I have never been an "online community first" person. The internet is how I stay in touch with people I met in real life. I'm not a "tweet comments at celebrities" guy. I was never funny enough to be the funniest person on Twitter.
So when Twitter was accidentally purchased by a fascist high on ketamine, I moved to Mastodon mostly because it seemed to be “Twitter without the bullshit”. No recommended for you feed, no ads, it was broken in a way I find charming. Of course search was broken because all OSS social tools must have one glaring lack of functionality. In a nightmare world full of constant change it’s good to have a few constants to hold on to.
A lot of the narrative at the time was “this is our flag in the ground in the fight against The Man”. It wasn’t clear in this context if they meant corporations or the media or the weird pseudo celebrity that had taken over social media where people would breathlessly tell me about shit like “Chris-Chan” and “Logan Paul bought a Pokemon card”.
We all need pointless hobbies, but I care about YouTube stars like I care about distant stars dying. It’s interesting to someone somewhere but those people don’t talk to me. I mostly use social media as a place to waste time, not a platform to form para-social relationships to narcissists. I prefer my narcissism farm to table. I’d rather dig a grave with a rusty spoon than watch a Twitch “star”.
Anyway, I watched mostly apathetically as the internet tried to rally itself to another cause. I read my news at the normal newspapers, watched my normal television and put social media off into its own silo. Then Trump effectively shut down the entire free press in the US in a series of bullshit lawsuits.
See I had forgotten the one golden rule of capitalism. To thrive in capitalism one must be amoral. Now you can be wildly sickeningly successful with morals but you cannot reach that absolute zenith of shareholder value. Either you accept a lower share price and don’t commit atrocities or you become evil. There is no third option.
So of course media corporations became bargaining chips for the oligarchs' actual businesses. Why fight a defamation suit when you can settle it by running favorable coverage and maybe bankrupting the media outlet you bought as a stocking stuffer? Suddenly I couldn’t find any reliable reporting about anything in the US. My beloved Washington Post became straight-up propaganda and desperate attempts to cope. "Best winter stews to make while you watch your neighbors get kidnapped at gunpoint." Twelve dollars a month for that.
Threads was worthless because it’s the most boring social media website ever imagined. It’s a social media network designed by brands for brands, like if someone made a cable channel that was just advertisements and meta commentary about the advertisements you just saw. Billions of dollars at their disposal and Meta made a hot new social media network with the appeal of junk mail.
Bluesky had a bunch of “stuff” but they’re trying to capture that 2008 Twitter lightning in a bottle which is a giant waste of time. We’re never going to go back to pretending that tweeting at politicians does anything and everyone there is desperately trying to build a “brand” as the funny one or whatever. I want news I don’t want your endless meta commentary on the news.
People talk a lot about the protocols that power Bluesky vs. ActivityPub, because we're nerds and we believe deep in our hearts that the superior protocol will win. This is adorable. It flies in the face of literally all of human history, where the more convenient thing always wins regardless of technical merit. VHS beat Betamax. USB-C took twenty years. The protocol fight is interesting the way medieval siege warfare is interesting — I'm glad someone's into it, but it has no bearing on my life. There's no actual plan to self-host Bluesky. Their protocol makes it easier to scale their service. That's why it was written and that's what it does. End of story.
Now EU news remained reliable, but sending European reporters into the madness of the US and trying to get a “report” out of it is an exercise in frustration. This became especially relevant for me when Trump threatened to invade Greenland and suddenly there was a distinct possibility that there might be an armed conflict between Denmark and the US. Danish reporters weren’t getting meetings with the right people and it was just endless rumors and Truth Social nonsense.
If the American press had given me 20 minutes of airtime I could have convinced everyone they don’t want to get involved with Greenland. We’re not tough enough as a people to survive in Greenland, much less “take it over”. Greenlandic people shrug off horrific injuries hundreds of kilometers from medical help with a smile. I watched a Greenlandic toddler munch meat from the spine of a seal with its head very much intact. We aren’t equipped to fuck with these people, they are the real deal.
So in this complete breakdown of the press came in the Fediverse. It became the only reliable source of information I had. People posted links with a minimal amount of commentary, picking and choosing the best content from other social media networks. They’re not doing it to “build a brand” because that’s not a thing in the Fediverse. It’s too disjointed to be a place to build a newsletter subscription base.
Instead it became the only place consistently posting trustworthy information I could actually access. This became personally relevant when Trump threatened to invade Greenland, which is the kind of sentence I never expected to type and yet here we are. It would be funny if I wasn't a tiny bit concerned that my new home was going to get a CIA overnight regime change special in the middle of the night.
It was somewhere in the middle of DMing with someone who had forgotten more about Greenland than I would ever know and someone who lived close to an RAF base in the UK that it clicked. This was what they had been talking about. Actual human beings were able to find each other and ask direct questions without this giant mountain of bullshit engagement piled on top of it. Meta or Oracle or whoever owns TikTok this week couldn't stop me.
I never expected to find my news from strangers on a federated social network that half the internet has never heard of. I never expected a lot of things. But there's something quietly beautiful about a place where people just... share what they know. No brand deals, no engagement metrics, no algorithm nudging you toward rage. Just someone who spent twenty years studying Arctic policy posting a thread at 2 AM because they think you should understand what's happening. It's the internet I was promised in 1996. It only took thirty years and the complete collapse of American journalism to get here.
Until recently the LLM tools I’ve tried have been, to be frank, worthless. Copilot was best at writing extremely verbose comments. Gemini would turn a 200 line script into a 700 line collection of gibberish. It was easy for me to, more or less, ignore LLMs for being the same over-hyped nonsense as the Metaverse and NFTs.
This is great for me because I understand that LLMs represent a massive shift in power from an already weakened worker class to an increasingly monarch-level wealthy class. By stealing all human knowledge and paying nothing for it, then selling the output of that knowledge, LLMs are an impossibly unethical tool. So if the energy wasting tool of the tech executive class is also a terrible tool, easy choice.
Like boycotting Tesla for being owned by an evil person and also being crappy overpriced cars, or not shopping at Hobby Lobby and just buying directly from their Chinese suppliers, the best boycotts are ones where you aren’t really losing much. Google can continue to choke out independent websites with their AI results that aren’t very good and I get to feel superior doing what I was going to do anyway by not using Google search.
This logic was all super straight forward right up until I tried Claude Code. Then it all got much more complicated.
Some Harsh Truths
Let’s just get this out of the way right off the bat. I didn't want to like Claude Code. I got a subscription with the purpose of writing a review on it where I would find that it was just as terrible as Gemini and Copilot. Except that's not what happened.
Instead it was like discovering the 2AM kebab place might actually make the best pizza in town. I kept asking Claude to do annoying tasks where it was easy for me to tell if it had made a mistake and it kept doing them correctly. It felt impossible but the proof was right in front of me.
I’ve written tens of thousands of lines of Terraform in my life. It is a miserable chore to endlessly flip back and forth between the provider documentation and Vim, adding all the required parameters. I don’t learn anything by doing it, it’s just a grind I have to push through to get back to the meaningful work.
The amount of time I have wasted on this precious time on Earth importing all of a companies DNS records into Terraform, then taking the autogenerated names and organizing them so that they make sense for the business is difficult to express. It's like if the only way I knew how to make a hamburger bun was to carefully put every sesame seed by hand on the top only to stumble upon an 8 pack of buns for $4 at the grocery store after years of using tiny tweezers to put the seeds in exactly the right spot.
I feel the same way about writing robust READMEs, k8s YAML and reorganizing the file structure of projects. Setting up more GitHub Actions is as much fun as doing my taxes. If I never had to write another regex for the rest of my life, that would be a better life by every conceivable measure.
These are tasks that sap my enthusiasm for this type of work, not feed it. I’m not sad to offload them and switch to mostly reviewing its PRs.
But the tool being useful doesn’t remove what’s bad about it. This is where a lot of pro-LLM people start to delude themselves.
Pro-LLM Arguments
In no particular order are the arguments I keep seeing about LLMs from people who want to keep using them for why their use is fine.
IP/Copyright Isn’t Real
This is the most common one I see and the worst. It can be condensed down to “because most things on the internet originally existed to find pornography and/or pirate movies, stealing all content on the internet is actually fine because programmers don’t care about copyright”.
You also can’t have it both ways. OpenAI can’t decide to enforce NDAs and trademarks and then also declare law is meaningless. If I don’t get to launch a webmail service named Gmail+ then Google doesn’t get to steal all the books in human existence.
The argument basically boils down to: because we all pirated music in 2004, intellectual property is a fiction when it stands in the way of technology. By this logic I shoplifted a Snickers bar when I was 12 so property rights don't exist and I should be allowed to live in your house.
Code Quality Doesn't Matter (According to Someone Who Might Be Right)
I have an internet friend I met years ago playing EVE Online that is a brutally pragmatic person. To someone like him, code craftsmanship is a joke. For those of you who are unaware, EVE Online is the spaceship videogame where sociopaths spend months plotting against each other.
His approach to development is 80% refining requirements and getting feedback. He doesn’t care at all about DRY, he uses Node because then he can focus on just JavaScript, he doesn’t invest a second into optimization until the application hits a hard wall that absolutely requires it. His biggest source of clients? Creating fast full stacks because internal teams are missing deadlines. And he is booked up for at least 12 months out all the time because he hits deadlines.
When he started freelancing I thought he was crazy. Who was going to hire this band of Eastern European programmers who chain smoke during calls and whose motto is basically "we never miss a deadline". As it turns out, a lot of people.
Why doesn't he care?
Why doesn't he care about these things? He believes that programmers fundamentally don't understand the business they are in. "Code is perishable" is something he says a lot and he means it. Most of the things we all associate with quality (full test coverage, dependency management, etc) are programmers not understanding the rate of churn a project undergoes over its lifespan. The job of a programmer, according to him, is delivering features that people will use. How pleasant and well-organized that code is to work with is not really a thing that matters in the long term.
He doesn't see LLM-generated code as a problem because he's not building software with a vision that it will still be used in 10 years. Most of the stuff typically associated with quality he, more or less, throws in the trash. He built a pretty large stack for a automotive company and my jaw must have hit the table when he revealed they're deploying m6g.4xlarge for a NodeJS full-stack application. "That seems large to me for that type of application" was my response.
He was like "yeah but all I care about are whether the user metrics show high success rate and high performance for the clients". It's $7000 a year for the servers, with two behind a load balancer. That's absolutely nothing when compared with the costs of what having a team of engineers tune it would cost and it means he can run laps around the internal teams who are, basically, his greatest competition.
To be clear, he is very technically competent. He simply rejects a lot of the conventional wisdom out there about what one has to do in order to make stuff. He focuses on features, then securing endpoints and more or less gives up on the rest of it. For someone like this, LLMs are a logical choice for him.
Why This Argument Doesn't Work for Me
The annoying thing about my friend is that his bank account suggests he's right. But I can't get there. If I'm writing a simple script or something as a one-off, it can sometimes feel like we're all wasting the companies time when we have a long back and forth on the PR discussing comments or the linting or whatever. So it's not that this idea is entirely wrong.
But the problem with programming is you never know what is going to be "the core" of your work life for the next 5 years. Sometimes I write a feature, we push it out, it explodes in popularity and then I'm a little bit in trouble because I built a MVP and now it's a load-bearing revenue generating thing that has to be retooled.
I also just have trouble with the idea that this is my career and the thing I spend my limited time on earth doing and the quality of it doesn't matter. I delight in craftsmanship when I encounter it in almost any discipline. I love it when you walk into an old house and see all the hand crafted details everywhere that don't make economic sense but still look beautiful. I adore when someone has carefully selected the perfect font to match something.
Every programmer has that library or tool that they aspire to. That code base where you delight at looking at it because it proves perfection is possible even if you have never come close to reaching that level. For me its always been looking through the source code of SQLite that restores my confidence. I might not know what I'm doing but it's good to be reminded that someone out there does.
Not everything I make is that great, but the concept of "well great doesn't matter at all" effectively boils down to "don't take pride in your work" which is probably the better economic argument but feels super bad to me. In a world full of cheap crap, it feels bad to make more of it and then stick my name on it.
So Why Are People Still Using Them?
The best argument for why programmers should be using LLMs is because it's going to be increasingly difficult to compete for jobs and promotions against people who are using them. In my experience Claude Code allows me to do two tasks at once. That's a pretty hard advantage to overcome.
Last Tuesday I had Claude Code write a GitHub Action for me while I worked on something else. When it was done, I reviewed it, approved it, and merged it. It was fine. It was better than fine, actually — it was exactly what I would have written, minus the forty-five minutes of resentment. I sat there for a moment, staring at the merged PR, feeling the way I imagine people feel when they hire a cleaning service for the first time: relieved, and then immediately guilty about the relief, and then annoyed at myself for feeling guilty about something that is, by any rational measure, a completely reasonable thing to do. Except it isn't reasonable. Or maybe it is. I genuinely don't know anymore, and that's the part that bothers me the most — not that the tool works, but that I've lost the clean certainty that it shouldn't.
So now I'm paying $20 a month to a company that scraped the collective knowledge of humanity without asking so that I can avoid writing Kubernetes YAML. I know what that makes me. I just haven't figured out a word for it yet that I can live with.
When I asked my EVE friend about it on a recent TeamSpeak session, he was quiet for awhile. I thought that maybe my moral dilemma had shocked him into silence. Then he said, "You know what the difference is between you and me? I know I'm a mercenary. You thought you were an artist. We're both guys who type for money."
I couldn't think of a clever response to that. I still can't.
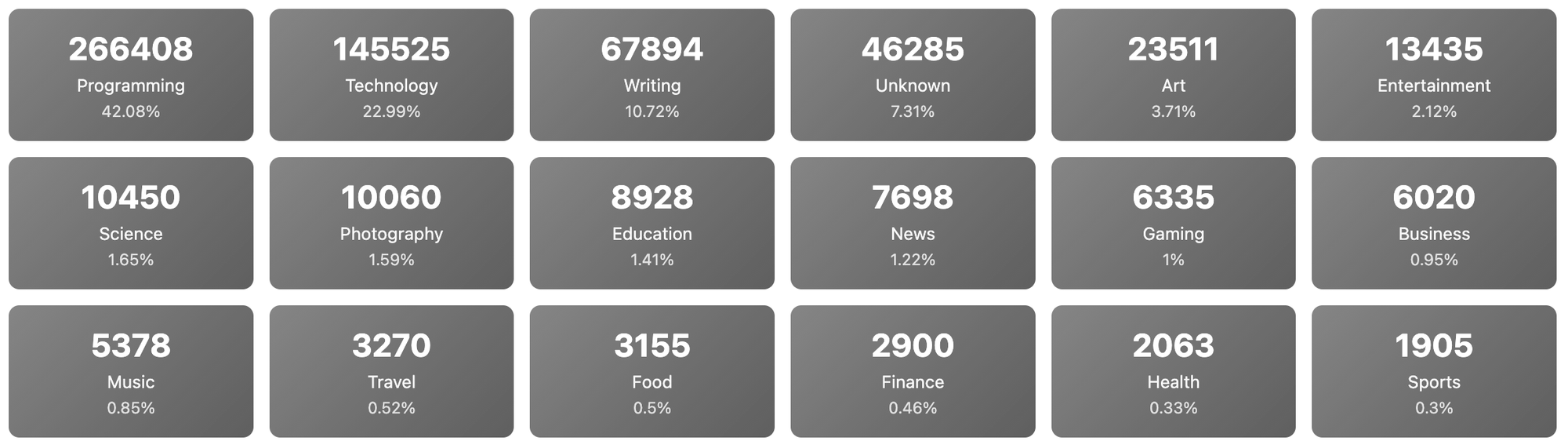
One of the most common requests I've gotten from users of my little Firefox extension(https://timewasterpro.xyz) has been more options around the categories of websites that you get returned. This required me to go through and parse the website information to attempt to put them into different categories. I tried a bunch of different approaches but ended up basically looking at the websites themselves seeing if there was anything that looked like a tag or a hint on each site.
This is the end conclusion of my effort at putting stuff into categories.
Unknown just means I wasn't able to get any sort of data about it. This is the result of me combining Ghost, Wordpress and Kagi Small Web data sources.
Interestingly one of my most common requests is "I would like less technical content" which as it turns out is tricky to provide because it's pretty hard to find. They sorta exist but for less technical users they don't seem to have bought into the value of the small web own your own web domain (or if they have, I haven't been able to figure out a reliable way to find them).
This is an interesting problem, especially because a lot of the tools I would have previously used to solve this problem are....basically broken. It's difficult for me to really use Google web search to find anything at this point even remotely like "give me all the small websites" because everything is weighted to steer me away from that towards Reddit. So anything that might be a little niche is tricky to figure out.
Interesting findings
So there's no point in building a web extension with a weighting algorithm to return less technical content if I cannot find a big enough pool of non-technical content to surface. It isn't that these sites don't exist its just that we never really figured out a way to reliably surface "what is a small website".
So from a technical perspective I have a bunch of problems.
First I need to reliably sort websites into a genre, which can be a challenge when we're talking about small websites because people typically write about whatever moves them that day. Most of the content on a site might be technical, but some of it might not be. Big sites tend to be more precise with their SEO settings but small sites that don't care don't do that, so I have fewer reliable signals to work with.
Then I need to come up with a lot of different feeding systems for independent websites. The Kagi Small Web was a good starting point, but Wordpress and Ghost websites have a much higher ratio of non-technical content. I need those sites, but it's hard to find a big batch of them reliably.
Once I have the type of website as a general genre and I have a series of locations, then I can start to reliably distribute the types of content you get.
I think I can solve....some of these, but the more I work on the problem the more I'm realizing that the entire concept of "the small web" had a series of pretty serious problems.
Google was the only place on Earth sending any traffic there
Because Google was the only one who knew about it, there never needed to be another distribution system
Now that Google is broken, it's almost impossible to recreate that magic of becoming the top of list for a specific subgenre without a ton more information than I can get from public records.
My workflow has remained mostly the same for over a decade. I write everything in Vim using the configuration found here. I run Vim from inside of tmux with a configuration found here. I write things on a git branch, made with the git CLI, then I add them with git add --patch to that branch, trying to run all of the possible linting and tests with git hooks before I waste my time on GitHub Actions. Then I run git up which is an alias to pull --rebase --autostash. Finally I successfully commit, then I copy paste the URL returned by GitHub to open a PR. Then I merge the PR and run git ma to go back to the primary branch, which is an alias to ma = "!f() {git checkout $(git primary) &&git pull;}; f".
This workflow, I think, is pretty familiar for anyone working with GitHub a lot. Now you'll notice I'm not saying git because almost nothing I'm doing has anything to do with git. There's no advantage to my repo being local to my machine, because everything I need to actually merge and deploy code lives on GitHub. The CI runs there, the approval process runs there, the monitoring of the CI happens there, the injection of secrets happens there. If GitHub is down my local repo does, effectively, nothing.
My source of truth is always remote, which means I pay the price for git complexity locally but I don't benefit from it. At most jobs:
You can't merge without GitHub (PRs are the merge mechanism)
You can't deploy without GitHub (Actions is the deployment trigger)
You can't get approval without GitHub (code review lives there)
Your commits are essentially "drafts" until they exist on GitHub
This means the following is also true:
You never work disconnected intentionally
You don't use local branches as long-lived divergent histories
You don't merge locally between branches (GitHub PRs handle this)
You don't use git log for archaeology — you use GitHub's blame/history UI (I often use git log personally but I have determined I'm in the minority on this).
Almost all the features of git are wasted on me in this flow. Now because this tool serves a million purposes and is designed to operate in a way that almost nobody uses it for, we all pay the complexity price of git and never reap any of the benefits. So instead I keep having to add more aliases to paper over the shortcomings of git.
These are all the aliases I use at least once a week.
[alias]
up = pull --rebase --autostash
l = log --pretty=oneline -n 20 --graph --abbrev-commit
# View the current working tree status using the short format
s = status -s
p = !"git pull; git submodule foreach git pull origin master"
ca = !git add -A && git commit -av
# Switch to a branch, creating it if necessary
go = "!f() { git checkout -b \"$1\" 2> /dev/null || git checkout \"$1\"; }; f"
# Show verbose output about tags, branches or remotes
tags = tag -l
branches = branch -a
remotes = remote -v
dm = "!git branch --merged | grep -v '\\*' | xargs -n 1 git branch -d"
contributors = shortlog --summary --numbered
st = status
primary = "!f() { \
git branch -a | \
sed -n -E -e '/remotes.origin.ma(in|ster)$/s@remotes/origin/@@p'; \
}; f"
# Switch to main or master, whichever exists, and update it.
ma = "!f() { \
git checkout $(git primary) && \
git pull; \
}; f"
mma = "!f() { \
git ma && \
git pull upstream $(git primary) --ff-only && \
git push; \
}; f"
Enter GitButler CLI
Git's offline-first design creates friction for online-first workflows, and GitButler CLI eliminates that friction by being honest about how we actually work.
(Edit: I forgot to add this disclaimer. I am not, nor have ever been an employee/investor/best friends with anyone from GitButler. They don't care that I've written this and I didn't communicate with anyone from that team before I wrote this.)
So let's take the most basic command as an example. This is my flow that I do 2-3 times a day without my aliases.
git checkout main
git pull
git checkout -b my-feature
# or if you're already on a branch:
git pull --rebase --autostash
git status
I do this because git can't make assumptions about the state of the world.
Your local repo might be offline for days or weeks
The "remote" might be someone else's laptop, not a central server
Divergent histories are expected and merging is a deliberate, considered act
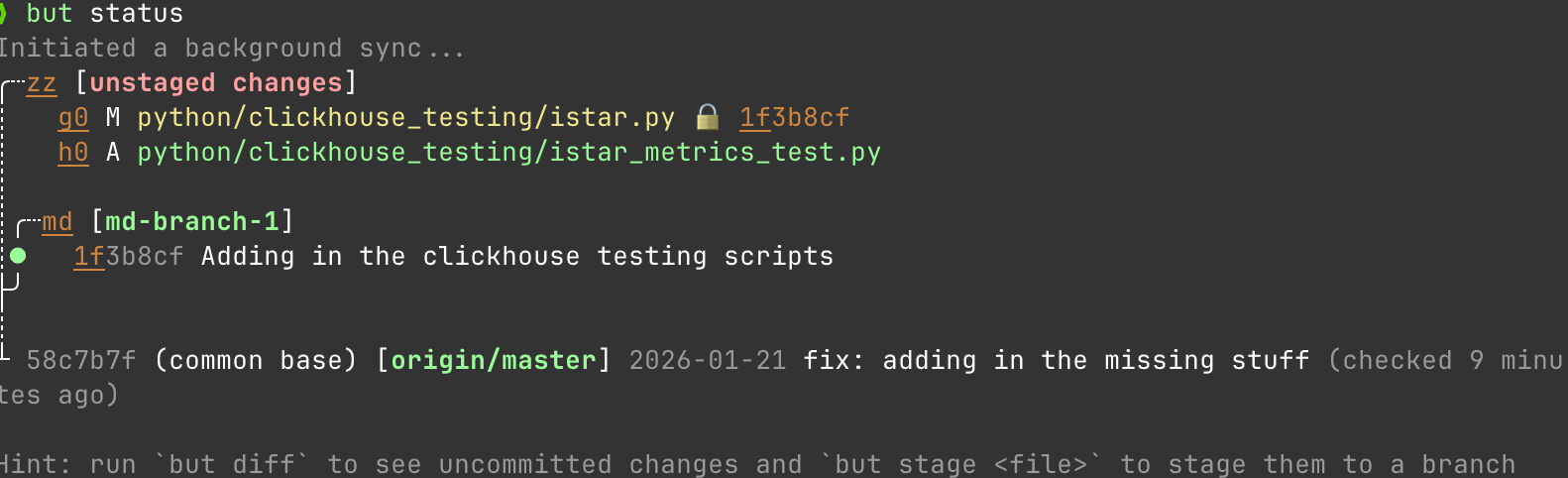
However because GitButler is designed with the assumption that I'm working online, we can skip a lot of this nonsense.
It's status command understands that there is always a remote main that I care about and that when I run a status that I need to understand my status relative to the remote main as it exists right now. Not how it existed the last time I remembered to pull.
However this is far from the best trick it has up its sleeve.
Parallel Branches: The Problem Git Can't Solve
You're working on a feature, notice an unrelated bug, and now you have to stash, checkout, fix, commit, push, checkout back, stash pop. Context switching is expensive and error-prone.
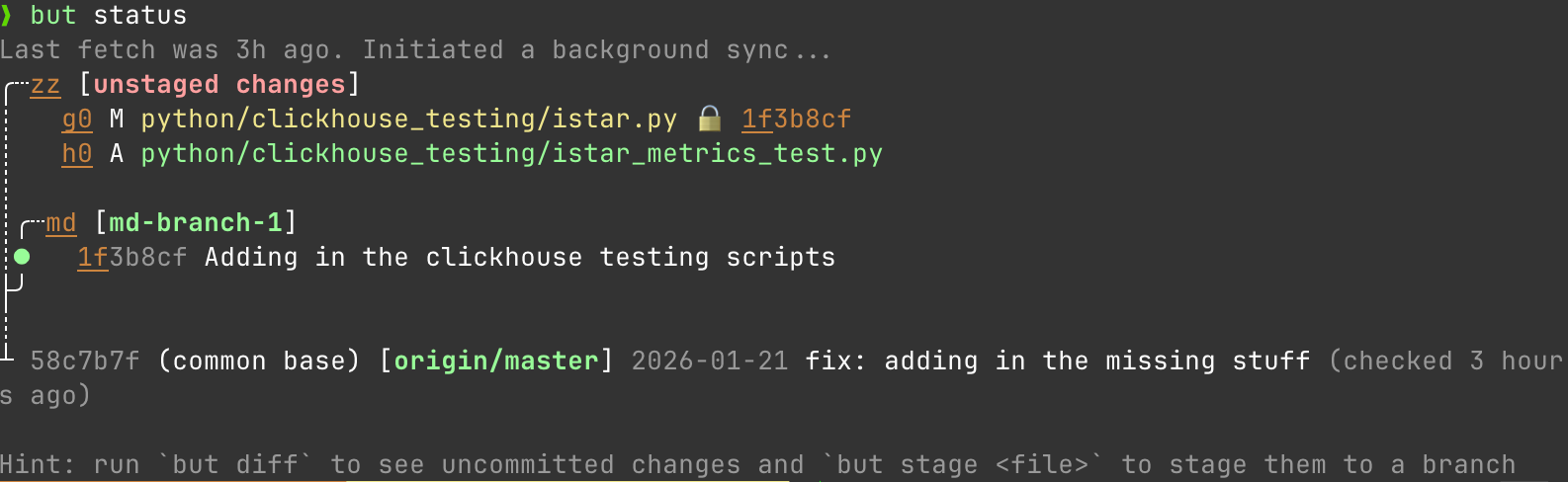
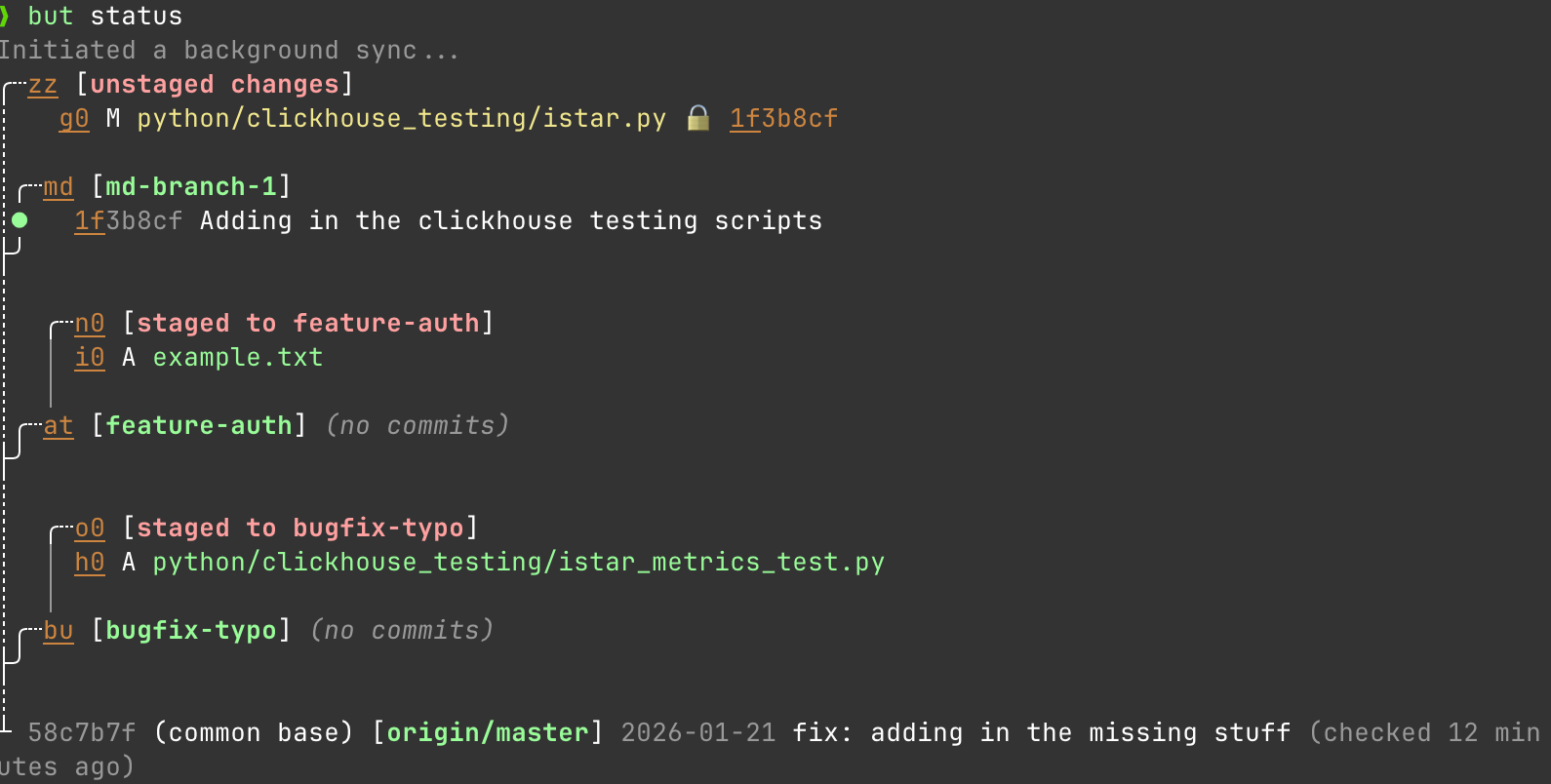
GitButler effectively hacks a solution into git that fixes this with multiple branches applied simultaneously. Assign files to different branches without leaving your workspace. What do I mean by that. Let's start again with my status
Great looks good. Alright so lets say I make 2 new branches. I'm working on a new feature for adding auth and while I'm working on that, I see a typo I need to fix in a YAML.
I can work on both things at the same time:
but stage istar_metrics_text.py feature-auth
but stage example.txt bugfix-typo
And easily commit to both at the same time without doing anything weird.
Stacked PRs Without the Rebase Nightmare
Stacked PRs are the "right" way to break up large changes so people on your team don't throw up at being asked to review 2000 lines, but Git makes them miserable. When the base branch gets feedback, you have to rebase every dependent branch, resolve conflicts, force-push, and pray. Git doesn't understand branch dependencies. It treats every branch as independent, so you have to manually maintain the stack.
GitButler solves this problem with First-class stacked branches. The dependency is explicit, and updates propagate automatically.
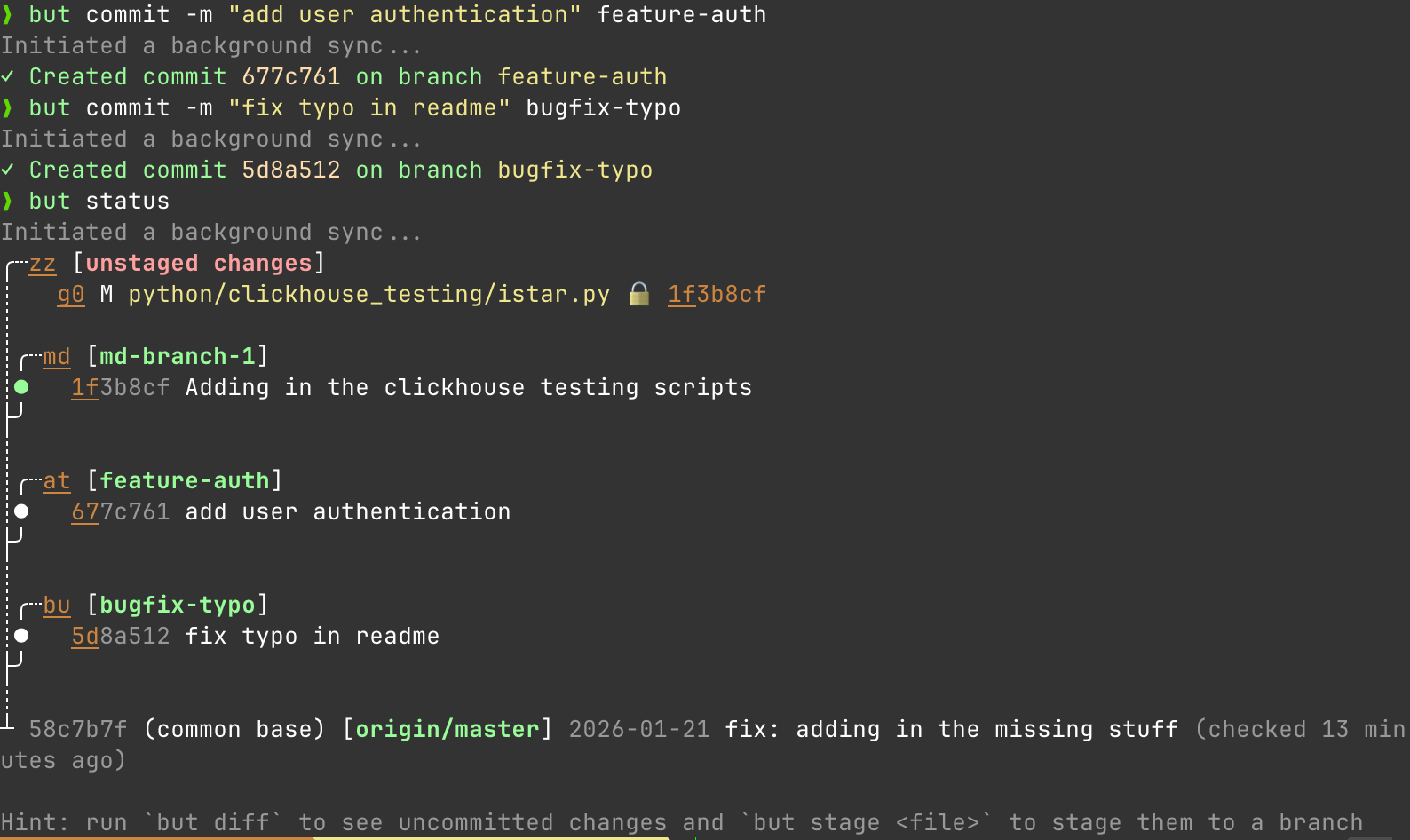
So what do I mean. Let's say I make a new API endpoint in some Django app. First I make the branch.
but branch new api-endpoints
# Then add my stuff to it
but commit -m "add REST endpoints" api-endpoints
# Create a stacked branch on top
but branch new --anchor api-endpoints api-tests
So let's say I'm working on the api-endpoints branch and get some good feedback on my PR. It's easy to resolve the comments there while leaving my api-tests branched off this api-endpoints as a stacked thing that understands the relationship back to the first branch as shown here.
In practice this is just a much nicer way of dealing with a super common workflow.
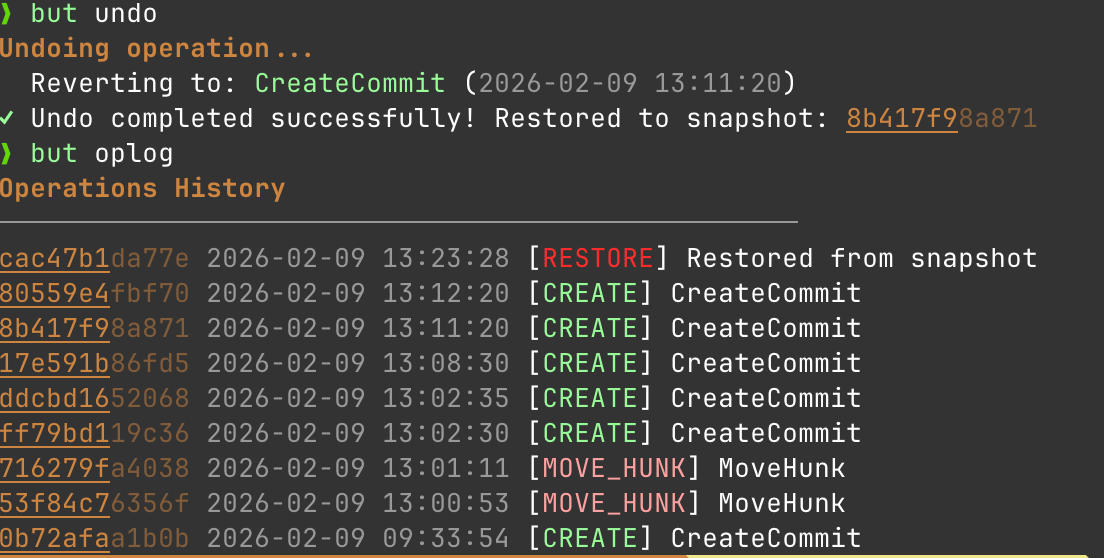
Easy Undo
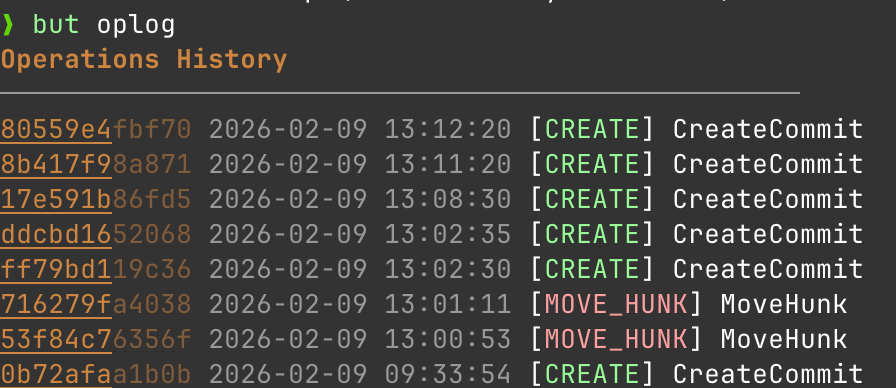
Maybe the most requested feature from new git users I encounter is an easier undo. When you mess up in Git, recovery means diving into git reflog, understanding the cryptic output, and hoping you pick the right HEAD@{n}. One wrong move and you've made it worse.
GitButlers oplog is just easier to use. So the basic undo functionality is super simple to understand.
but undo rolls me back one operation.
To me the mental model of a snapshot makes a lot more sense than the git history model. I do an action, I want to undo that action. This is better than the git option of:
git log --oneline # figure out what you committed
git reset --soft HEAD~1 # undo commit, keep changes staged
git stash # stash the changes
git checkout correct-branch # switch branches
git stash pop # restore changes (hope no conflict)
git add . # re-stage
git commit -m "message" # recommit
Very exciting tool
I've been using GitButler in my daily work since I got the email that the CLI was available and I've really loved it. I'm a huge fan of what this team is doing to effectively remodel and simplify Git operations in a world where almost nobody is using it in the way the tool was originally imagined to be used. I strongly encourage folks go check it out for free at: https://docs.gitbutler.com/cli-guides/cli-tutorial/tutorial-overview. It does a ton of things (like help you manage PRs) that I didn't even touch on here.
One amusing thing about following tech news is how often the tech community makes a bold prediction or assertion, only to ultimately be completely wrong. This isn't amusing in a "ha ha, we all make mistakes" kind of way. It's amusing in the way that watching someone confidently stride into a glass door is amusing. You feel bad, but also, they really should have seen that coming.
Be it VR headsets that would definitely replace reality by 2018, or self-driving cars in every driveway "within five years" (a prediction that has been made every five years since 2012), we have a remarkable talent for making assumptions about what consumers will like and value without having spent a single goddamn minute listening to those same consumers. It's like a restaurant critic reviewing a steakhouse based entirely on the menu font.
So when a friend asked me what I thought about "insert new revolutionary technology that will change everything" this week, my brain immediately jumped to "it'll be like 3D printers and Warhammer." This comparison made sense in the moment, as we were currently playing a game of Warhammer 40,000, surrounded by tiny plastic soldiers and the faint musk of regret. But I think, after considering it later, it might make sense for more people as well—a useful exercise in tech enthusiasm versus real user wants and needs.
Or, put another way: a cautionary tale about people who have never touched grass telling grass-touchers how grass will work in the future.
Miniatures and Printers
One long-held belief among tech bros has been the absolute confidence that 3D printers would, at some point, disrupt. Exactly what they would disrupt wasn't 100% clear. Disruption, in Silicon Valley parlance, is less a specific outcome and more a vibe—a feeling that something old and profitable will soon be replaced by something new and unprofitable that will somehow make everyone rich. A common example trotted out was one of my favorite hobbies: tabletop wargaming. More specifically, the titan of the industry, Warhammer 40,000.
Every time a new 3D printer startup graced the front page of Hacker News, this proclamation would echo from the comments section like a prophecy from a very boring oracle: "This will destroy Games Workshop." Reader, it has not destroyed Games Workshop. Games Workshop is doing fine. Games Workshop will be selling overpriced plastic crack to emotionally vulnerable adults long after the sun has consumed the Earth.
It doesn't seem like they're dying yetIt's even more dorky in real life
For those who had friends in high school—and I'm not being glib here, this is a genuine demographic distinction—40k is a game where two or more players invest roughly $1,000 to build an army of small plastic figures. You then trim excess plastic with a craft knife (cutting yourself at least twice, this is mandatory), prime them, paint them over the course of several months, and then carefully transport them to an LGS (local game shop) in foam-lined cases that cost more than some people's luggage.
Another fellow dork will then play you on a game board roughly the size of a door, covered in fake terrain that someone spent 40 hours making to look like a bombed-out cathedral. You will both have rulebooks with you containing as many pages as the Bible and roughly as open to interpretation. Wars have been started over less contentious texts.
To put 40k in some sort of nerd hierarchy, imagine a game shop. At the ground level of this imaginary shop are Magic: The Gathering and Pokémon TCG games. Yes, these things are nerdy, but it's not that deep into the swamp. It's more of a gentle wade. You start with Pokémon at age 10, burn your first Tool CD at 14, and then sell your binder of 'mons to fund your Magic habit. This is the natural order of things.
Deeper into the depths, maybe only playing at night like creatures who have evolved beyond the need for vitamin D, are your TTRPGs (tabletop RPGs). The titan of the industry is Dungeons & Dragons, but there is always some new hotness nipping at its heels, designed by someone who thought D&D wasn't quite complicated enough. TTRPGs are cheap to attempt to disrupt—you basically need "a book"—so there are always people trying. These are the folks with thick binders, sacks of fancy dice made from materials that should not be made into dice, and opinions about "narrative agency."
Near the bottom, almost always in the literal basement of said shop, are the wargame community. We are the Morlocks of this particular H.G. Wells situation.
I, like a lot of people, discovered 40k at a dark time in my life. My college girlfriend had cheated on me, and I had decided to have a complete mental breakdown over this failed relationship that was doomed well before this event. The cheating was less a cause and more a symptom, like finding mold on bread that was already stale. Honestly, in retrospect, hard to blame her. I was being difficult. I was the kind of difficult where your friends start sentences with "Look, I love you, but..."
Late at night, I happened to be driving my lime green Ford Probe past my local game shop. The Ford Probe, for those unfamiliar, was a car designed by someone who had heard of cars but had never actually seen one. It was the automotive equivalent of a transitional fossil. I loved it the way you love something that confirms your worst suspicions about yourself.
There, through the shop window, I saw people hauling some of the strangest items out of their trunks. Half-destroyed buildings. Thousands of tiny little figures. Giant robots the size of a small cat with skulls for heads. One man was carrying what appeared to be a ruined spaceship made entirely of foam and spite.
I pulled over immediately.
Look at that handsome monster
The owner, who knew me from playing Magic, seemed neither surprised nor pleased to see me. This was his default state. Running a game shop for 20 years will do that to a person. "They're in the basement," he said, in the mostly dark game shop, the way someone might say "the body's in the basement" in a very different kind of establishment.
I descended the rickety wooden stairs to a large basement lit by three naked bulbs hanging from cords. The aesthetic was "serial killer's workspace" meets "your uncle's unfinished renovation project." It was perfect.
Before me were maybe a dozen tables littered with plastic. Some armies had many bug-like things, chitinous and horrible. Others featured little skeletons or robots. There were tape measures everywhere and people throwing literal handfuls of small six-sided dice at the table with the intensity of gamblers who had nothing left to lose. Arguments broke out over millimeters. Someone was consulting a rulebook with the desperation of a lawyer looking for a loophole.
I was hooked immediately.
40k is the monster of wargaming specifically because of a few genius decisions by Games Workshop, the creators—a British company that has somehow figured out how to print money by selling plastic and lore about a fascist theocracy in space. It's a remarkable business model.
The game looks more complicated to play than it is. Especially now, in the 10th edition, the core rules don't take long to learn. However, there is a lot of depth to the individual options available to each army that take a while to master. So it hits that sweet spot of being fast to onboard someone onto while still providing frightening amounts of depth if you're the kind of person who finds "frightening amounts of depth" appealing rather than exhausting. I am that kind of person. This explains a lot about my life.
The community is incredible. When I moved from Chicago to Denmark, it took me less than three days to find a local 40k game. Same thing when I moved from Michigan to Chicago. The age and popularity of the game means it is a built-in community that follows you basically around the world. Few other properties have this kind of stickiness. It's like being a Deadhead, except instead of following a band, you're following a shared delusion that tiny plastic men matter. They do matter. Shut up.
Cool miniatures. They look nice. They're fun to paint and put together. They're complicated without being too annoying. This is the part that 3D printers are supposed to help with.
The Proxy Problem
Since the beginning of the game, 40k casual games have allowed proxies. Proxies are stand-ins for specific units that you need for an army but don't have. Why don't you have them? Excellent question. Let me tell you about Games Workshop's relationship with its customers.
Games Workshop has always played a lot of games with inventory. Often releases will have limited supply, or there are weird games with not fulfilling the entire order that a game shop might make. Even when they switched from metal to plastic miniatures, the issues persisted. This has been the source of conspiracy theories since the very beginning—whispers of artificial scarcity, of deliberate shortages designed to create FOMO among people who were already deeply susceptible to FOMO because they collect tiny plastic soldiers.
Whether the conspiracy theories are true is almost beside the point. The feeling of scarcity is real, and feelings, as any therapist will tell you, are valid. Even the stupid ones.
So players had proxies. Anything from a Coke can to another unit entirely. Basically, if it had the same size base and roughly the same height, most people would consider it allowable. "This empty Red Bull can is my Dreadnought." Sure. Fine. We've all been there.
This is where I first started to see 3D-printed miniatures enter the scene.
Similar to most early tech products, the first FDM 3D-printed miniatures I saw were horrible. The thick, rough edges and visible layer lines were not really comparable to the professional product, even from arm's length. They looked like someone had described a Space Marine to a printer that was also drunk. But they were totally usable as a proxy and better than a Coke can. The bar, as they say, was low.
But the technology continued to get better and cheaper and, as predicted by tech people, I started to notice more and more interest in 3D printing among people at the game stores. When I first encountered a resin 3D-printed army at the table, I'll admit I was intrigued. This person had basically fabricated $3,000 worth of hard-to-get miniatures out of thin air and spite.
This was supposed to be the big jumping-off point. The inflection moment. There were a lot of discussions at the table about how soon we wouldn't even have game shops with inventory! They'd be banks of 3D printers that we would all effortlessly use to make all the minis we wanted! The future was here, and it smelled like resin fumes!
3D Printing Misses
Printing a bunch of miniatures off a resin 3D printer quickly proved to have a lot of cracks in this utopian plan. Even a normal-sized mini took hours to print. That wouldn't be so bad, except these printers couldn't just live anywhere in your apartment. They're not like a Keurig. You can't just put them on your kitchen counter and forget about them.
When I was invited to watch someone print off minis with a resin 3D printer, it reminded me a lot of the meth labs in my home state of Ohio. And I don't mean that as hyperbole. I mean there were chemicals, ventilation hoods, rubber gloves, and a general atmosphere of "if something goes wrong here, it's going to go very wrong." The guy giving me the tour had safety goggles pushed up on his forehead. He was wearing an apron. At one point, he said the phrase "you really don't want to get this on your skin" with the casual tone of someone who had definitely gotten it on his skin.
In practice, the effort to get the STL files, add supports, wash off the models with isopropyl alcohol, remove supports without snapping off tiny arms, and finally cure the mini in UV lights was exponentially more effort than I'm willing to invest. And I say this as someone who has painted individual eyeballs on figures smaller than my thumb. I have a high tolerance for tedious bullshit. This exceeded it.
Why?
Before I start, I first want to say I don't dislike the 3D printing community. I think it's great they're supporting smaller artists. I love that they found a hobby inside of a hobby, like those Russian nesting dolls but for people who were already too deep into something. I will gladly play against their proxy armies any day of the week.
But people outside of the hobby proclaiming that this is the "future" are a classic example of how they don't understand why we're doing the activity in the first place. It's like watching someone who has never cooked explain how meal replacement shakes will eliminate restaurants. You're not wrong that it's technically more efficient. You're just missing the entire point of the experience.
The reason why Games Workshop continues to have a great year after year—despite prices that would make a luxury goods executive blush, despite inventory issues, despite a rulebook that changes often enough to require a subscription service—is because of this fundamental misunderstanding.
Players invest a lot of time and energy into an army. You paint them. You decorate the plastic bases with fake grass and tiny skulls. You learn their specific rules and how to use them. You develop opinions about which units are "good" and which are "trash" and you will defend these opinions with the fervor of a religious convert. Despite the eternal complaints about the availability of inventory, the practical reality is that most people can only keep a pipeline of one or maybe two armies going at once.
The bottleneck isn't acquiring plastic. The bottleneck is everything else.
So let's do the math on this. You buy a resin 3D printer. All the supplies. You get a spot in your house where you can safely operate it—which means either a garage, a well-ventilated spare room, or a relationship-ending negotiation with whoever you live with. You find or buy all the STLs you need. Let's say they all have supports in the files, so you just need to print them off. Best-case scenario.
Let's say we break even around 50-75 infantry and a few larger models. This is over the raw cost of materials, but we need to factor in the space in your house it takes up, plus there's a learning curve with figuring out how to do it. You also need to invest a lot of time getting these files for printing and finding the good ones. For the sake of keeping this simple, let's just assume the actual printing process goes awesome. No failed prints. No supports that fuse to the model. No discovering that your file was corrupted after six hours of printing. Fantasy land.
Here's the thing: getting the raw plastic minis is not the time-consuming part.
First, you need to paint them. I take about two hours to paint each model, and I'm far from the best painter out there. I'm solidly in the "looks good from three feet away" category, which is also how I'd describe my general appearance. Vehicles take longer because they're bigger—maybe 10-20 hours for one of those. We're talking somewhere in the ballpark of 150 hours to paint everything that you need to paint for a standard army.
Now don't get me wrong, I love painting. But I'm a 38-year-old with a child and a full-time job. Finding 150 hours for anything that isn't work, childcare, or sleep requires the kind of calendar Tetris that would make a project manager weep. It is a massive investment of time to get an army on the table, even if you remove the financial element of buying the minis entirely.
Frankly, the money I pay to Games Workshop is the easiest part of the entire process. Often the box will be lovingly stacked on top of other sealed mini boxes—a pile of shame, we call it—until I can start the process of even hoping to catch up. I have boxes I bought during the Obama administration. They're still sealed. They judge me.
But okay, let's say we get them all painted. What's next?
Next comes "learn how the army works." There is a ton of flexibility to each army in 40k and how they work and operate. It takes a bit of research and time to figure out what they all do, which is something you are 100% expected to know cover to cover when you show up to play. It's not my job to know what your army can and cannot do. If you show up not knowing your own rules, you will be eaten alive, and you will deserve it.
So what I saw with the 3D printing crowd felt a lot like the "Year of the Linux Desktop" crowd. Every year they would proclaim that soon we'd all get on board with their vision. They would print off an incredibly impressive army with all the hard-to-find minis that were sold once at a convention in 1997. They'd get the army "painted" to some definition of painted—and I'm using those quotation marks with malice—get on the table, and then play effectively that one army the same as the rest of us.
The printer didn't give them more time. It didn't give them more skill. It just gave them more unpainted plastic, which, brother, I have plenty of already.
For those in the 3D printing crowd who weren't big into playing, just painting, part of the point is showing off your incredible work to everyone else. Except nobody wants to see a 3D-printed forgery of an official model. It's like showing up to a car show with a kit car that looks like a Ferrari. Sure, it's impressive in its own way, but it's not really a Ferrari, and everyone knows it, and now we're all standing around pretending we don't know it, and it's uncomfortable for everyone.
Once someone figured out one of your minis was 3D printed, shops generally wouldn't feature it in their display cases. So there was no reason for people who were going to put in 10+ hours per model to skip paying for the official real models. If you're going to invest that much time, you want the real thing. You want the little Games Workshop logo on the base. You want to be able to say "yes, I paid $60 for this single figure" with the quiet dignity of someone who has made peace with their choices.
"Well then the shops can just sell the STLs and do the printing there!"
This shows me you haven't spent a lot of time in these shops.
Game shops need to carry a ton of inventory all the time, and a lot of their sales are impulse purchases. I see a mini I wouldn't typically be interested in, but it's done and ready, and I'm weak, and now I own it. That's the business model. They also operate on relatively thin margins—these aren't Apple Stores, they're labors of love run by people who got into this because they loved games and are now slowly being crushed by commercial rent and distributor minimums.
It's just not feasible for them to print minis on demand and have enough staff to keep an eye on all the printing. Plus, tabletop wargaming isn't their major revenue generator anyway—it's card games like Pokémon and Magic. The wargamers in the basement are a bonus, not the main attraction. We're the weird cousins who show up to Thanksgiving and everyone tolerates us because we're family.
The Moral of the Story
At the end of the day, the 3D printing proclamation that it would disrupt my hobby ended up being a whole lot of nothing. A series of reasonable mistakes were made by people enthusiastic about the technology, resulting in the current situation where every year is the year that all of this will get disrupted. Any day now. Just you wait.
They looked at the price of miniatures and saw inefficiency. They looked at the scarcity and saw opportunity. What they didn't see was that the price and the scarcity were almost beside the point. The hobby isn't about acquiring plastic. The hobby is about what you do with the plastic after you acquire it. The hobby is about the 150 hours of painting. The hobby is about the arguments over rules interpretations. The hobby is about descending into a basement lit by three naked bulbs and finding your people.
You can't 3D print that.
So the next time someone tells you that some new technology is going to "disrupt" something you love, ask yourself: do they actually understand why people love it? Do they understand the irrational, inefficient, deeply human reasons people engage with this thing? Or are they just looking at a spreadsheet and seeing numbers that don't make sense to them?
Because if it's the latter, you can probably ignore them. They'll be wrong. They're almost always wrong.
In the meantime, you can find me in the basement, losing match after match, surrounded by tiny plastic soldiers I've spent hundreds of hours painting, playing a game that makes no sense to anyone who hasn't given themselves over to it completely.
It's not efficient. It's not optimized. It's not disrupting anything.
When I wrote the backend for my Firefox time-wasting extension (here), I assumed I was going to be setting up Postgres. My setup is boilerplate and pretty boring, with everything running in Docker Compose for personal projects and then persistence happening in volumes.
However when I was working with it locally, I obviously used SQLite since that's always the local option that I use. It's very easy to work with, nice to back up and move around and in general is a pleasure to work with. As I was setting up the launch, I realized I really didn't want to set up a database. There's nothing wrong with having a Postgres container running, but I'd like to skip it if its possible.
Can you run SQLite for many readers and writers?
So my limited understanding of SQLite before I started this was "you can have one writer and many readers". I had vaguely heard of SQLite "WAL" but my understanding of WAL is more in the context of shipping WAL between database servers. You have one primary, many readers, you ship WAL to from the primary to the readers and then you can promote a reader to the primary position once it has caught up on WAL.
My first attempt at setting up SQLite for a REST API died immediately in exactly this way.
This seems to be caused by SQLite having a rollback journal and using strict locking. Which makes perfect sense for the use-case that SQLite is typically used for, but I want to abuse that setup for something it is not typically used for.
First Pass
So after doing some Googling I ended up with these as the sort of "best recommended" options. I'm 95% sure I copy/pasted the entire block.
Switches SQLite from rollback journal to Write-Ahead Logging (WAL)
Default behavior is Write -> Copy original data to journal -> Modify database -> Delete journal.
WAL mode is Write -> Append changes to WAL file -> Periodically checkpoint to main DB
synchronous=NORMAL
So here you have 4 options to toggle for how often SQLite syncs to disk.
OFF is SQlite lets the OS handle it.
NORMAL is the SQLite engine still syncs, but less often than FULL. WAL mode is safe from corruption with NORMAL typically.
FULL uses the Xsync method of the VFS (don't feel bad I've never heard of it before either: https://sqlite.org/vfs.html) to ensure everything is written to disk before moving forward.
EXTRA: I'm not 100% sure what this exactly does but it sounds extra. "EXTRA synchronous is like FULL with the addition that the directory containing a rollback journal is synced after that journal is unlinked to commit a transaction in DELETE mode. EXTRA provides additional durability if the commit is followed closely by a power loss. Without EXTRA, depending on the underlying filesystem, it is possible that a single transaction that commits right before a power loss might get rolled back upon reboot. The database will not go corrupt. But the last transaction might go missing, thus violating durability, if EXTRA is not set."
busy_timeout = please wait up to 60 seconds.
cache_size this one threw me for a loop. Why is it a negative number?
If you set it to a positive number, you mean pages. SQLite page size is 4kb by default, so 2000 = 8MB. A negative number means KB which is easier to reason about than pages.
I don't really know what a "good" cache_size is here. 64MB feels right given the kind of data I'm throwing around and how small it is, but this is guess work.
temp_store = write to memory, not disk. Makes sense for speed.
Now this is under heavy load (simulating 1000 active users making a lot of requests at the same time, which is more than I've seen), but still this is pretty bad. The cause of it was, of course, my fault.
Blacklist logic
My "blacklist" is mostly just sites that publish a ton of dead links. However I had the setup wrong and was making a database query per website to see if it matched the black list. Stupid mistake. Once I fixed that.
Great! Or at least "good enough from an unstable home internet connection with some artificial packet loss randomly inserted".
Conclusion
So should you use SQLite as the backend database for a FastAPI setup? Well it depends on how many users you are planning on having. Right now I can handle between 1000 and 2000 requests per second if they're mostly reads, which is exponentially more than I will need for years of running the service. If at some point in the future that no longer works, it's thankfully very easy to migrate off of SQLite onto something else. So yeah overall I'm pretty happy with it as a design.
I don't like RSS readers. I know, this is blasphemous especially on a website where I'm actively encouraging you to subscribe through RSS. As someone writing stuff, RSS is great for me. I don't have to think about it, the requests are pretty light weight, I don't need to think about your personal data or what client you are using. So as a protocol RSS is great, no notes.
However as something I'm going to consume, it's frankly a giant chore. I feel pressured by RSS readers, where there is this endlessly growing backlog of things I haven't read. I rarely want to read all of a websites content from beginning to end, instead I like to jump between them. I also don't really care if the content is chronological, like an old post about something interesting isn't less compelling to me than a newer post.
What I want, as a user experience, is something akin to TikTok. The whole appeal of TikTok, for those who haven't wasted hours of their lives on it, is that I get served content based on an algorithm that determines what I might think is useful or fun. However what I would like is to go through content from random small websites. I want to sit somewhere and passively consume random small creators content, then upvote some of that content and the service should show that more often to other users. That's it. No advertising, no collecting tons of user data about me, just a very simple "I have 15 minutes to kill before the next meeting, show me some random stuff."
In this case the "algorithm" is pretty simple: if more people like a thing, more people see it. But with Google on its way to replacing search results with LLM generated content, I just wanted to have something that let me play around with the small web the way that I used to.
There actually used to be a service like this called StumbleUpon which was more focused on pushing users towards popular sites. It has been taken down, presumably because there was no money in a browser plugin that sent users to other websites whose advertising you didn't control.
TL;DR
You can go download the Firefox extension now and try this out and skip the rest of this if you want. https://timewasterpro.xyz/ If you hate it or find problems, let me know on Mastodon. https://c.im/@matdevdug
Functionality
So I wanted to do something pretty basic. You hit a button, get served a new website. If you like the website, upvote it, otherwise downvote it. If you think it has objectionable content then hit report. You have to make an account (because I couldn't think of another way to do it) and then if you submit links and other people like it, you climb a Leaderboard.
On the backend I want to (very slowly so I don't cost anyone a bunch of money) crawl a bunch of RSS feeds, stick the pages in a database and then serve them up to users. Then I want to track what sites get upvotes and return those more often to other users so that "high quality" content shows up more often. "High quality" would be defined by the community or just me if I'm the only user.
It's pretty basic stuff, most of it copied from tutorials scattered around the Internet. However I really want to drive home to users that this is not a Serious Thing. I'm not a company, this isn't a new social media network, there are no plans to "grow" this concept beyond the original idea unless people smarter than me ping with me ideas. So I found this amazing CSS library: https://sakofchit.github.io/system.css/
The Apple's System OS design from the late-80s to the early 90s was one of my personal favorites and I think would send a strong signal to a user that this is not a professional, modern service.
Great, the basic layout works. Let's move on!
Backend
So I ended up doing FastAPI because it's very easy to write. I didn't want to spend a ton of time writing the API because I doubt I nailed the API design on the first round. I use sqlalchemy for the database. The basic API layout is as follows:
admin - mostly just generating read-only reports of like "how many websites are there"
leaderboard - So this is my first attempt at trying to get users involved. Submit a website that other people like? Get points, climb leaderboard.
The source for the RSS feeds came from the (very cool) Kagi small web Github. https://github.com/kagisearch/smallweb. Basically I assume that websites that have submitted their RSS feeds here are cool with me (very rarely) checking for new posts and adding them to my database. If you want the same thing as this does, but as an iFrame, that's the Kagi small web service.
The scraping work is straightforward. We make a background worker, they grab 5 feeds every 600 seconds, they check for new content on each feed and then wait until the 600 seconds has elapsed to grab 5 more from the smallweb list of RSS feeds. Since we have a lot of feeds, this ends up look like we're checking for new content less than once a day which is the interval that I want.
Then we write it out to a sqlite database and basically track "has this URL been reported", if so, put it into a review queue and then how many times this URL has been liked or disliked. I considered a "real" database but honestly sqlite is getting more and more scalable every day and its impossible to beat the immediate start up and functionality. Plus very easy to back up to encrypted object storage which is super nice for a hobby project where you might wipe the prod database at any moment.
In terms of user onboarding I ended up doing the "make an account with an email, I send a link to verify the email". I actually hate this flow and I don't really want to know a users email. I never need to contact you and there's not a lot associated with your account, which makes this especially silly. I have a ton of email addresses and no real "purpose" in having them. I'd switch to Login with Apple, which is great from a security perspective but not everybody has an Apple ID.
I also did a passkey version, which worked fine but the OSS passkey handling was pretty rough still and most people seem to be using a commercial service that handled the "do you have the passkey? Great, if not, fall back to email" flow. I don't really want to do a big commercial login service for a hobby application.
Auth is a JWT, which actually was a pain and I regret doing it. I don't know why I keep reaching for JWTs, they're a bad user experience and I should stop.
Can I just have the source code?
I'm more than happy to release the source code once I feel like the product is in a somewhat stable shape. I'm still ripping down and rewriting relatively large chunks of it as I find weird behavior I don't like or just decide to do things a different way.
In the end it does seem to do whats on the label. We have over 600,000 individual pages indexed.
So how is it to use?
Honestly I've been pretty pleased. But there are some problems.
First I couldn't find a reliable way of switching the keyboard shortcuts to be Mac/Windows specific. I found some options for querying platform but they didn't seem to work, so I ended up just hardcoding them as Alt which is not great.
The other issue is that when you are making an extension, you spend a long time working with these manifests.json. The specific part I really wasn't sure about was:
I'm not entirely sure if that's all I'm doing? I think so from reading the docs.
Anyway I built this mostly for me. I have no idea if anybody else will enjoy it. But if you are bored I encourage you to give it a try. It should be pretty light weight and straight-forward if you crack open the extension and look at it. I'm not loading any analytics into the extension so basically until people complain about it, I don't really know if its going well or not.
Future stuff
I need to sort stuff into categories so that you get more stuff in genres you like. I don't 100% know how to do that, maybe there is a way to scan a website to determine the "types" of content that is on there with machine learning? I'm still looking into it.
There's a lot of junk in there. I think if we reach a certain number of downvotes I might put it into a special "queue".
I want to ensure new users see the "best stuff" early on but there isn't enough data to determine "best vs worst".
I wish there were more independent photography and science websites. Also more crafts. That's not really a "future thing", just me putting a hope out into the universe. Non-technical beta testers get overwhelmed by technical content.
Once a month I will pull down the latest docker images for this server and update the site. The Ghost CMS team updates things at a pretty regular pace so I try to not let an update sit for too long.
With this last round I suddenly found myself locked out of my Ghost admin panel. I was pretty confident that I hadn't forgotten my password and when I was looking at the logs, I saw this pretty spooky error.
blog-1 | [2025-10-15 11:36:29] ERROR "GET /ghost/api/admin/users/me/?include=roles" 403 188ms
blog-1 |
blog-1 | Authorization failed
blog-1 |
blog-1 | "Unable to determine the authenticated user or integration. Check that cookies are being passed through if using session authentication."
blog-1 |
blog-1 | Error ID:
blog-1 | 5b3ec250-aa84-11f0-bb51-b7057fc0f6b0
blog-1 |
blog-1 | ----------------------------------------
blog-1 |
blog-1 | NoPermissionError: Authorization failed
blog-1 | at authorizeAdminApi (/var/lib/ghost/versions/5.130.5/core/server/services/auth/authorize.js:33:25)
blog-1 | at Layer.handle [as handle_request] (/var/lib/ghost/versions/5.130.5/node_modules/express/lib/router/layer.js:95:5)
blog-1 | at next (/var/lib/ghost/versions/5.130.5/node_modules/express/lib/router/route.js:149:13)
blog-1 | at authenticate (/var/lib/ghost/versions/5.130.5/core/server/services/auth/session/middleware.js:55:13)
blog-1 | at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
blog-1 |
blog-1 | [2025-10-15 11:36:29] ERROR "GET /ghost/api/admin/users/me/?include=roles" 403 13ms
So Ghost is a good CMS system, but it can be a little bit slow under load from automated scraping from RSS readers. I want to cache everything that I can with Nginx, so I use Nginx to store a lot of that junk. My configuration is not too terribly clever and has worked up to this point.
The basic point is to get caching on the public content and then definitely NOT cache the ghost admin panel. After some testing, I confirmed this seemed to all work. But I was still locked out.
Now I have transactional email set up, but just looking at the error it seemed to feel related. So I added: security__staffDeviceVerification: false to my docker-compose file to disable this new feature and then blamo, suddenly works fine.
So if you are locked out of your Docker CMS admin panel, disable this (temporarily hopefully because it's a good feature) to let you continue to log in, debug your transactional email and then turn it back on. Hope that helps.
Greenland is a complicated topic here in Denmark. The former colony that is still treated a bit like a colony is something that inspires a lot of emotions. Greenland has been subjected to a lot of unethical experiments by Denmark, from taking their kids to wild experiments in criminal justice. But there is also a genuine pride a lot of people have here for the place and you run into Danes who grew up there more often than I would have guessed.
When the idea of going to Greenland was introduced to me, I was curious. Having lived in Denmark for awhile, you hear a lot about the former colony and its 55,000 residents. We were invited by a family that my wife was close with growing up and is Danish. They wanted to take their father back to see the place he had spend some time in during his 20s and had left quite an impression. A few drinks in, I said "absolutely let's do it", not realizing we had already committed to going and I had missed the text message chain.
A few weeks before I went, I realized "I don't know anything about Greenland" and started to watch some YouTube videos. It was about this time when I started to get a pit in my stomach, the "oh god I think I've made a huge mistake" feeling I'm painfully familiar with after a career in tech. Greenland appeared to have roughly 9 people living there and maybe 5 things to look at. Even professional travel personalities seemed to be scraping the bottom of the barrel. "There's the grocery store again!" they would point out as they slipped down the snowy roads. I couldn't tell any difference between different towns in the country.
It reminded me a lot of driving through Indiana. For those not in the US, Indiana is a state in the US famous for being a state one must drive through in order to get somewhere better. If you live in Michigan, a good state and want to go to Illinois, another good state, one must pass through Indiana, a blank state. Because of this little strip here, you often found yourself passing through this place.
Driving through Indiana isn't bad, it's just an empty void. It's like a time machine back to the 90s when people still smoke in restaurants but also there's nothing that sticks out about it. There is nothing distinct about Indiana, it's just a place full of people who got too tired on their way to somewhere better and decided "this is good enough". The difference is that Greenland is very hard to get to, as I was about to learn.
Finally the day arrived. Me, my wife, daughter, 4 other children and 6 other adults all came to the Copenhagen Airport and held up a gate agent for what felt like an hour to slowly process all of our documents. Meanwhile, I nursed a creeping paranoia that I'd be treated as some sort of American spy, given my government's recent hobby of threatening to purchase entire countries like they're vintage motorcycles on Craigslist.
The 5 hour flight is uneventful, the children are beautifully behaved and I begin to think "well this seems ok!" like the idiot I am. As I can look down and see the airport, the pilot comes on and informs us that there is too much fog to land safely. Surely fog cannot stop a modern aircraft full of all these dials and screens I think, foolishly. We are informed there is enough fuel to circle the airport for 5 hours to wait for the fog to lift.
What followed was three hours of flying in lazy circles, like a very expensive, very slow merry-go-round. After the allotted time, we are informed that we must fly to Iceland to refuel and then we will be returning to Denmark. After a total of 15 hours in the air we will be going back to exactly where we started, to do the entire thing again. We were obviously upset at this turn of events, but I noticed the native Greenlandic folks seemed not surprised at this turn of events. As I later learned, this happens all the time.
The native Greenlanders on board seemed utterly unsurprised by this development, displaying the kind of resigned familiarity that suggested this was Tuesday for them. I began wondering if I could just pretend Iceland was Greenland—surely my family wouldn't notice the difference? But the pilot, apparently reading my mind, announced that no one would be disembarking in Iceland. It felt oddly authoritarian, like being grounded by an airline, as if they knew we'd all just wander off into Reykjavik and call it close enough.
We crash out in a airport hotel 20 minutes from our apartment after 15 hours in the air and tons of CO2 emissions only to wake up the next day to start again. This time, I notice that all of the people are asking for (and receiving) free beer from the crew that they are stashing in their bags. It turns out soda and beer, really anything that needs to be imported, is pretty expensive in Greenland. The complimentary drinks are there to be kept for later.
Finally we land. The first thing you notice when you land in Greenland is there are no trees or grass. There is snow and then there is exposed rock. The exterior of the airport is metal but the inside is wood, which is strange because again there are no trees. This would end up being a theme, where buildings representing Denmark were made out of lots of wood, almost to ensure that you understood they weren't from here. We ended up piling all of our stuff into a bus and heading for the hotel in Nuuk.
Nuuk
Nuuk is the capital of Greenland and your introduction to the incredible calm of the Greenlandic people. I have never met a less stressed out group of humans in my life. Nobody is really rushing anywhere, it's all pretty quiet and calm. The air is cold and crisp with lots of kids playing outside and just generally enjoying life.
The city itself sits in a landscape so dramatically inhospitable it makes the surface of Mars look cozy. Walking through the local mall, half the shops sell gear designed to help you survive what appears to be the apocalypse. Yet somehow, there's traffic. Actual traffic jams in a place where you can walk from one end to the other in twenty minutes. It's like being stuck behind a school bus in your own driveway.
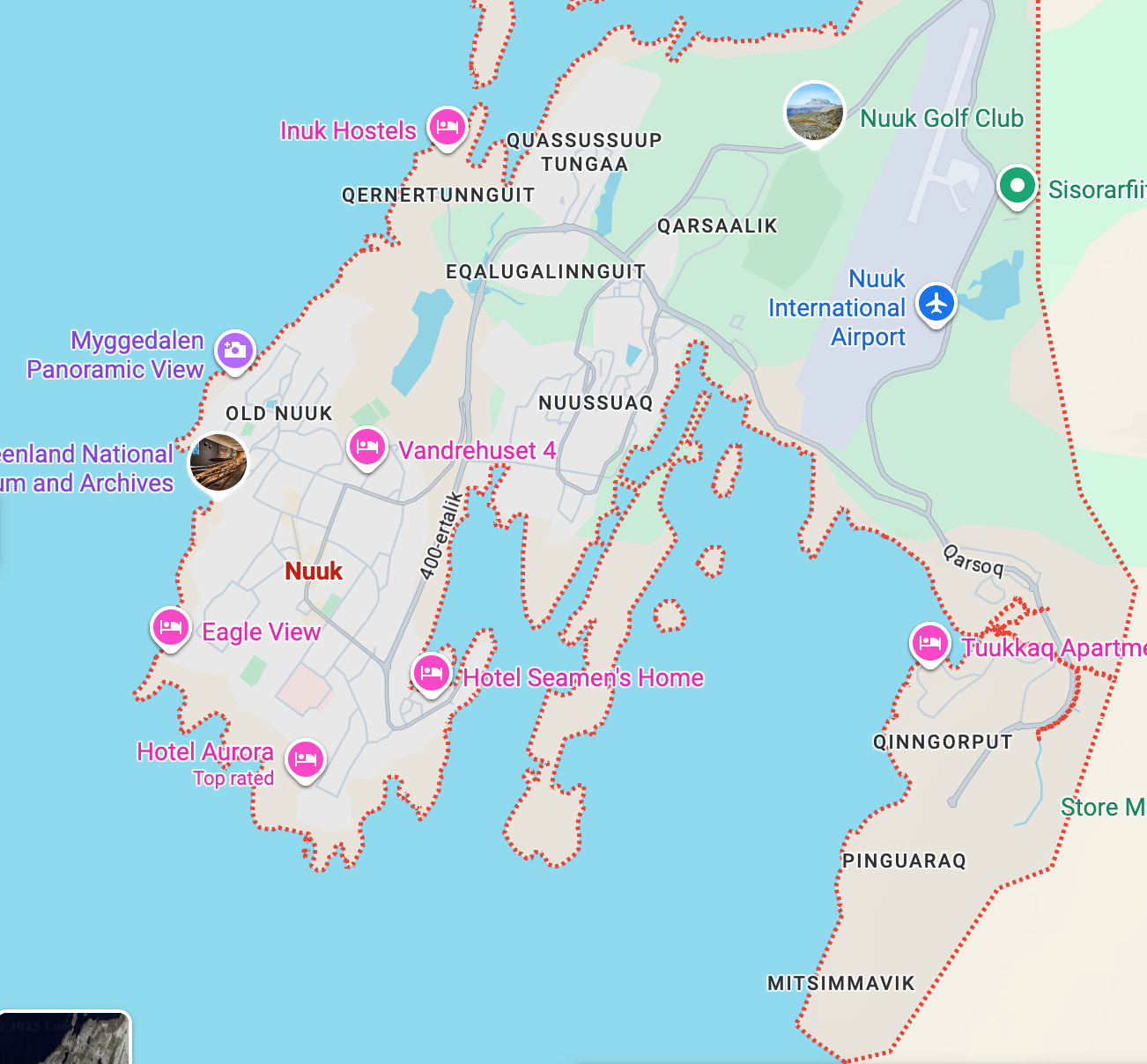
To put this map into some perspective, it is only six kilometers from the sorta furthest tip to the airport.
But riding the bus around Nuuk was a peaceful experience that lets you see pretty much the entire city without needing to book a tour or spend a lot of money. We went to Katuaq, a cultural center with a cafe and a movie theater that was absolutely delicious food.
But again even riding the bus around it is impossible to escape the feeling that this is a fundamentally hostile to human life place. The sun is bright and during the summer its pretty hot, with my skin feeling like it was starting the burn pretty much the second it was exposed to the light. It's hard to even dress for, with layers of sunscreen, bug spray and then something warm on top if you suddenly got cold.
The sun, meanwhile, has apparently forgotten how to set, turning our hotel rooms into solar ovens. You wake up in a pool of your own sweat, crack a window for relief, and immediately get hit with air so cold it feels personal. It's like being trapped in a meteorological mood swing.
So after a night here, we went back to the airport again and flew to our final destination, Ilulissat.
Ilulissat
My new favorite airport
The flight to our final destination revealed Greenland's true nature: endless, empty hills stretching toward infinity, punctuated by ice formations that look like nature's sculpture garden.
Landing in Ilulissat felt like victory—we'd made it to the actual destination, not just another waypoint in our Arctic odyssey. Walking through the tiny airport, past Danish military recruitment posters (apparently someone, somewhere, thought this place needed defending), I felt genuinely optimistic for the first time in days.
Well you can sleep easy Danish military, because Ilulissat is completely protected from invasion. The second I stepped outside I was set upon by a flood of mosquitos like I have never experienced before. I have been to the jungles of Vietnam, the swamps of Florida and the Canadian countryside. This was beyond anything I've ever experienced.
There are bugs in my mouth, ears, eyes and nose almost immediately. The photo below is not me being dramatic, it is actually what is required to keep them off of me.
In fact what you need to purchase in order to walk around this area at all are basically bug nets for your face. They're effectively plastic mesh bags that you put on.
The Dogs
Our hotel, charming in that "remote Arctic outpost" way, sat adjacent to what I can only describe as a canine correctional facility. Dozens of sled dogs were chained to rocks like some sort of prehistoric parking lot, each with a tiny house they could retreat to when the existential weight of their circumstances became too much.
Now, I'd always imagined sled dogs living their best life—running through snow, tongues lolling, living the Disney version of Arctic life. I'd never really considered their downtime, assuming they frolicked in meadows or something equally wholesome. The reality was more "minimum security prison with a view."
The dogs are visited roughly twice a day by the person who owns and feeds them, which was quite the party for the dogs that lost their minds whenever the car pulled up. Soon the kids really looked forward to dog feeding time. The fish scrapes the dogs lived on came out of a chest freezer that was left exposed up on the rock face without electricity and you could smell it from 50 yards away when it opened.
During one such performance, a fellow parent leaned over and whispered with the casual tone of someone commenting on the weather, "I think that one is dead." Before I could process this information, the frozen canine was unceremoniously launched over a small cliff like a furry discus. A second doggy popsicle followed shortly after, right in front of our assembled children, who watched with the kind of wide-eyed fascination usually reserved for magic shows.
We stopped making dog feeding time a group activity after that and had to distract the kids from ravens flying away with tufts of dog fur.
Whales taste like seaweed
Obviously a big part of Greenland is the nature, specifically the icebergs. Icebergs are incredible and during the week we spend up there, I enjoyed watching them every morning. It's like watching a mountain slowly moving while you sit still. The visual contrast of the ice and the exposed stone is beautiful and peaceful.
Finding our tour operator proved to be an exercise in small-town efficiency. The man who gave me directions was the same person who picked us up from the airport, who was also our tour guide, who probably doubled as the mayor and local meteorologist. It was like a one-man civic operation disguised as multiple businesses—the ultimate small-town gig economy.
The sea around Greenland is calmer than anything I've ever been on before, perfectly calm and serene. All around us whales emerged, thrilling my daughter. However the biggest hit of the entire tour, maybe the entire trip, was a member of the crew who handed each of the kids a giant rock of glacier ice to eat. I had to pull my daughter away to observe the natural beauty as she ate glacier ice like it was ice cream. "LOOK AT MY ICE" she was yelling as they slipped and slid around the deck of this boat.
So if you've ever wonder "what is a glacier", let me tell you. Greenland has a lot of ice and it pushes out from the land that is covers into the sea. When that happens, a lot of it breaks off. This sounds more exciting than it is. On TV in 4K it looks incredible, giant mountains of ice falling into the ocean. Honestly you can go read the same thing I did here.
However that doesn't happen very often. So in order for us tourists to be able to see anything, we had to go to a very productive glacier. This means there are constantly small chunks breaking off and falling into the sea. Practically though, it kinda looks like you are a boat in a slushee. It's beautiful and something to see, but also depressing to see along the rock face how much more ice there used to be.
Back in town, we hopped on the "bus". Now the bus here is clearly a retrofitted party van, complete with blue LED lights. The payment system is zip tied to a desk chair that is, itself, wedged in the front. However the bus works well and does get you around. The confusing part is that you will, once again, sometimes encounter a lot of traffic. People are driving pretty quickly and really seem to have somewhere to go. You also see a lot of fancy cars parked outside of houses here.
Which begs a pretty basic question. If there was almost nowhere to drive to in Nuuk, where in the hell are these people driving. The distance between the end of the road and the beginning of the road is less than 6 km. Also the process to make a road here is beyond anything you've ever seen. Everything requires a giant pile of explosives.
Where did these vehicles even come from? Why does one ship a BMW to a place accessible only by plane and boat? More importantly, where was everyone going with such determination? It was like watching a very expensive version of bumper cars, except everyone was committed to the illusion that they had somewhere important to be. Everyone had dings and scrapes like crashes were common.
Grocery Store from the Sea
Anyway, as I dodged speeding cars filled with people heading nowhere, I decided to hop off the bus and head to the grocery store. Inside was less a store and more the idea of a store. There was a lot of alcohol, chips, candy and shelf-stable foods, which all makes sense to me. What was strange was there wasn't a lot else, including meat. Locals couldn't be eating at the local restaurants, where the prices were as high as Berlin or Copenhagen for food. So what were they eating?
When I asked one of my bus drivers, he told me that it was pretty unusual to buy meat. They purchased a lot of whale and seal meat. I had sorta heard this before, but when we stopped the bus he pointed out a group of men hauling guns out into a small boat to go shoot seals. The guns were held together with a surprising amount of duct tape, which is not something I associate with the wild.
I had assumed, based on my casual reading of the news, that we were mostly done killing whales. As it turns out, I was wrong. They eat a lot of whale and it is, in fact, not hard to find. If you are curious, whale does not taste fishy. It tastes a little bit like if you cooked reindeer in a pot of seaweed. I wouldn't go out of your way for it, but it's not terrible.
The argument I've always heard for why people still kill whales is because it's part of their culture and also because it's an important source of protein. When you hear the phrase "part of their culture" I always imagined like traditional boats going out with spears. What I didn't imagine was industrial fishing boats and an industrial crane that lifts the dead whale out of the water for "processing". Some of the illusion is broken when your boat tour guide points out the metal warehouse with the word "whale" on the side. "Yeah the water here was red with blood for a week" the guide said, counting the cigarettes left in a pack he had.
Should you go to Greenland?
It's a wild place unlike anywhere I've ever been. It is the closest I have ever felt to living a sci-fi type experience. The people of Greenland are amazing, tough, calm and kind. I have nothing but positive experiences to recount from the many people I met there, Danish and Greenlandic, who patiently sat through my millions of questions.
However it is, by far, the least hospitable to human life place I've ever been to. The folks who live there have adapted to the situation in, frankly, genius ways. If that's your idea of a good time, Greenland is perfect for you. Maybe don't get emotionally attached to the sled dogs though. Or the whales.