissions I guess. In theory we should catch it in the non-prod environments but there's always the chance that someone messes up something at a higher level of permissions that does something in non-prod and doesn't exist in prod so we'll just kinda cross our fingers there.
GCP Makes It Worse
So that's effectively the AWS story, which is terrible but at least it's possible to cobble together something that works and you can audit. Google looked at this and said "what if we could express how much we hate Infrastructure teams as a service?" Expensive coffee robots were engaged, colorful furniture was sat on and the brightest minds of our generation came up with a system so punishing you'd think you did something to offend them personally.
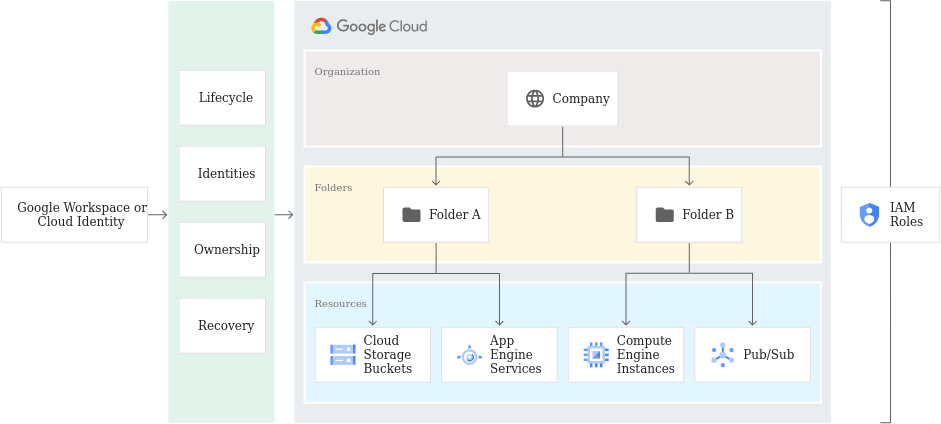
Google looked at AWS and said "this is a tire fire" as corporations put non-prod and prod environments in the same accounts and then tried to divide them by conditionals. So they came up with a folder structure:
The problem is that this design encourages unsafe practices by promoting "groups should be set at the folder level with one of the default basic roles". It makes sense logically at first that you are a viewer, editor or owner. But as GCP adds more services this model breaks down quickly because each one of these encompasses thousands upon thousands of permissions. So additional IAM predefined roles were layered on.
People were encouraged to move away from the basic roles and towards the predefined roles. There are ServiceAgent roles that were designated for service accounts, aka the permissions you actual application has and then everything else. Then there are 1687 other roles for you to pick from to assign to your groups of users.
The problem is none of this is actually best practice. Even when assigning users "small roles", we're still not following the principal of least privilege. Also the roles don't remain static. As new services come online permissions are added to roles.
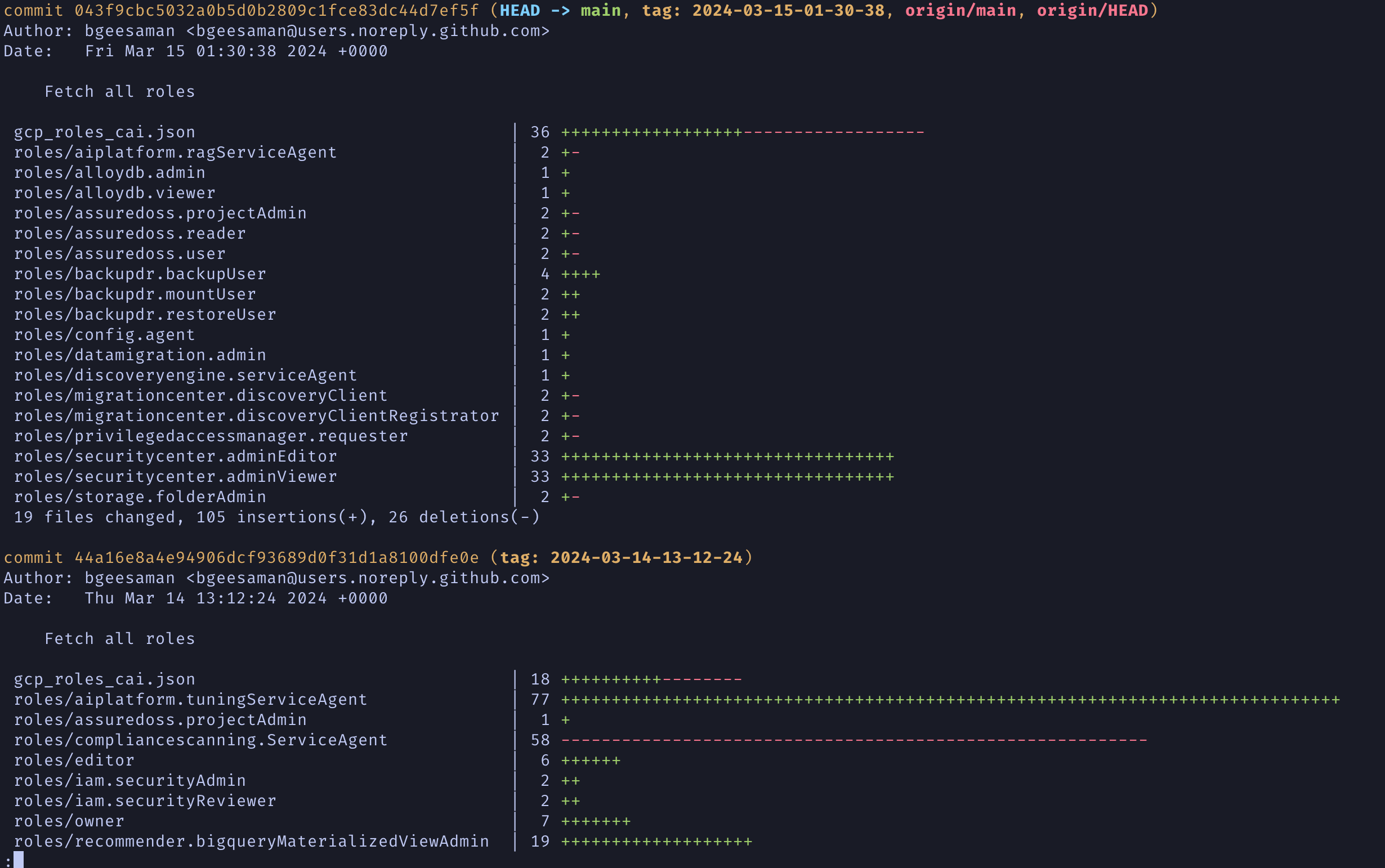
The above is an automated process that pulls down all the roles from the gcloud CLI tool and updates them for latest. It is a constant state of flux with roles with daily changes. It gets even more complicated though.
You also need to check the launch stage of a role.
Custom roles include a launch stage as part of the role's metadata. The most common launch stages for custom roles are ALPHA, BETA, and GA. These launch stages are informational; they help you keep track of whether each role is ready for widespread use. Another common launch stage is DISABLED. This launch stage lets you disable a custom role.
We recommend that you use launch stages to convey the following information about the role:
EAP or ALPHA: The role is still being developed or tested, or it includes permissions for Google Cloud services or features that are not yet public. It is not ready for widespread use. BETA: The role has been tested on a limited basis, or it includes permissions for Google Cloud services or features that are not generally available. GA: The role has been widely tested, and all of its permissions are for Google Cloud services or features that are generally available. DEPRECATED: The role is no longer in use.
Who Cares?
Why would anyone care if Google is constantly changing roles? Well it matters because with GCP to make a custom role, you cannot combine predefined roles. Instead you need to go down to the permission level to list out all of the things those roles can do, then feed that list of permissions into the definition of your custom role and push that up to GCP.
In order to follow best practices this is what you have to do. Otherwise you will always be left with users that have a ton of unused permissions along with the fear of a security breach allowing someone to execute commands in your GCP account through an applications service account that cause way more damage than the actual application justifies.
So you get to build automated tooling which either queries the predefined roles for change over time and roll those into your custom roles so that you can assign a user or group one specific role that lets them do everything they need. Or you can assign these same folks multiple of the 1600+ predefined roles, accept that they have permissions they don't need and also just internalize that day to day you don't know how much the scope of those permissions have changed.
The Obvious Solution
Why am I ranting about this? Because the solution is so blindly obvious I don't understand why we're not already doing it. It's a solution I've had to build, myself, multiple times and at this point am furious that this keeps being my responsibility as I funnel hundreds of thousands of dollars to cloud providers.
What is this obvious solution? You, an application developer, need to launch a new service. I give you a service account that lets you do almost everything inside of that account along with a viewer account for your user that lets you go into the web console and see everything. You churn away happily, writing code that uses all those new great services. Meanwhile, we're tracking all the permissions your application and you are using.
At some time interval, 30 or 90 or whatever days, my tool looks at the permissions your application has used over the last 90 days and says "remove the global permissions and scope it to these". I don't need to ask you what you need, because I can see it. In the same vein I do the same thing with your user or group permissions. You don't need viewer everywhere because I can see what you've looked at.
Both GCP and AWS support this and have all this functionality baked in. GCP has the role recommendations which tracks exactly what I'm talking about and recommends lowering the role. AWS tracks the exact same information and can be used to do the exact same thing.
What if the user needs different permissions in a hurry?
This is not actually that hard to account for and again is something I and countless others have been forced to make over and over. You can issue expiring permissions in both situations where a user can request a role be temporarily granted to them and then it disappears in 4 hours. I've seen every version of these, from Slack bots to websites, but they're all the same thing. If user is in X group they're allowed to request Y temporary permissions. OR if the user is on-call as determined with an API call to the on-call provider they get more powers. Either design works fine.
That seems like a giant security hole
Compared to what? Team A guessing what Team B needs even though they don't ever do the work that Team B does? Some security team receiving a request for permissions and trying to figure out if the request "makes sense" or not? At least this approach is based on actual data and not throwing darts at a list of IAM roles and seeing what "feels right".
Conclusion
IAM started out as an easy idea that as more and more services were launched, started to become nightmarish to organize. It's too hard to do the right thing now and it's even harder to do the right thing in GCP compared to AWS. The solution is not complicated. We have all the tools, all the data, we understand how they fit together. We just need one of the providers to be brave enough to say "obviously we messed up and this legacy system you all built your access control on is bad and broken". It'll be horrible, we'll all grumble and moan but in the end it'll be a better world for us all.
If I were told to go off and make a hosted Terraform product, I would probably end up with a list of features that looked something like the following:
Extremely reliable state tracking
Assistance with upgrading between versions of Terraform and providers and letting users know when it looked safe to upgrade and when there might be problems between versions
Consistent running of Terraform with a fresh container image each time, providers and versions cached on the host VM so the experience is as fast as possible
As many linting, formatting and HCL optimizations I can offer, configurable on and off
Investing as much engineering work as I can afford in providing users an experience where, unlike with the free Terraform, if a plan succeeds on Terraform Cloud, the Apply will succeed
Assisting with Workspace creation. Since we want to keep the number of resources low, seeing if we can leverage machine learning to say "we think you should group these resources together as their own workspace" and showing you how to do that
Figure out some way for organizations to interact with the Terraform resources other than just running the Terraform CLI, so users can create richer experiences for their teams through easy automation that feeds back into the global source of truth that is my incredibly reliable state tracking
Try to do whatever I can to encourage more resources in my cloud. Unlimited storage, lots of workspaces, helping people set up workspaces. The more stuff in there the more valuable it is for the org to use (and also more logistically challenging for them to cancel)
This is me would be a product I would feel confident charging a lot of money for. Terraform Cloud is not that product. It has some of these features locked behind the most expensive tiers, but not enough of them to justify the price.
I've written about my feelings around the Terraform license change before. I won't bore you with that again. However since now the safest way to use Terraform is to pay Hashicorp, what does that look like? As someone who has used Terraform for years and Terraform Cloud almost daily for a year, it's a profoundly underwhelming experience.
Currently it is a little-loved product with lots of errors and sharp edges. This is as v0.1 of a version of this as I could imagine, except the pace of development has been glacial. Terraform Cloud is a "good enough" platform that seems to understand that if you could do better, you would. Like a diner at 2 AM on the side of the highway, it's primary selling point is the fact that it is there. That and the license terms you will need to accept soon.
Terraform Cloud - Basic Walkthrough
At a high level Terraform Cloud allows organizations to centralize their Projects and Workspaces and store that state with Hashicorp. It also gives you access to a Registry for you to host your own privacy Terraform modules and use them in your workspaces. The top level options look as follows:
That's it!
You may be wondering "What does Usage do?" I have no idea, as the web UI has never worked for me even though I appear to have all the permissions one could have. I have seen the following since getting my account:
I'm not sure what wasn't found.
I'm not sure what access I lack or if the page was intended to work. It's very mysterious in that way.
There is Explorer, which lets you basically see "what versions of things do I use across the different repos". You can't do anything with that information, like I can't say "alright well upgrade these two to the version that everyone else uses". It's also a beta feature and not one that existed when I first started using the platform.
Finally there are the Workspaces, where you spend 99% of your time.
You get some ok stats here. Up in the top left you see "Needs Attention", "Errors", "Running", "Hold" and then "Applied." Even though you may have many Workspaces, you cannot change how many you see here. 20 is the correct number I guess.
Creating a Workspace
Workspaces are either based on a repo, CLI driven or you call the API. You tell it what VCS, what repo, if you want to use the root of the repo or a sub-directory (which is good because soon you'll have too many resources for one workspace for everything). You tell it Auto Apply (which is checked by default) or Manual and when to trigger a run (whenever a change, whenever specific files in a path change or whenever you push a tag). That's it.
You can see all the runs, what their status is and basically what resources have changed or will change. Any plan that you run from your laptop also show up here. Now you don't need to manage your runs here, you can still do local, but then there is absolutely no reason to use this product. Almost all of the features rely on your runs being handled by Hashicorp here inside of a Workspace.
Workspace flow
Workspaces show you when the run was, how long the plan took, what resources are associated with this (10 resources at a time even though you might have thousands. Details links you to the last run, there are tags and run triggers. Run triggers allow you to link workspaces together, so this workspace would dependent on the output of another workspace.
The settings are as follows:
Runs is pretty straight forward. States allow you to inspect the state changes directly. So you can see the full JSON of a resource and roll back to this specific state version. This can be nice for reviewing what specifically changed on each resource, but in my experience you don't get much over looking at the actual code. But if you are in a situation where something has suddenly broken and you need a fast way of saying "what was added and what was removed", this is where you would go.
NOTE: BE SUPER CAREFUL WITH THIS
The state inspector has the potential to show TONS of sensitive data. It's all the data in Terraform in the raw form. Just be aware it exists when you start using the service and take a look to ensure there isn't anything you didn't want there.
Variables are variables and the settings allow you to lock the workspace, apply Sentinel settings, set an SSH key for downloading private modules and finally if you want changes to the VCS to trigger an action here. So for instance, when you merge in a PR you can trigger Terraform Cloud to automatically apply this workspace. Nothing super new here compared to any CI/CD system, but still it is all baked in.
That's it!
No-Code Modules
One selling point I heard a lot about, but haven't actually seen anyone use. The idea is good though, where you write premade modules and push them to your private registry. Then members of your organization can just run them to do things like "stand up a template web application stack". Hashicorp has a tutorial here that I ran though and found it to work pretty much as expected. It isn't anywhere near the level of power that I would want, compared to something like Pulumi, but it is a nice step forward for automating truly constant tasks (like adding domain names to an internal domain or provisioning some SSL certificate for testing).
Dynamic Credentials
You can link Terraform Cloud and Vault, if you use it, so you no longer need to stick long-living credentials inside of the Workspace to access cloud providers. Instead you can leverage Vault to get short-lived credentials that improve the security of the Workspaces. I ran through this and did have problems getting it worked for GCP, but AWS seemed to work well. It requires some setup inside of the actual repository, but it's a nice security improvement vs leaving production credentials in this random web application and hoping you don't mess up the user scoping.
User scoping is controlled primarily through "projects", which basically trickle down to the user level. You make a project, which has workspaces, that have their own variables and then assign that to a team or business unit. That same logic is reflected inside of credentials.
Private Registry
This is one thing Hashicorp nailed. It's very easy to hook up Terraform Cloud to allow your workspaces to access internal modules backed by your private repositories. It supports the same documentation options as public modules, tracks downloads and allows for easy versioning control through git tags. I have nothing but good things to say about this entire thing.
Sharing between organizations is something they lock at the top tier, but this seems like a very niche usecase so I don't consider it to be too big of a problem. However if you are someone looking to produce a private provider or module for your customers to use, I would reach out to Hashicorp and see how they want you to do that.
The primary value for this is just to easily store all of your IaC logic in modules and then rely on the versioning inside of different environments to roll out changes. For instance, we do this for things like upgrading a system. Make the change, publish the new version to the private registry and then slowly roll it out. Then you can monitor the rollout through git grep pretty easily.
Pricing
$0.00014 per hour per resource. So a lot of money when you think "every IAM custom role, every DNS record, every SSL certificate, every single thing in your entire organization". You do get a lot of the nice features at this "standard" tier, but I'm kinda shocked they don't unlock all the enterprise features at this price point. No-code provisioning is only available at the higher levels, as well as Drift detection, Continuous validation (checks between runs to see if anything has changed ) as well as Ephemeral workspaces. The last one is a shame, because it looks like a great feature. Set up your workspace to self-destruct at regular intervals so you can nuke development environments. I'd love to use that but alas.
Problems
Oh the problems. So the runners sometimes get "stuck", which seems to usually happen after someone cancels a job in the web UI. You'll run into an issue, try to cancel a job, fix the problem and rerun the runner only to have it get stuck forever. I've sat there and watched it try to load the modules for 45 minutes. There isn't any way I have seen to tell Terraform Cloud "this runner is broken, go get me another one". Sometimes they get stuck for an unknown reason.
Since you need to make all the plans and applies remotely to get any value out of the service, it can also sometimes cause traffic jams in your org. If you work with Terraform a lot, you know you need to run plans pretty regularly. Since you need to wait for a runner every single time, you can end up wasting a lot of time sitting there waiting for another job to finish. Again I'm not sure what triggers you getting another runner. You can self host, but then I'm truly baffled at what value this tool brings.
Even if that was an option for you and you wanted to do it, its locked behind the highest subscription tier. So I can't even say "add a self-hosted runner just for plans" so I could unstick my team. This seems like an obvious add, along with a lot more runner controls so I could see what was happening and how to avoid getting it jammed up.
Conclusion
I feel bad this is so short, but there just isn't anything else to write. This is a super bare-bones tool that does what it says on the box for a lot of money. It doesn't give you a ton of value over Spacelift or or any of the others. I can't recommend it, it doesn't work particularly well and I haven't enjoyed my time with it. Managing it vs using an S3 bucket is an experience I would describe as "marginally better". It's nice that it handles contention across team mates for me, but so do all the others at a lower price.
I cannot think of a single reason to recommend this over Spacelift, which has better pricing, better tooling and seems to have a better runner system except for the license change. Which was clearly the point of the license change. However for those evaluating options, head elsewhere. This thing isn't worth the money.
IP addresses have been in the news a lot lately and not for good reasons. AWS has announced they are charging $.005 per IPv4 address per hour, joining other cloud providers in charging for the luxury of a public IPv4 address. GCP charges $.004, same with Azure and Hetzner charges €0.001/h. Clearly the era of cloud providers going out and purchasing more IPv4 space is coming to an end. As time goes on, the addresses are just more valuable and it makes less sense to give them out for free.
So the writing is on the wall. We need to switch to IPv6. Now I was first told that we were going to need to switch to IPv6 when I was in high school in my first Cisco class and I'm 36 now, to give you some perspective on how long this has been "coming down the pipe". Up to this point I haven't done much at all with IPv6, there has been almost no market demand for those skills and I've never had a job where anybody seemed all that interested in doing it. So I skipped learning about it, which is a shame because it's actually a great advancement in networking.
Now is the second best time to learn though, so I decided to migrate this blog to IPv6 only. We'll stick it behind a CDN to handle the IPv4 traffic, but let's join the cool kids club. What I found was horrifying: almost nothing works out of the box. Major dependencies cease functioning right away and workarounds cannot be described as production ready. The migration process for teams to IPv6 is going to be very rocky, mostly because almost nobody has done the work. We all skipped it for years and now we'll need to pay the price.
Why is IPv6 worth the work?
I'm not gonna do a thing about what is IPv4 vs IPv6. There are plenty of great articles on the internet about that. Let's just quickly recap though "why would anyone want to make the jump to IPv6".
An IPv6 packet header
Address space (obviously)
Smaller number of header fields (8 vs 13 on v4)
Faster processing: No more checksum, so routers don't have to do a recalculation for every packet.
Faster routing: More summary routes and hierarchical routes. (Don't know what that is? No stress. Summary route = combining multiple IPs so you don't need all the addresses, just the general direction based on the first part of the address. Ditto with routes, since IPv6 is globally unique you can have small and efficient backbone routing.)
QoS: Traffic Class and Flow Label fields make QoS easier.
Auto-addressing. This allows IPv6 hosts on a LAN to connect without a router or DHCP server.
You can add IPsec to IPv6 with the Authentication Header and Encapsulating Security Payload.
Finally the biggest one: because IPv6 addresses are free and IPv4 ones are not.
Setting up an IPv6-Only Server
The actual setup process was simple. I provisioned a Debian box and selected "IPv6". Then I got my first surprise. My box didn't get an IPv6 address. I was given a /64 of addresses, which is 18,446,744,073,709,551,616. It is good to know that my small ARM server could scale to run all the network infrastructure for every company I've ever worked for on all public addresses.
Now this sounds wasteful but when you look at how IPv6 works, it really isn't. Since IPv6 is much less "chatty" than IPv4, even if I had 10,000 hosts on this network it doesn't matter. As discussed here it actually makes sense to keep all the IPv6 space, even if at first it comes across as insanely wasteful. So just don't think about how many addresses are getting sent to each device.
Important: resist the urge to optimize address utilization. Talking to more experienced networking folks, this seems to be a common trap people fall into. We've all spent so much time worrying about how much space we have remaining in an IPv4 block and designing around that problem. That issue doesn't exist anymore. A /64 prefix is the smallest you should configure on an interface.
Attempting to stick a smaller prefix, which is something I've heard people try, like a /68 or a /96 can break stateless address auto-configuration. Your mentality should be a /48 per site. That's what the Regional Internet Registries hands out when allocating IPv6. When thinking about network organization, you need to think about the nibble boundary. (I know, it sounds like I'm making shit up now). It's basically a way to make IPv6 easier to read.
Let's say you have 2402:9400:10::/48. You would divide it up as follows if you wanted only /64 for each box as a flat network.
Subnet #
Subnet Address
0
2402:9400:10::/64
1
2402:9400:10:1::/64
2
2402:9400:10:2::/64
3
2402:9400:10:3::/64
4
2402:9400:10:4::/64
5
2402:9400:10:5::/64
A /52 works a similar way.
Subnet #
Subnet Address
0
2402:9400:10::/52
1
2402:9400:10:1000::/52
2
2402:9400:10:2000::/52
3
2402:9400:10:3000::/52
4
2402:9400:10:4000::/52
5
2402:9400:10:5000::/52
You can still at a glance know which subnet you are looking at.
Alright I've got my box ready to go. Let's try to set it up like a normal server.
Problem 1 - I can't SSH in
This was a predictable problem. Neither my work or home ISP supports IPv6. So it's great that I have this box set up, but now I can't really do anything with it. Fine, I attach an IPv4 address for now, SSH in and I'll set up cloudflared to run a tunnel. Presumably they'll handle the conversion on their side.
Except that isn't how Cloudflare rolls. Imagine my surprise when the tunnel collapses when I remove the IPv4 address. By default the cloudflared utility assumes IPv4 and you need to go in and edit the systemd service file to add: --edge-ip-version 6. After this, the tunnel is up and I'm able to SSH in.
Problem 2 - I can't use GitHub
Alright so I'm on the box. Now it's time to start setting up stuff. I run my server setup script and it immediately fails. It's trying to access the installation script for hishtory, a great shell history utility I use on all my personal stuff. It's trying to pull the install file from GitHub and failing. "Certainly that can't be right. GitHub must support IPv6?"
Nope. Alright fine, seems REALLY bad that the service the entire internet uses to release software doesn't work with IPv6, but you know Microsoft is broke and also only cares about fake AI now, so whatever. I ended up using the TransIP Github Proxy which worked fine. Now I have access to Github. But then Python fails with urllib.error.URLError: <urlopen error [Errno 101] Network is unreachable>. Alright I give up on this. My guess is the version of Python 3 in Debian doesn't like IPv6, but I'm not in the mood to troubleshoot it right now.
Problem 3 - Can't set up Datadog
Let's do something more basic. Certainly I can set up Datadog to keep an eye on this box. I don't need a lot of metrics, just a few historical load numbers. Go to Datadog, log in and start to walk through the process. Immediately collapses. The simple setup has you run curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh. Now S3 supports IPv6, so what the fuck?
curl -v https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh
* Trying [64:ff9b::34d9:8430]:443...
* Trying 52.216.133.245:443...
* Immediate connect fail for 52.216.133.245: Network is unreachable
* Trying 54.231.138.48:443...
* Immediate connect fail for 54.231.138.48: Network is unreachable
* Trying 52.217.96.222:443...
* Immediate connect fail for 52.217.96.222: Network is unreachable
* Trying 52.216.152.62:443...
* Immediate connect fail for 52.216.152.62: Network is unreachable
* Trying 54.231.229.16:443...
* Immediate connect fail for 54.231.229.16: Network is unreachable
* Trying 52.216.210.200:443...
* Immediate connect fail for 52.216.210.200: Network is unreachable
* Trying 52.217.89.94:443...
* Immediate connect fail for 52.217.89.94: Network is unreachable
* Trying 52.216.205.173:443...
* Immediate connect fail for 52.216.205.173: Network is unreachable
It's not S3 or the box, because I can connect to the test S3 bucket AWS provides just fine.
0% [Connecting to apt.datadoghq.com (18.66.192.22)]
Goddamnit. Alright Datadog is out. It's at this point I realize the experiment of trying to go IPv6 only isn't going to work. Almost nothing seems to work right without proxies and hacks. I'll try to stick as much as I can on IPv6 but going exclusive isn't an option at this point.
NAT64
So in order to access IPv4 resources from IPv6 you need to go through a NAT64 service. I ended up using this one: https://nat64.net/. Immediately all my problems stopped and I was able to access resources normally. I am a little nervous about relying exclusively on what appears to be a hobby project for accessing critical internet resources, but since nobody seems to care upstream of me about IPv6 I don't think I have a lot of choice.
I am surprised there aren't more of these. This is the best list I was able to find:
Most of them seem to be gone now. Dresel's link doesn't work, Trex in my testing had problems, August Internet is gone, most of the Go6lab test devices are down, Tuxis worked but they launched the service in 2019 and seem to have no further interaction with it. Basically Kasper Dupont seems to be the only person on the internet with any sort of widespread interest in allowing IPv6 to actually work. Props to you Kasper.
Basically one person props up this entire part of the internet.
Kasper Dupont
So I was curious about Kasper and emailed him to ask a few questions. You can see that back and forth below.
Me: I found the Public NAT64 service super useful in the transition but would love to know a little bit more about why you do it.
Kasper: I do it primarily because I want to push IPv6 forward. For a few years I had the opportunity to have a native IPv6-only network at home with DNS64+NAT64, and I found that to be a pleasant experience which I wanted to give more people a chance to experience.
When I brought up the first NAT64 gateway it was just a proof of concept of a NAT64 extension I wanted to push. The NAT64 service took off, the extension - not so much.
A few months ago I finally got native IPv6 at my current home, so now I can use my own service in a fashion which much more resembles how my target users would use it.
Me: You seem to be one of the few remaining free public services like this on the internet and would love to know a bit more about what motivated you to do it, how much it costs to run, anything you would feel comfortable sharing.
Kasper: For my personal products I have a total of 7 VMs across different hosting providers. Some of them I purchase from Hetzner at 4.51 Euro per month: https://hetzner.cloud/?ref=fFum6YUDlpJz
The other VMs are a bit more expensive, but not a lot.
Out of those VMs the 4 are used for the NAT64 service and the others are used for other IPv6 transition related services. For example I also run this service on a single VM: http://v4-frontend.netiter.com/
I hope to eventually make arrangements with transit providers which will allow me to grow the capacity of the service and make it profitable such that I can work on IPv6 full time rather than as a side gig. The ideal outcome of that would be that IPv4-only content providers pay the cost through their transit bandwidth payments.
Me: Any technical details you would like to mention would also be great
Kasper: That's my kind of audience :-)
I can get really really technical.
I think what primarily sets my service aside from other services is that each of my DNS64 servers is automatically updated with NAT64 prefixes based on health checks of all the gateways. That means the outage of any single NAT64 gateway will be mostly invisible to users. This also helps with maintenance. I think that makes my NAT64 service the one with the highest availability among the public NAT64 services.
The NAT64 code is developed entirely by myself and currently runs as a user mode daemon on Linux. I am considering porting the most performance critical part to a kernel module.
This site
Alright so I got the basics up and running. In order to pull docker containers over IPv6 you need to add: registry.ipv6.docker.com/library/ to the front of the image name. So for instance: image: mysql:8.0 becomes image: registry.ipv6.docker.com/library/mysql:8.0
Docker warns you this setup isn't production ready. I'm not really sure what that means for Docker. Presumably if it were to stop you should be able to just pull normally?
Once that was done, we set up the site as an AAAA DNS record and allowed Cloudflare to proxy, meaning they handle the advertisement of IPv6 and bring the traffic to me. One thing I did modify from before was previously I was using Caddy webserver but since I now have a hard reliance on Cloudflare for most of my traffic, I switched to Nginx. One nice thing you can do now that you know all traffic is coming from Cloudflare is switch how SSL works.
Now I have an Origin Certificate from Cloudflare hard-loaded into Nginx with Authenticated Origin Pulls set up so that I know for sure all traffic is running through Cloudflare. The certificate is signed for 15 years, so I can feel pretty confident sticking it in my secrets management system and not thinking about it ever again. For those that are interested there is a tutorial here on how to do it: https://www.digitalocean.com/community/tutorials/how-to-host-a-website-using-cloudflare-and-nginx-on-ubuntu-22-04
Alright the site is back up and working fine. It's what you are reading right now, so if it's up then the system works.
Unsolved Problems
My containers still can't communicate with IPv4 resources even though they're on an IPv6 network with an IPv6 bridge. The DNS64 resolution is working, and I've added fixed-cidr-v6 into Docker. I can talk to IPv6 resources just fine, but the NAT64 conversion process doesn't work. I'm going to keep plugging away at it.
Before you ping me I did add NAT with ip6tables.
SMTP server problems. I haven't been able to find a commercial SMTP service that has an AAAA record. Mailgun and SES were both duds as were a few of the smaller ones I tried. Even Fastmail didn't have anything that could help me. If you know of one please let me know: https://c.im/@matdevdug
Why not stick with IPv4?
Putting aside "because we're running out of addresses" for a minute. If we had adopted IPv6 earlier, the way we do infrastructure could be radically different. So often companies use technology like load balancers and tunnels not because they actually need anything that these things do, but because they need some sort of logical division between private IP ranges and a public IP address they can stick in an DNS A record.
If you break a load balancer into its basic parts, it is doing two things. It is distributing incoming packets onto the back-end servers and it s checking the health of those servers and taking unhealthy ones out of the rotation. Nowadays they often handle things like SSL termination and metrics, but it's not a requirement to be called a load balancer.
There are many ways to load balance, but the most common are as follows:
Round-robin of connection requests.
Weighted Round-Robin with different servers getting more or less.
Least-Connection with servers that have the fewest connections getting more requests.
Weighted Least-Connection, same thing but you can tilt it towards certain boxes.
What you notice is there isn't anything there that requires, or really even benefits from a private IP address vs a public IP address. Configuring the hosts to accept traffic from only one source (the load balancer) is pretty simple and relatively cheap to do, computationally speaking. A lot of the infrastructure designs we've been forced into, things like VPCs, NAT gateways, public vs private subnets, all of these things could have been skipped or relied on less.
The other irony is that IP whitelisting, which currently is a broken security practice that is mostly a waste of time as we all use IP addresses owned by cloud providers, would actually be something that mattered. The process for companies to purchase a /44 for themselves would have gotten easier with demand and it would have been more common for people to go and buy a block of IPs from American Registry for Internet Numbers (ARIN), Réseaux IP Européens Network Coordination Centre (RIPE), or Asia-Pacific Network Information Centre (APNIC).
You would never need to think "well is Google going to buy more IP addresses" or "I need to monitor GitHub support page to make sure they don't add more later". You'd have one block they'd use for their entire business until the end of time. Container systems wouldn't need to assign internal IP addresses on each host, it would be trivial to allocate chunks of public IPs for them to use and also advertise over standard public DNS as needed.
Obviously I'm not saying private networks serve no function. My point is a lot of the network design we've adopted isn't based on necessity but on forced design. I suspect we would have ended up designing applications with the knowledge that they sit on the open internet vs relying entirely on the security of a private VPC. Given how security exploits work this probably would have been a benefit to overall security and design.
So even if cost and availability isn't a concern for you, allowing your organization more ownership and control over how your network functions has real measurable value.
Is this gonna get better?
So this sucks. You either pay cloud providers more money or you get a broken internet. My hope is that the folks who don't want to pay push more IPv6 adoption, but it's also a shame that it has taken so long for us to get here. All these problems and issues could have been addressed gradually and instead it's going to be something where people freak out until the teams that own these resources make the required changes.
I'm hopeful the end result might be better. I think at the very least it might open up more opportunities for smaller companies looking to establish themselves permanently with an IP range that they'll own forever, plus as IPv6 gets more mainstream it will (hopefully) get easier for customers to live with. But I have to say right now this is so broken it's kind of amazing.
If you are a small company looking to not pay the extra IP tax, set aside a lot of time to solve a myriad of problems you are going to encounter.
AWS and I have spent a frightening amount of time together. In that time I have come to love that weird web UI with bizarre application naming. It's like asking an alien not familiar with humans to name things. Why is Athena named Athena? Nothing else gets a deity name. CloudSearch, CloudFormation, CloudFront, Cloud9, CloudTrail, CloudWatch, CloudHSM, CloudShell are just lazy, we understand you are the cloud. Also Amazon if you are going to overuse a word that I'm going to search, use the second word so the right result comes up faster. All that said, I've come to find comfort in its primary color icons and "mobile phones don't exist" web UI.
Outside of AWS I've also done a fair amount of work with Azure, mostly in Kubernetes or k8s-adjacent spaces. All said I've now worked with Kubernetes on bare metal in a datacenter, in a datacenter with VMs, on raspberry pis in a cluster with k3s, in AWS with EKS, in Azure with AKS, DigitalOcean Kubernetes and finally with GKE in GCP. Me and the Kubernetes help documentation site are old friends at this point, a sea of purple links. I say all this to suggest that I have made virtually every mistake one can with this particular platform.
When being told I was going to be working in GCP (Google Cloud Platform) I was not enthused. I try to stay away from Google products in my personal life. I switched off Gmail for Fastmail, Search for DuckDuckGo, Android for iOS and Chrome for Firefox. It has nothing to do with privacy, I actually feel like I understand how Google uses my personal data pretty well and don't object to it on an ideological level. I'm fine with making an informed decision about using my personal data if the return to me in functionality is high enough.
I mostly move off Google services in my personal life because I don't understand how Google makes decisions. I'm not talking about killing Reader or any of the Google graveyard things. Companies try things and often they don't work out, that's life. It's that I don't even know how fundamental technology is perceived. Is Golang, which relies extensively on Google employees, doing well? Are they happy with it, or is it in danger? Is Flutter close to death or thriving? Do they like Gmail or has it lost favor with whatever executives are in charge of it this month? My inability to get a sense of whether something is doing well or poorly inside of Google makes me nervous about adopting their stack into my life.
I say all this to explain that, even though I was not excited to use GCP and learn a new platform. Even though there are parts of GCP that I find deeply frustrating as compared to its peers...there is a gem here. If you are serious about using Kubernetes, GKE is the best product I've seen on the market. It isn't even close. GKE is so good that if you are all-in on Kubernetes, it's worth considering moving from AWS or Azure.
I know, bold statement.
TL;DR
GKE is the best managed k8s product I've ever tried. It aggressively helps you do things correctly and is easy to set up and run.
GKE Autopilot is all of that but they handle all the node/upgrade/security etc. It's like Heroku-levels of easy to get something deployed. If you are a small company who doesn't want to hire or assign someone to manage infrastructure, you could grow forever on GKE Autopilot and still be able to easily migrate to another provider or the datacenter later on.
The rest of GCP is a bit of a mixed bag. Do your homework.
Disclaimer
I am not and have never been a google employee/contractor/someone they know exists. I once bombed an interview when I was 23 for an job at Google. This interview stands out to me because despite working with it every day for a year my brain just forgot how RAID parity worked on a data tranmission level. Got off the call and instantly all memory of how it worked returned to me. Needless to say nobody at Google cares that I have written this and it is just my opinions.
Corrections are always appreciated. Let me know at: [email protected]
Traditional K8s Setup
One common complaint about k8s is you have to set up everything. Even "hosted" platform often just provide the control plane, meaning almost everything else is some variation of your problem. Here's the typically collection of what you need to make decisions about in no particular order:
Secrets encryption: yes/no how
Version of Kubernetes to start on
What autoscaling technology are you going to use
Managed/unmanaged nodes
CSI drivers, do you need them, which ones
Which CNI, what does it mean to select a CNI, how do they work behind the scenes. This one in particular throws new cluster users because it seems like a nothing decision but it actually has profound impact in how the cluster operates
Can you provision load balancers from inside of the cluster?
CoreDNS, do you want it to cache DNS requests?
Vertical pod autoscaling vs horizontal pod autoscaling
Monitoring, what collects the stats, what default data do you get, where does it get stored (node-exporter setup to prometheus?)
Are you gonna use an OIDC? You probably want it, how do you set it up?
Helm, yes or no?
How do service accounts work?
How do you link IAM with the cluster?
How do you audit the cluster for compliance purposes?
Is the cluster deployed in the correct resilient way to guard against AZ outages?
Service mesh, do you have one, how do you install it, how do you manage it?
What OS is going to run on your nodes?
How do you test upgrades? What checks to make sure you aren't relying on a removed API? When is the right time to upgrade?
What is monitoring overall security posture? Do you have known issues with the cluster? What is telling you that?
Backups! Do you want them? What controls them? Can you test them?
Cost control. What tells you if you have a massively overprovisioned node group?
This isn't anywhere near all the questions you need to answer, but this is typically where you need to start. One frustration with a lot of k8s services I've tried in the past is they have multiple solutions to every problem and it's unclear which is the recommended path. I don't want to commit to the wrong CNI and then find out later that nobody has used that one in six months and I'm an idiot. (I'm often an idiot but I prefer to be caught for less dumb reasons).
Are these failings of kubernetes?
I don't think so. K8s is everything to every org. You can't make a universal tool that attempts to cover every edge case that doesn't allow for a lot of customization. With customization comes some degree of risk that you'll make the wrong choice. It's the Mac vs Linux laptop debate in an infrastructure sphere. You can get exactly what you need with the Linux box but you need to understand if all the hardware is supported and what tradeoffs each decision involves. With a Mac I'm getting whatever Apple thinks is the correct combination of all of those pieces, for better or worse.
If you can get away with Cloud Run or ECS, don't let me stop you. Pick the level of customization you need for the job, not whatever is hot right now.
Enter GKE
Alright so when I was hired I was tasked with replacing an aging GKE cluster that was coming to end of life running Istio. After running some checks, we weren't using any of the features of Istio, so we decided to go with Linkerd since it's a much easier to maintain service mesh. I sat down and started my process for upgrading an old cluster.
Check the node OS for upgrades, check the node k8s version
Confirm API usage to see if we are using outdated APIs
How do I install and manage the ancillary services and what are they? What installs CoreDNS, service mesh, redis, etc.
Can I stand up a clean cluster from what I have or was critical stuff added by hand? It never should be but it often is.
Map out the application dependencies and ensure they're put into place in the right order.
What controls DNS/load balancing and how can I cut between cluster 1 and cluster 2
It's not a ton of work, but it's also not zero work. It's also a good introduction to how applications work and what dependencies they have. Now my experience with recreating old clusters in k8s has been, to be blunt, a fucking disaster in the past. It typically involves 1% trickle traffic, everything returning 500s, looking at logs, figuring out what is missing, adding it, turning 1% back on, errors everywhere, look at APM, oh that app's healthcheck is wrong, etc.
The process with GKE was so easy I was actually sweating a little bit when I cut over traffic, because I was sure this wasn't going to work. It took longer to map out the application dependencies and figure out the Istio -> Linkerd part than it did to actually recreate the cluster. That's a first and a lot of it has to do with how GKE holds your hand through every step.
How does GKE make your life easier?
Let's walk through my checklist and how GKE solves pretty much all of them.
Node OS and k8 version on the node.
GCP offers a wide variety of OSes that you can run but recommends one I have never heard of before.
Container-Optimized OS from Google is an operating system image for your Compute Engine VMs that is optimized for running containers. Container-Optimized OS is maintained by Google and based on the open source Chromium OS project. With Container-Optimized OS, you can bring up your containers on Google Cloud Platform quickly, efficiently, and securely.
I'll be honest, my first thought when I saw "server OS based on Chromium" was "someone at Google really needed to get an OKR win". However after using it for a year, I've really come to like it Now it's not a solution for everyone, but if you can operate within the limits its a really nice solution. Here are the limits.
No package manager. They have something called the CoreOS Toolbox which I've used a few times to debug problems so you can still troubleshoot. Link
No non-containerized applications
No install third-party kernel modules or drivers
It is not supported outside of the GCP environment
I know, it's a bad list. But when I read some of the nice features I decided to make the switch. Here's what you get:
The root filesystem is always mounted as read-only. Additionally, its checksum is computed at build time and verified by the kernel on each boot.
Stateless kinda. /etc/ is writable but stateless. So you can write configuration settings but those settings do not persist across reboots. (Certain data, such as users' home directories, logs, and Docker images, persist across reboots, as they are not part of the root filesystem.)
Ton of other security stuff you get for free. Link
I love all this. Google tests the OS internally, they're scanning for CVEs, they're slowly rolling out updates and its designed to just run containers correctly, which is all I need. This OS has been idiot proof. In a year of running it I haven't had a single OS issue. Updates go out, they get patched, I don't notice ever. Troubleshooting works fine. This means I never need to talk about a Linux upgrade ever again AND the limitations of the OS means my applications can't rely on stuff they shouldn't use. Truly set and forget.
There's a lot of third-party tools that do this for you and they're all pretty good. However GKE does it automatically in a really smart way.
Not my cluster but this is what it looks like
Basically the web UI warns you if you are relying on outdated APIs and will not upgrade if you are. Super easy to check "do I have bad API calls hiding somewhere".
3. How do I install and manage the ancillary services and what are they?
GKE comes batteries included. DNS is there but it's just a flag in Terraform to configure. Service accounts same thing, Ingress and Gateway to GCP is also just in there working. Hooking up to your VPC through a toggle in Terraform so you can naively routeable. They even reserve the Pods IPs before the pods are created which is nice and eliminates a source of problems.
They have their own CNI which also just works. One end of the Virtual Ethernet Device pair is attached to the Pod and the other is connected to the Linux bridge device cbr0. I've never encountered any problems with any of the GKE defaults, from the subnets it offers to generate for pods to the CNI it is using for networking. The DNS cache is nice to be able to turn on easily.
4. Can I stand up a clean cluster from what I have or was critical stuff added by hand?
Because everything you need to do happens in Terraform for GKE, it's very simple to see if you can stand up another cluster. Load balancing is happening inside of YAMLs, ditto for deployments, so standing up a test cluster and seeing if apps deploy correctly to it is very fast. You don't have to install a million helm charts to get everything configured just right.
However they ALSO have backup and restore built it!
Here is your backup running happily and restoring it is just as easy to do through the UI.
So if you have a cluster with a bunch of custom stuff in there and don't have time to sort it out, you don't have to.
5. Map out the application dependencies and ensure they're put into place in the right order.
This obviously varies from place to place, but the web UI for GKE does make it very easy to inspect deployments and see what is going on with them. This helps a lot, but of course if you have a service mesh that's going to be the one-stop shop for figuring out what talks to what when. The Anthos service mesh provides this and is easy to add onto a cluster.
6. What controls DNS/load balancing and how can I cut between cluster 1 and cluster 2
Alright so this is the only bad part. GCP load balancers provide zero useful information. I don't know why, or who made the web UIs look like this. Again, making an internal or external load balancer as an Ingress or Gateway with GKE is stupid easy with annotations.
I don't who this is for or why I would care from what region of the world my traffic is coming from. It's also not showing correctly on Firefox with the screen cut off on the right. For context, this is the correct information I want from a load balancer every single time:
The entire GCP load balancer thing is a tire-fire. The web UI to make load balancers breaks all the time. Adding an SSL through the web UI almost never works. They give you a ton of great information about the backend of the load balancer but adding things like a new TLS policy requires kind of a lot of custom stuff. I could go on and on.
Autopilot
Alright so lets say all of that was still a bit much for you. You want a basic infrastructure where you don't need to think about nodes, or load balancers, or operating systems. You write your YAML, you deploy it to The Cloud and then things happens automagically. That is GKE Autopilot
Here are all the docs on it. Let me give you the elevator pitch. It's a stupid easy way to run Kubernetes that is probably going to save you money. Why? Because selecting and adjusting the type and size of node you provision is something most starting companies mess up with Kubernetes and here you don't need to do that. You aren't billed for unused capacity on your nodes, because GKE manages the nodes. You also aren't charged for system Pods, operating system costs, or unscheduled workloads.
Hardening Autopilot is also very easy. You can see all the options that exist and are already turned on here. If you are a person who is looking to deploy an application where maintaining it cannot be a big part of your week, this is a very flexible platform to do it on. You can move to standard GKE later if you'd like. Want off GCP? It is not that much work to convert your YAML to work with a different hosted provider or a datacenter.
I went in with low expectations and was very impressed.
Why shouldn't I use GKE?
I hinted at it above. As good as GKE is, the rest of GCP is crazy inconsistent. First the project structure for how things work is maddening. You have an organization and below that are projects (which are basically AWS accounts). They all have their own permission structure which can be inherited from folders that you put the projects in. However since GCP doesn't allow for the combination of IAM premade roles into custom roles, you end up needing to write hundreds of lines of Terraform for custom roles OR just find a premade role that is Pretty Close.
GCP excels at networking, data visualization (outside of load balancing), kubernetes, serverless with cloud run and cloud functions and big data work. A lot of the smaller services on the edge don't get a lot of love. If you are heavy users of the following, proceed with caution.
GCP Secret Manager
For a long time GCP didn't have any secret manager, instead having customers encrypt objects in buckets. Their secret manager product is about as bare-bones as it gets. Secret rotation is basically a cron job that pushes to a Pub/Sub topic and then you do the rest of it. No metrics, no compliance check integrations, no help with rotation.
It'll work for most use cases, but there's just zero bells and whistles.
GCP SSL Certificates
I don't know how Let's Encrypt, a free service, outperforms GCPs SSL certificate generation process. I've never seen a service that mangles SSL certificates as bad as this. Let's start with just trying to find them.
The first two aren't what I'm looking for. The third doesn't take me to anything that looks like an SSL certificate. SSL certificates actually live at Security -> Certificate Manager. If you try to go there even if you have SSL certificates you get this screen.
I'm baffled. I have Google SSL certificates with their load balancers. How is the API not enabled?
To issue the certs it does the same sort of DNS and backend checking as a lot of other services. To be honest I've had more problems with this service issuing SSL certificates than any in my entire life. It was easier to buy certificates from Verisign. If you rely a lot on generating a ton of these quickly, be warned.
IAM recommender
GCP has this great feature which is it audits what permissions a role has and then tells you basically "you gave them too many permissions". It looks like this:
Great right? Now sometimes this service will recommend you modify the permissions to either a new premade role or a custom role. It's unclear when or how that happens, but when it does there is a little lightbulb next to it. You can click it to apply the new permissions, but since mine (and most peoples) permissions are managed in code somewhere, this obviously doesn't do anything long-term.
Now you can push these recommendations to Big Query, but what I want is some sort of JSON or CSV that just says "switch these to use x premade IAM roles". My point is there is a lot of GCP stuff that is like 90% there. Engineers did the hard work of tracking IAM usage, generating the report, showing me the report, making a recommendation. I just need an easier way to act on that outside of the API or GCP web console.
These are just a few examples that immediately spring to mind. My point being when evaluating GCP please kick the tires on all the services, don't just see that one named what you are expecting exists. The user experience and quality varies wildly.
I'm interested, how do I get started?
GCP terraform used to be bad, but now it is quite good. You can see the whole getting started guide here. I recommend trying Autopilot and seeing if it works for you just because its cheap.
Even if you've spent a lot of time running k8s, give GKE a try. It's really impressive, even if you don't intend to move over to it. The security posture auditing, workload metrics, backup, hosted prometheus, etc is all really nice. I don't love all the GCP products, but this one has super impressed me.
I'm trying to use more YAML in my Terraform as a source of truth instead of endlessly repeating the creation of resources and to make CLIs to automate the creation of the YAML. One area that I've had a lot of luck with this is GCP IAM. This is due to a limitation in GCP that doesn't allow for the combination of pre-existing IAM roles into custom roles, which is annoying. I end up needing to assigns people the same permissions to many different projects and wanted to come up with an easier way to do this.
I did run into one small problem. When attempting to write out the YAML file, PyYAML was inserting these strange YAML tags into the end file that looked like this: !!python/tuple.
It turns out this is intended behavior, as PyYAML is serializing arbitrary objects as generic YAML, it is inserting deserialization hint tags. This would break the Terraform yamldecode as it couldn't understand the tags being inserted. The breaking code looks as follows.
with open(path,'r') as yamlfile:
current_yaml = yaml.safe_load(yamlfile)
current_yaml['iam_roles'].append(permissions)
if current_yaml:
with open(path,'w') as yamlfile:
yaml.encoding = None
yaml.dump(current_yaml, yamlfile, indent=4, sort_keys=False)
I ended up stumbling across a custom Emitter setting to fix this issue for Terraform. This is probably not a safe option to enable, but it does seem to work for me and does what I would expect.
The flag is: yaml.emitter.Emitter.prepare_tag = lambda self, tag: ''
So the whole thing, including the click elements looks as follows.
import click
import yaml
@click.command()
@click.option('--desc', prompt='For what is this role for? Example: analytics-developer, devops, etc', help='Grouping to assign in yaml for searching')
@click.option('--role', prompt='What GCP role do you want to assign?', help="All GCP premade roles can be found here: https://cloud.google.com/iam/docs/understanding-roles#basic")
@click.option('--assignment', prompt="Who is this role assigned to?", help="This needs the syntax group:, serviceAccount: or user: before the string. Example: group:[email protected] or serviceAccount:[email protected]")
@click.option('--path', prompt="Enter the relative path to the yaml you want to modify.", help="This is the relative path from this script to the yaml file you wish to append to", default='project-roles.yaml')
@click.option('--projects', multiple=True, type=click.Choice(['test', 'example1', 'example2', 'example3']))
def iam_augmenter(path, desc, role, assignment, projects):
permissions = {}
permissions["desc"] = desc
permissions["role"] = role
permissions["assignment"] = assignment
permissions["projects"] = projects
with open(path,'r') as yamlfile:
current_yaml = yaml.safe_load(yamlfile)
current_yaml['iam_roles'].append(permissions)
if current_yaml:
with open(path,'w') as yamlfile:
yaml.emitter.Emitter.prepare_tag = lambda self, tag: ''
yaml.encoding = None
yaml.dump(current_yaml, yamlfile, indent=4, sort_keys=False)
if __name__ == '__main__':
iam_augmenter()
This worked as intended, allowing me to easily append to an existing YAML file with the following format:
This allowed me to easily add the whole thing to automation that can be called from a variety of locations, meaning we can keep using the YAML file as the source of truth but quickly append to it from different sources. Figured I would share as this took me an hour to figure out and maybe it'll save you some time.
The Terraform that parses the file looks like this:
locals {
all_iam_roles = yamldecode(file("project-roles.yaml"))["iam_roles"]
stock_roles = flatten([for iam_role in local.all_iam_roles :
{
"description" = "${iam_role.desc}"
"role" = "${iam_role.role}"
"member" = "${iam_role.assignment}"
"project" = "${iam_role.projects}"
}
])
# Shortname for projects to full names
test = "test-dev"
example1 = "example1-dev"
example2 = "example2-dev"
example3 = "example3-dev"
}
resource "google_project_iam_member" "test-dev" {
for_each = {
for x in local.stock_roles : x.description => x
if contains(x.project, local.test) == true
}
project = local.test
role = each.value.role
member = each.value.member
}
resource "google_project_iam_member" "example1-dev" {
for_each = {
for x in local.stock_roles : x.description => x
if contains(x.project, local.example1) == true
}
project = local.example1
role = each.value.role
member = each.value.member
}
Hopefully this provides someone out there in GCP land some help with handling large numbers of IAM permissions. I've found it to be much easier to wrangle as a Python CLI that I can hook up to different sources.
Did I miss something or do you have questions I didn't address? Hit me up on Mastodon: https://c.im/@matdevdug
I've never worked at Google, but I've been impressed with a lot of the data manipulation and storage tools inside of GCP like BigQuery and Cloud Spanner. If you ever worked at Google, this might be a great way to find a replacement for an internal tool you loved. For the rest of us, it's a fascinating look at the internal technology stack of Google.