
The best tools in tech scale. They're not always easy to learn, they might take some time to get good with but once you start to use them they just stick with you forever. On the command line, things like gawk and sed jump to mind, tools that have saved me more than once. I've spent a decade now using Vim and I work with people who started using Emacs in university and still use it for 5 hours+ a day. You use them for basic problems all the time but when you need that complexity and depth of options, they scale with your problem. In the cloud when I think of tools like this, things like s3 and SQS come to mind, set and forget tooling that you can use from day 1 to day 1000.
Not every tool is like this. I've been using Terraform at least once a week for the last 5 years. I have led migrating two companies to Infrastructure as Code with Terraform from using the web UI of their cloud provider, writing easily tens of thousands of lines of HCL along the way. At first I loved Terraform, HCL felt easy to write, the providers from places like AWS and GCP are well maintained and there are tons of resources on the internet to get you out of any problem.
As the years went on, our relationship soured. Terraform has warts that, at this point, either aren't solvable or aren't something that can be solved without throwing away a lot of previous work. In no particular orders, here are my big issues with Terraform:
- It scales poorly. Terraform often starts with
devstageandprodas different workspaces. However since bothterraform planandterraform applymake API calls to your cloud provider for each resource, it doesn't take long for this to start to take a long time. You runplana lot when working with Terraform, so this isn't a trivial thing. - Then you don't want to repeat yourself, so you start moving more complicated logic into Modules. At this point the environments are completely isolated state files with no mixing, if you try to cross accounts things get more complicated. The basic structure you quickly adopt looks like this.
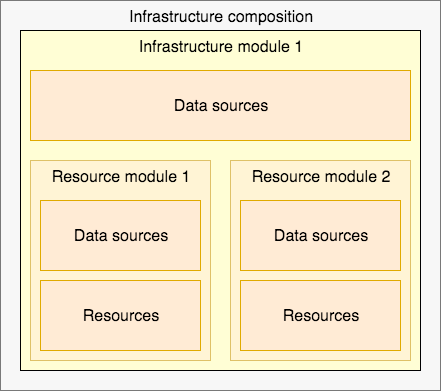
- At some point you need to have better DRY coverage, better environment handling, different backends for different environments and you need to work with multiple modules concurrently. Then you explore Terragrunt which is a great tool, but is now another tool on top of the first Infrastructure as code tool and it works with Terraform Cloud but it requires some tweaks to do so.
- Now you and your team realize that Terraform can destroy the entire company if you make a mistake, so you start to subdivide different resources out into different states. Typically you'll have the "stateless resources" in one area and the "stateful" resources in another, but actually dividing stuff up into one or another isn't completely straightforward. Destroying an SQS queue is really bad, but is it stateful? Kubernetes nodes don't have state but they're not instantaneous to fix either.
- HCL isn't a programming language. It's a fine alternative to YAML or JSON, but it lacks a lot of the tooling you want when dealing with more complex scenarios. You can do many of the normal things like conditionals, joins, trys, loops, for_each, but they're clunky and limited when compared to something like Golang or Python.
- The tooling around HCL is pretty barebones. You get some syntax checking, but otherwise it's a lot of switching tmux panes to figure out why it worked one place and didn't work another place.
terraform validateandterraform plandon't mean the thing is going to work. You can write something, it'll pass both check stages and fail onapply. This can be really bad as your team needs to basically wait for you to fix whatever you did so the infrastructure isn't in an inconsistent place or half working. This shouldn't happen in theory but its a common problem.- If an
applyfails, it's not always possible to back out. This is especially scary when there are timeouts, when something is still happening inside of the providers stack but now Terraform has given up on knowing what state it was left in. - Versioning is bad. Typically whatever version of Terraform you started with is what you have until someone decides to try to upgrade and hope nothing breaks.
tfenvbecomes a mission critical tool. Provider version drift is common, again typically "whatever the latest version was when someone wrote this module".
License Change
All of this is annoying, but I've learned to grumble and live with it. Then HashiCorp decided to pull the panic lever of "open-source" companies which is a big license change. Even though Terraform Cloud, their money-making product, was never open-source, they decided that the Terraform CLI needed to fall under the BSL. You can read it here. The specific clause people are getting upset about is below:
You may make production use of the Licensed Work,
provided such use does not include offering the Licensed Work to third parties on a hosted or embedded basis which is competitive with HashiCorp's products.
Now this clause, combined with the 4 year expiration date, effectively kills the Terraform ecosystem. Nobody is going to authorize internal teams to open-source any complementary tooling with the BSL in place and there certainly isn't going to be any competitive pressure to improve Terraform. While it doesn't, at least how I read it as not a lawyer, really impact most usage of Terraform as just a tool that you run on your laptop, it does make the future of Terraform development directly tied to Terraform Cloud. This wouldn't be a problem except Terraform Cloud is bad.
Terraform Cloud
I've used it for a year, it's extremely bare-bones software. It picks the latest version when you make the workspace of Terraform and then that's it. It doesn't help you upgrade Terraform, it doesn't really do any checking or optimizations, structure suggestions or anything else you need as Terraform scales. It sorta integrates with Terragrunt but not really. Basically it is identical to the CLI output of Terraform with some slight visual dressing. Then there's the kicker: the price.
$0.00014 per resource per hour. This is predatory pricing. First, because Terraform drops in value to zero if you can't put everything into Infrastructure as Code. HashiCorp knows this, hence the per-resource price. Second because they know it's impossible for me, the maintainer of the account, to police. What am I supposed to do, tell people "no you cannot have a custom IAM policy because we can't have people writing safe scoped roles"? Maybe I should start forcing subdomain sharing, make sure we don't get too spoiled with all these free hostnames. Finally it's especially grating because we're talking about sticking small collections of JSON onto object storage. There's no engineering per resource, no scaling concerns on HashiCorp's side and disk space is cheap to boot.
This combined with the license change is enough for me. I'm out. I'll deal with some grief to use your product, but at this point HashiCorp has overplayed the value of Terraform. It's a clunky tool that scales poorly and I need to do all the scaling and upgrade work myself with third-party tools, even if I pay you for your cloud product. The per-hour pricing is just the final nail in the coffin from HashiCorp.
I asked around for an alternative and someone recommend Pulumi. I've never heard of them before, so I thought this could be a super fun opportunity to try them out.
Pulumi
Pulumi and Terraform are similar, except unlike Terraform with HCL, Pulumi has lots of scale built in. Why? Because you can use a real programming language to write your Infrastructure as Code. It's a clever concept, letting you scale up the complexity of your project from writing just YAML to writing Golang or Python.
Here is the basic outline of how Pulumi structures infrastructure.
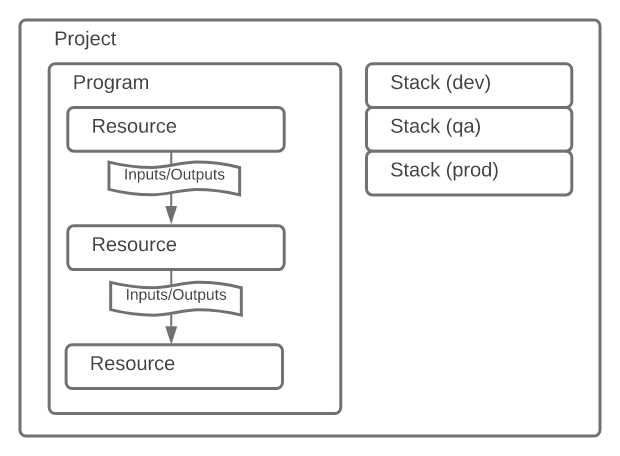
You write programs inside of projects with Nodejs, Python, Golang, .Net, Java or YAML. Programs define resources. You then run the programs inside of stacks, which are different environments. It's nice that Pulumi comes with the project structure defined vs Terraform you define it yourself. Every stack has its own state out of the box which again is a built-in optimization.
Installation was easy and they had all the expected install options. Going through the source code I was impressed with the quality, but was concerned about the 1,718 open issues as of writing this. Clicking around it does seem like they're actively working on them and it has your normal percentage of "not real issues but just people opening them as issues" problem. Also a lot of open issues with comments suggests an engaged user base. The setup on my side was very easy and I opted not to use their cloud product, mostly because it has the same problem that Terraform Cloud has.
A Pulumi Credit is the price for managing one resource for one hour. If using the Team Edition, each credit costs $0.0005. For billing purposes, we count any resource that's declared in a Pulumi program. This includes provider resources (e.g., an Amazon S3 bucket), component resourceswhich are groupings of resources (e.g., an Amazon EKS cluster), and stacks which contain resources (e.g., dev, test, prod stacks).
You consume one Pulumi Credit to manage each resource for an hour. For example, one stack containing one S3 bucket and one EC2 instance is three resources that are counted in your bill. Example: If you manage 625 resources with Pulumi every month, you will use 450,000 Pulumi Credits each month. Your monthly bill would be $150 USD = (450,000 total credits - 150,000 free credits) * $0.0005.
My mouth was actually agape when I got to that monthly bill. I get 150k credits for "free" with Teams which is 200 resources a month. That is absolutely nothing. That's "my DNS records live in Infrastructure as Code". But paying per hour doesn't even unlock all the features! I'm limited on team size, I don't get SSO, I don't get support. Also you are the smaller player, how do you charge more than HashiCorp? Disk space is real cheap and these files are very small. Charge me $99 a month per runner or per user or whatever you need to, but I don't want to ask the question "are we putting too much of our infrastructure into code". It's either all in there or there's zero point and this pricing works directly against that goal.
Alright so Pulumi Cloud is out. Maybe the Enterprise pricing is better but that's not on the website so I can't make a decision based on that. I can't mentally handle getting on another sales email list. Thankfully Pulumi has state locking with S3 now according to this so this isn't a deal-breaker. Let's see what running it just locally looks like.
Pulumi Open-Source only
Thankfully they make that pretty easy. pulumi login --localpulumi login s3:// Now managing state locally or using S3 isn't a new thing, but it's nice that switching between them is pretty easy. You can start local, grow to S3 and then migrate to their Cloud product as you need. Run pulumi new python for a new blank Python setup.
❯ pulumi new python
This command will walk you through creating a new Pulumi project.
Enter a value or leave blank to accept the (default), and press <ENTER>.
Press ^C at any time to quit.
project name: (test) test
project description: (A minimal Python Pulumi program)
Created project 'test'
stack name: (dev)
Created stack 'dev'
Enter your passphrase to protect config/secrets:
Re-enter your passphrase to confirm:
Installing dependencies...
Creating virtual environment...
Finished creating virtual environment
Updating pip, setuptools, and wheel in virtual environment...I love that it does all the correct Python things. We have a venv, we've got a requirements.txt and we've got a simple configuration file. Working with it was delightful. Setting my Hetzner API key as a secret was easy and straight-forward with: pulumi config set hcloud:token XXXXXXXXXXXXXX --secret. So what does working with it look like. Let's look at an error.
❯ pulumi preview
Enter your passphrase to unlock config/secrets
(set PULUMI_CONFIG_PASSPHRASE or PULUMI_CONFIG_PASSPHRASE_FILE to remember):
Previewing update (dev):
Type Name Plan Info
pulumi:pulumi:Stack matduggan.com-dev 1 error
Diagnostics:
pulumi:pulumi:Stack (matduggan.com-dev):
error: Program failed with an unhandled exception:
Traceback (most recent call last):
File "/opt/homebrew/bin/pulumi-language-python-exec", line 197, in <module>
loop.run_until_complete(coro)
File "/opt/homebrew/Cellar/[email protected]/3.11.3/Frameworks/Python.framework/Versions/3.11/lib/python3.11/asyncio/base_events.py", line 653, in run_until_complete
return future.result()
^^^^^^^^^^^^^^^
File "/Users/mathew.duggan/Documents/work/pulumi/venv/lib/python3.11/site-packages/pulumi/runtime/stack.py", line 137, in run_in_stack
await run_pulumi_func(lambda: Stack(func))
File "/Users/mathew.duggan/Documents/work/pulumi/venv/lib/python3.11/site-packages/pulumi/runtime/stack.py", line 49, in run_pulumi_func
func()
File "/Users/mathew.duggan/Documents/work/pulumi/venv/lib/python3.11/site-packages/pulumi/runtime/stack.py", line 137, in <lambda>
await run_pulumi_func(lambda: Stack(func))
^^^^^^^^^^^
File "/Users/mathew.duggan/Documents/work/pulumi/venv/lib/python3.11/site-packages/pulumi/runtime/stack.py", line 160, in __init__
func()
File "/opt/homebrew/bin/pulumi-language-python-exec", line 165, in run
return runpy.run_path(args.PROGRAM, run_name='__main__')
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen runpy>", line 304, in run_path
File "<frozen runpy>", line 240, in _get_main_module_details
File "<frozen runpy>", line 159, in _get_module_details
File "<frozen importlib._bootstrap_external>", line 1074, in get_code
File "<frozen importlib._bootstrap_external>", line 1004, in source_to_code
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/Users/mathew.duggan/Documents/work/pulumi/__main__.py", line 14
)], user_data="""
^
SyntaxError: unterminated triple-quoted string literal (detected at line 17)We get all the super clear output of a Python error message, we still get the secrets encryption and we get all the options of Python when writing the file. However things get a little unusual when I go to inspect the state files.
Local State Files
For some reason when I select local, Pulumi doesn't store the state files in the same directory as where I'm working. Instead it stores them as a user preference at ~/.pulumi which is odd. I understand I selected local, but it's weird to assume I don't want to store the state in git or something. It is also storing a lot of things in my user directory: 358 directories, 848 files. Every template is its own directory.
How can you set it up to work correctly?
rm -rf ~/.pulumi
mkdir test && cd test
mkdir pulumi
pulumi login file://pulumi/
pulumi new --force python
cd ~/.pulumi
336 directories, 815 files
If you go back into the directory and go to /test/pulumi/.pulumi you do see the state files. The force flag is required to let it create the new project inside a directory with stuff already in it. It all ends up working but it's clunky.
Maybe I'm alone on this, but I feel like this is unnecessarily complicated. If I'm going to work locally, the assumption should be I'm going to sit this inside of a repo. Or at the very least I'm going to expect the directory to be a self-contained thing. Also don't put stuff at $HOME/.pulumi. The correct location is ~/.config. I understand nobody follows that rule but the right places to put it are: in the directory where I make the project or in ~/.config.
S3-compatible State
Since this is the more common workflow, let me talk a bit about S3 remote backend. I tried to do a lot of testing to cover as many use-cases as possible. The lockfile works and is per stack, so you do have that basic level of functionality. Stacks cannot reference each other's outputs unless they are in the same bucket as far as I can tell, so you would need to plan for one bucket. Sharing stack names across multiple projects works, so you don't need to worry that every project has a dev, stage and prod. State encryption is your problem, but that's pretty easy to deal with in modern object storage.
The login process is basically pulumi login 's3://?region=us-east-1&awssdk=v2&profile=' and for GCP pulumi login gs://. You can see all the custom backend setup docs here. I also moved between custom backends, going from local to s3 and from s3 to GCP. It all functioned like I would expect, which was nice.
Otherwise nothing exciting to report. In my testing it worked as well as local, and trying to break it with a few folks working on the same repo didn't reveal any obvious problems. It seems as reliable as Terraform in S3, which is to say not perfect but pretty good.
Daily use
Once Pulumi was set up to use object storage, I tried to use it to manage a non-production project in Google Cloud along with someone else who agreed to work with me on it. I figured with at least two people doing the work, the experience would be more realistic.
Compared to working with Terraform, I felt like Pulumi was easier to use. Having all of the options and autocomplete of an IDE available to me when I wanted it really sped things up, plus handling edge cases that previously would have required a lot of very sensitive HCL were very simple with Python. I also liked being able to write tests for infrastructure code, which made things like database operations feel less dangerous. In Terraform the only safety check is whoever is looking at the output, so having another level of checking before potentially destroying resources was nice.
While Pulumi does provide more opinions on how to structure it, even with two of us there were quickly some disagreements on the right way to do things. I prefer more of a monolithic design and my peer prefers smaller stacks, which you can do but I find chaining together the stack output to be more work than its worth. I found the micro-service style in Pulumi to be a bit grating and easy to break, while the monolithic style was much easier for me to work in.
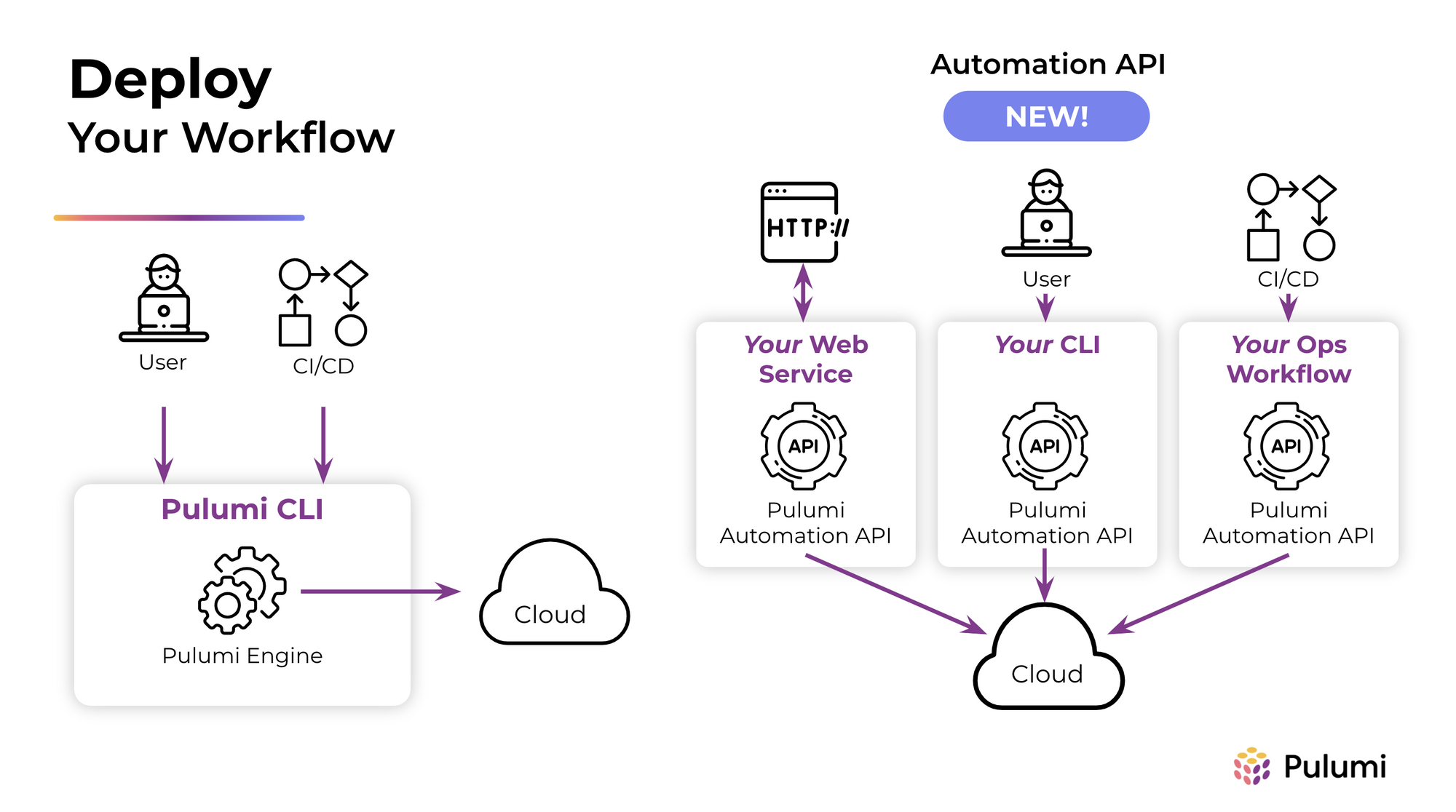
Setting up a CI/CD pipeline wasn't too challenging, basing everything off of this image. All the CI/CD docs on their website presuppose you are using the Cloud product, which again makes sense and I would be glad to do if they changed the pricing. However rolling your own isn't hard, it works as expected, but I want to point out one sticking point I ran into that isn't really Pulumi's fault so much as it is "the complexity of adding in secrets support".
Pulumi Secrets
So Pulumi integrates with a lot of secret managers, which is great. It also has its own secret manager which works fine. The key things to keep in mind are: if you are adding a secret, make sure you flag it as a secret to keep it from getting printed on the output. If you are going to use an external secrets manager, set aside some time to get that working. It took a bit of work to get the permissions such that CI/CD and everything else worked as expected, especially with the micro-service design where one program relied on the output of another program. You can read the docs here.
Unexpected Benefits
Here are some delightful (maybe obvious) things I ran into while working with Pulumi.
- We already have experts in these languages. It was great to be able to ask someone with years of Python development experience "what is the best way to structure large Python projects". There is so much expertise and documentation out there vs the wasteland that is Terraform project architecture.
- Being able to use a database. Holy crap, this was a real game-changer to me. I pulled down the GCP IAM stock roles, stuck them in SQLite and then was able to query them depending on the set of permissions the service account or user group required. Very small thing, but a massive time-saver vs me going to the website and searching around. It also lets me automate the entire process of Ticket -> PR for IAM role.
- You can set up easy APIs. Making a website that generates HCL to stick into a repo and then make a PR? Nightmare. Writing a simple Flask app that runs Pulumi against your infrastructure with scoped permissions? Not bad at all. If your org does something like "add a lot of DNS records" or "add a lot of SSH keys", this really has the potential to change your workday. Also it's easy to set up an abstraction for your entire Infrastructure. Pulumi has docs on how to get started with all of this here. Slack bots, simple command-line tools, all of it was easy to do.
- Tests. It's nice to be able to treat infrastructure like its important.
- Getting better at a real job skill. Every hour I get more skilled in writing Golang, I'm more valuable to my organization. I'm also just getting more hours writing code in an actual programming language, which is always good. Every hour I invest in HCL is an hour I invested in something that no other tool will ever use.
- Speed seemed faster than Terraform. I don't know why that would be, but it did feel like especially on successive previews the results just came much faster. This was true on our CI/CD jobs as well, timing them against Terraform it seemed like Pulumi was faster most of the time. Take this with a pile of salt, I didn't do a real benchmark and ultimately we're hitting the same APIs, so I doubt there's a giant performance difference.
Conclusion
Do I think Pulumi can take over the Terraform throne? There's a lot to like here. The product is one of those great ideas, a natural evolution from where we started in DevOps to where we want to go. Moving towards treating infrastructure like everything else is the next logical leap and they have already done a lot of the ground work. I want Pulumi to succeed, I like it as a product.
However it needs to get out of its own way. The pricing needs a rethink, make it a no-brainier for me to use your cloud product and get fully integrated into it. If you give me a reliable, consistent bill I can present to leadership, I don't have to worry about Pulumi as a service I need to police. The entire organization can be let loose to write whatever infra they need, which benefits us and Pulumi as we'll be more dependent on their internal tooling.
If cost management is a big issue, have me bring my own object storage and VMs for runners. Pulumi can still thrive and be very successfully without being a zero-setup business. This is a tool for people who maintain large infrastructures. We can handle some infrastructure requirements if that is the sticking point.
Hopefully the folks running Pulumi see this moment as the opportunity it is, both for the field at large to move past markup languages and for them to make a grab for a large share of the market.
If there is interest I can do more write-ups on sample Flask apps or Slack bots or whatever. Also if I made a mistake or you think something needs clarification, feel free to reach out to me here: https://c.im/@matdevdug.