I was recently invited to try out the beta for GitHub's new AI-driven web IDE and figured it could be an interesting time to dip my toes into AI. So far I've avoided all of the AI tooling, trying the GitHub paid Copilot option and being frankly underwhelmed. It made more work for me than it saved. However this is free for me to try and I figured "hey why not".
Disclaimer: I am not and have never been an employee of GitHub, Microsoft, any company owned by Microsoft, etc. They don't care about me and likely aren't aware of my existence. Nobody from GitHub PR asked me to do this and probably won't like what I have to say anyway.
TL;DR
GitHub Copilot Workspace didn't work on a super simple task regardless of how easy I made the task. I wouldn't use something like this for free, much less pay for it. It sort of failed in every way it could at every step.
What is GitHub Copilot Workspace?
So after the success of GitHub Copilot, which seems successful according to them:
In 2022, we launched GitHub Copilot as an autocomplete pair programmer in the editor, boosting developer productivity by up to 55%. Copilot is now the most widely adopted AI developer tool. In 2023, we released GitHub Copilot Chat—unlocking the power of natural language in coding, debugging, and testing—allowing developers to converse with their code in real time.
They have expanded on this feature set with GitHub Copilot Workspace, a combination of an AI tool with an online IDE....sorta. It's all powered by GPT-4 so my understanding is this is the best LLM money can buy. The workflow of the tool is strange and takes a little bit of explanation to convey what it is doing.
GitHub has the marketing page here: https://githubnext.com/projects/copilot-workspace and the docs here: https://github.com/githubnext/copilot-workspace-user-manual. It's a beta product and I thought the docs were nicely written.
Effectively you start with a GitHub Issue, the classic way maintainers are harassed by random strangers. I've moved my very simple demo site: https://gcp-iam-reference.matduggan.com/ to a GitHub repo to show what I did. So I open the issue here: https://github.com/matdevdug/gcp-iam-reference/issues/1
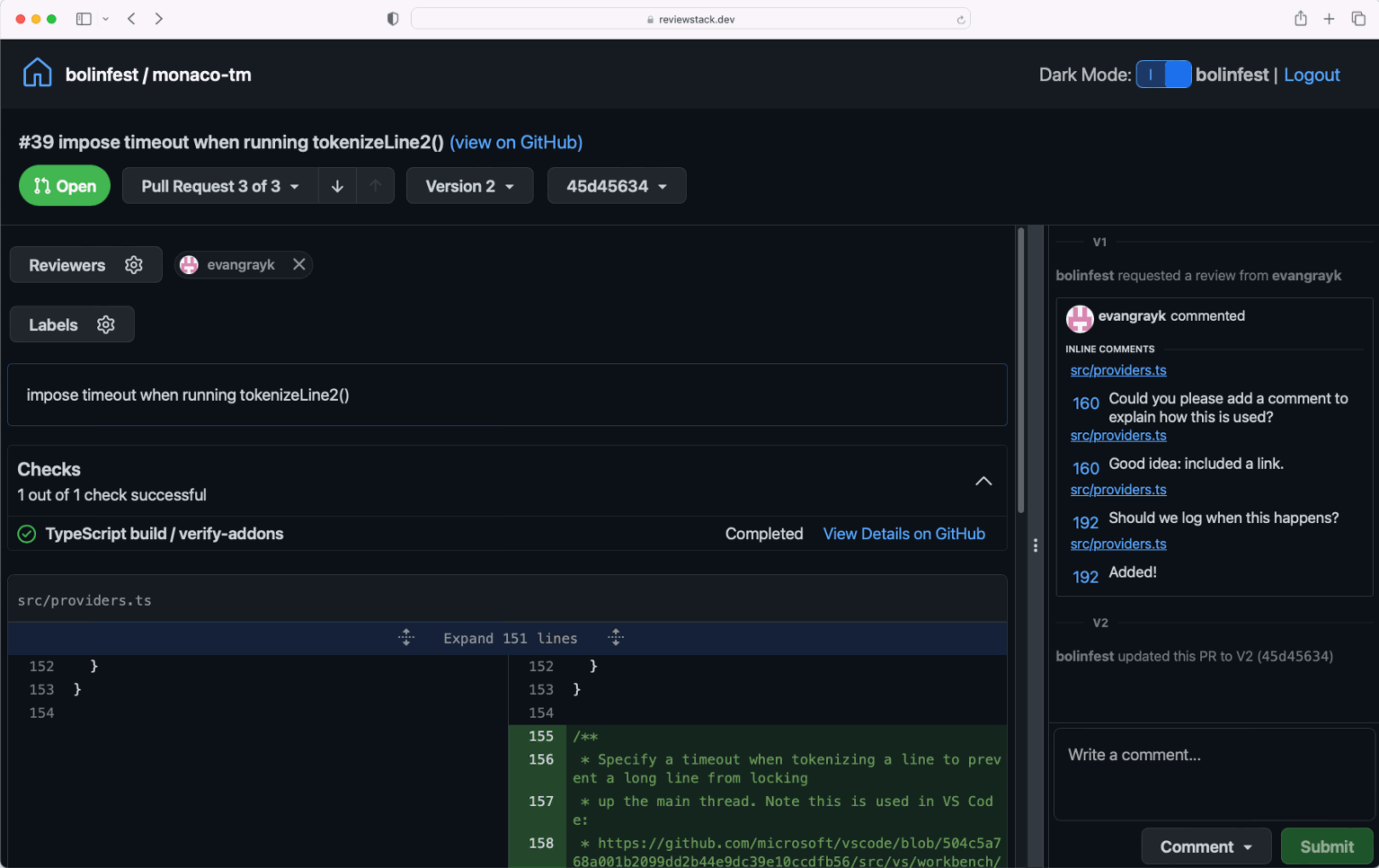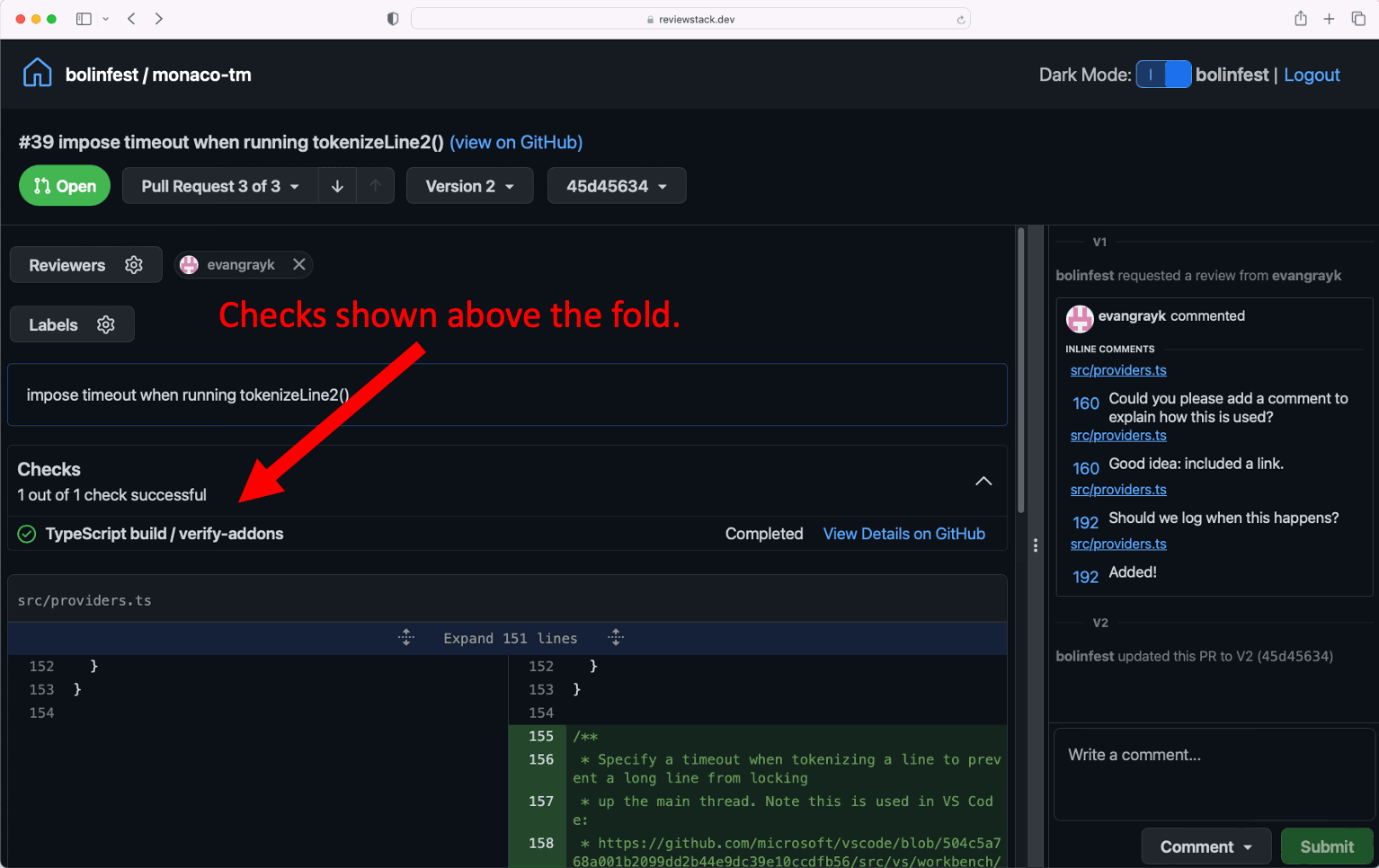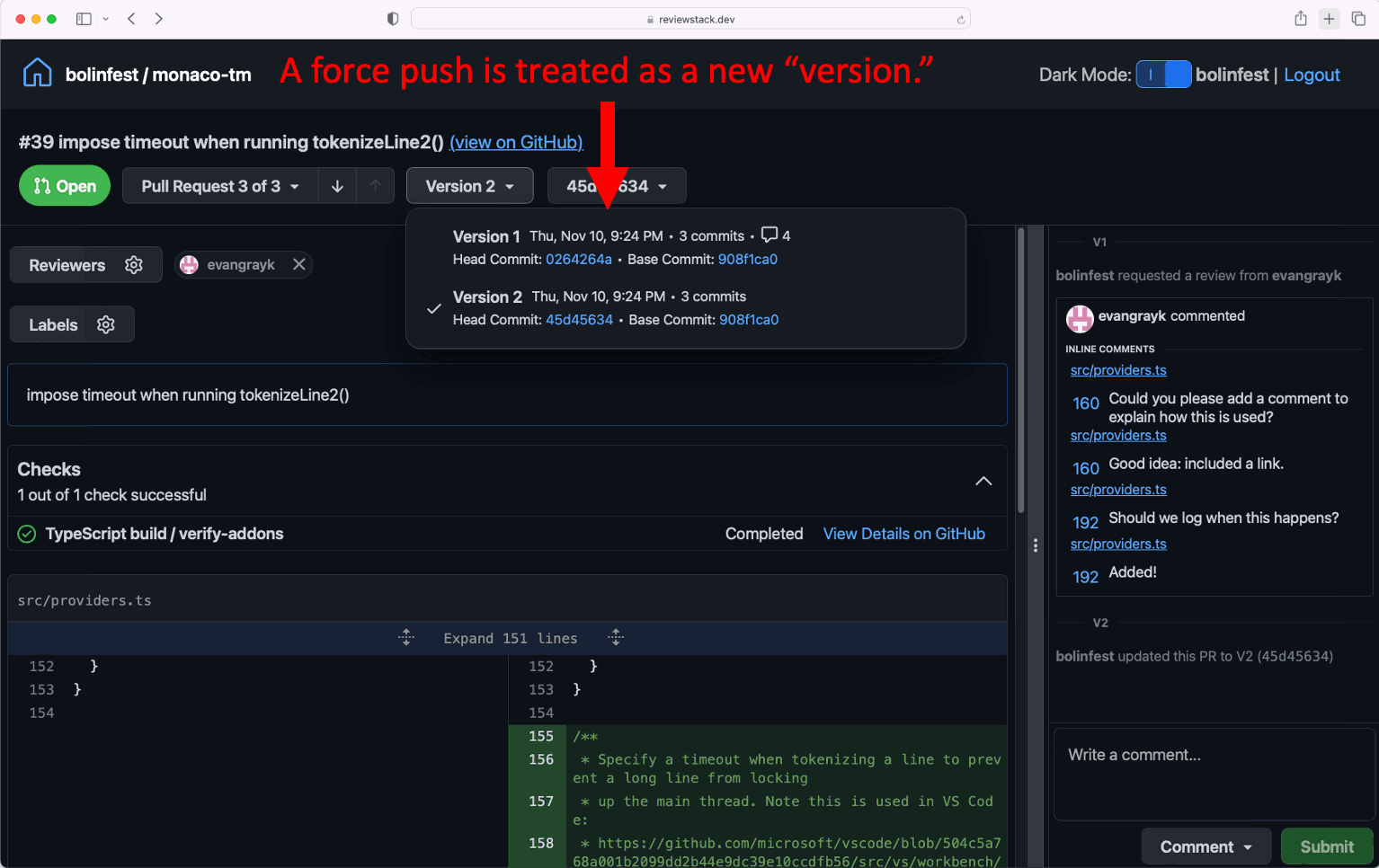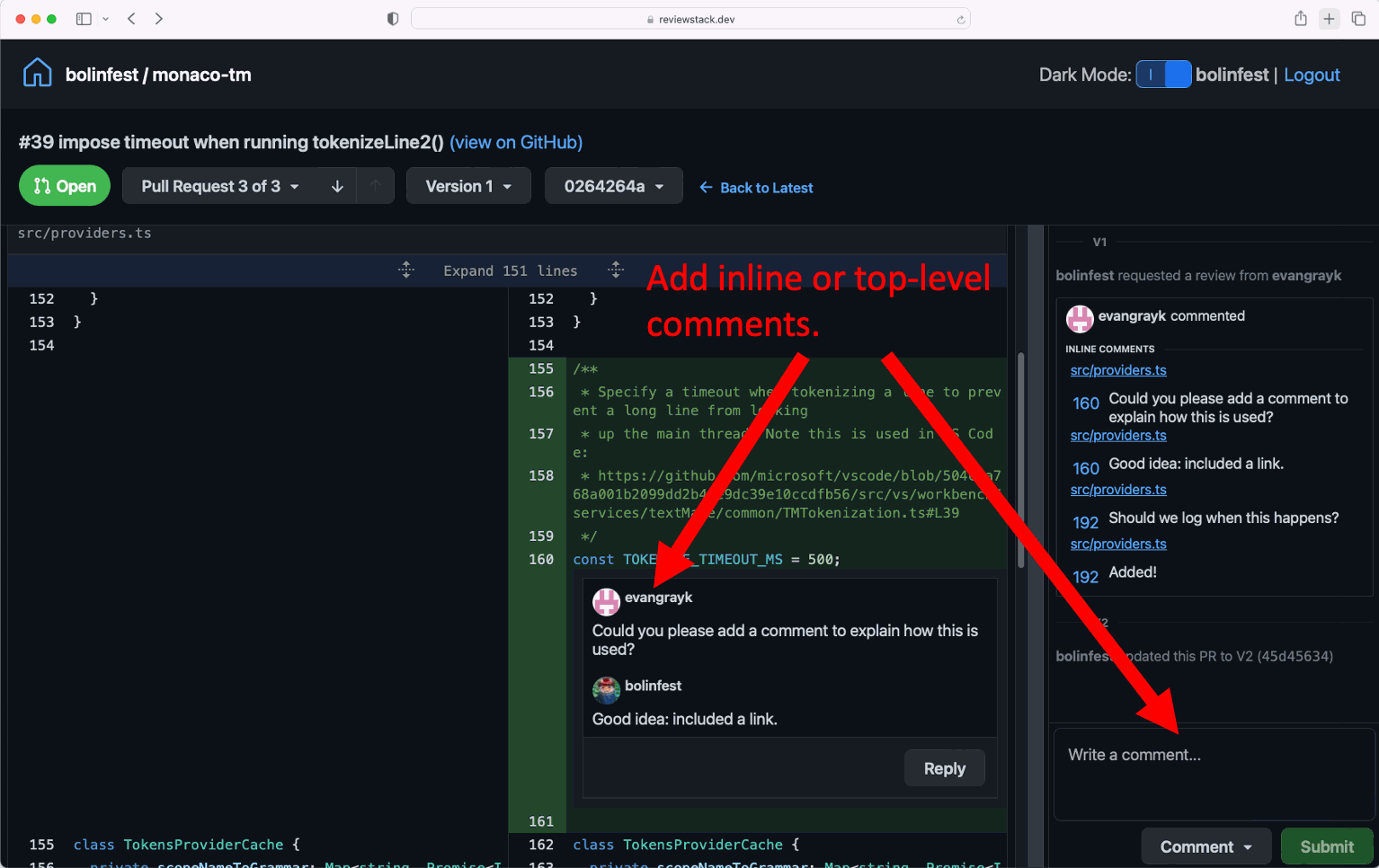
Very simple, makes sense, Then I click "Open in Workspaces" which brings me to a kind of GitHub Actions inspired flow.
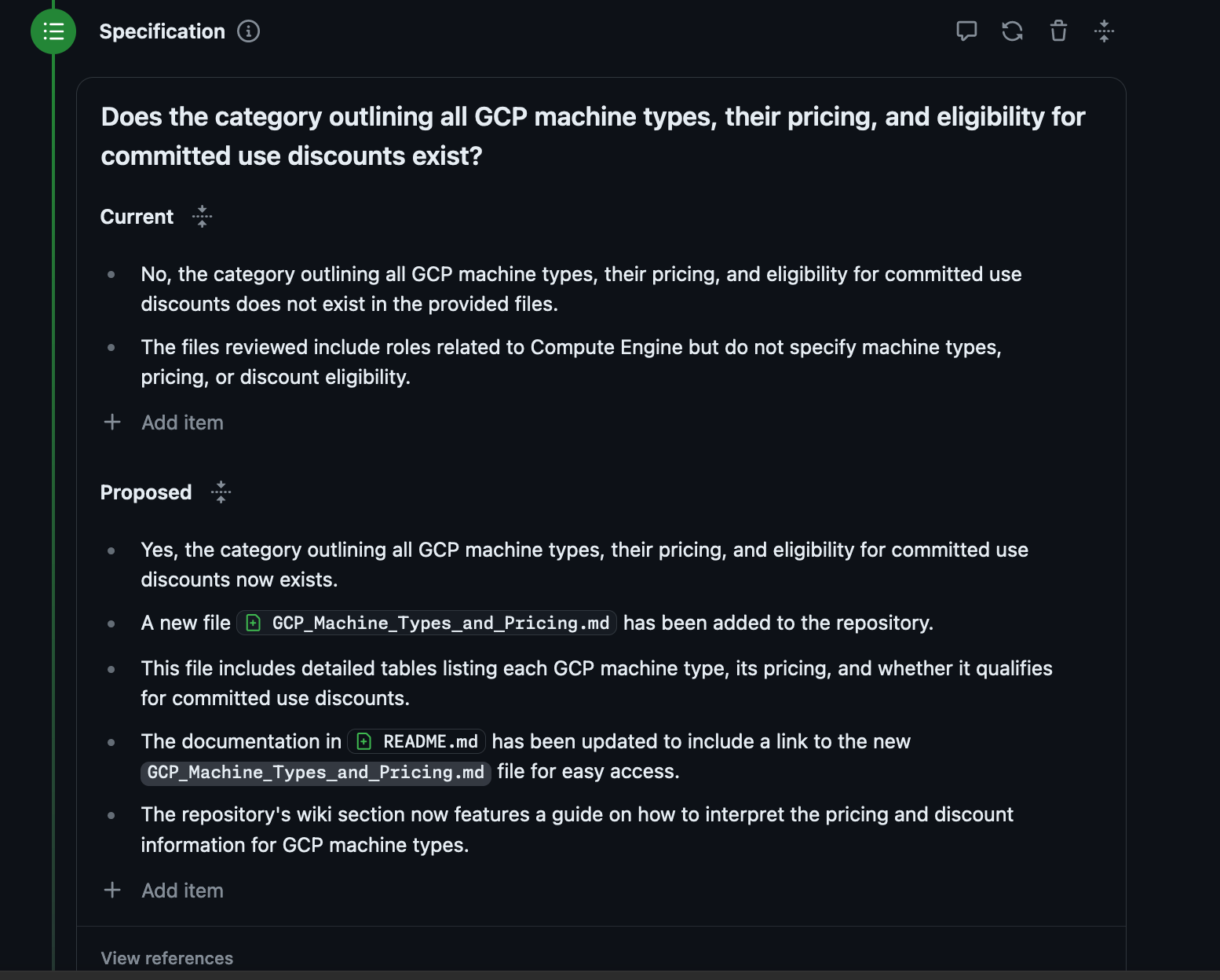
It reads the Issue and creates a Specification, which is editable.
Then you generate a Plan:
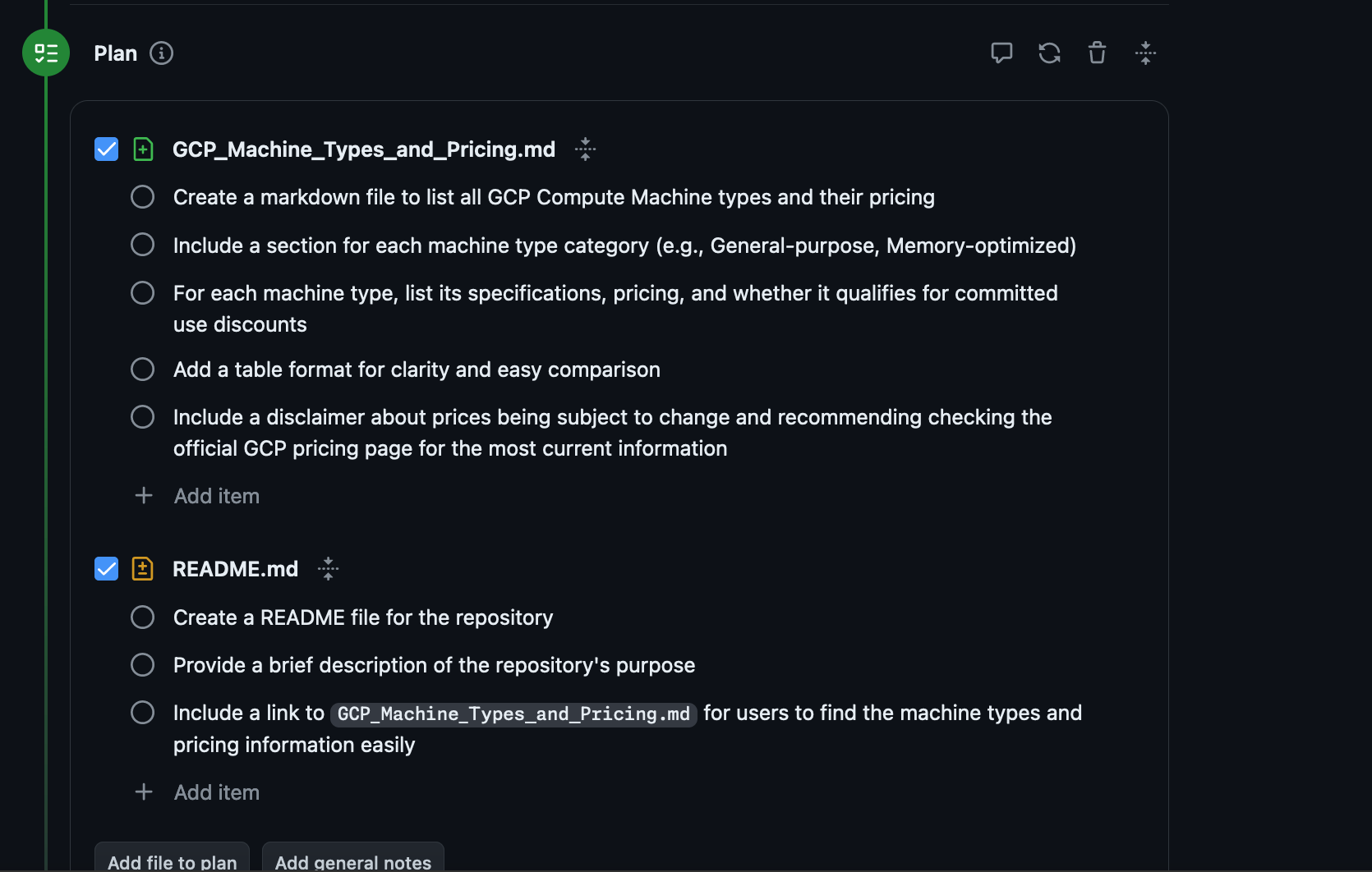
Finally it generates the files of that plan and you can choose whether to implement them or not and open a Pull Request against the main branch.
Implementation:
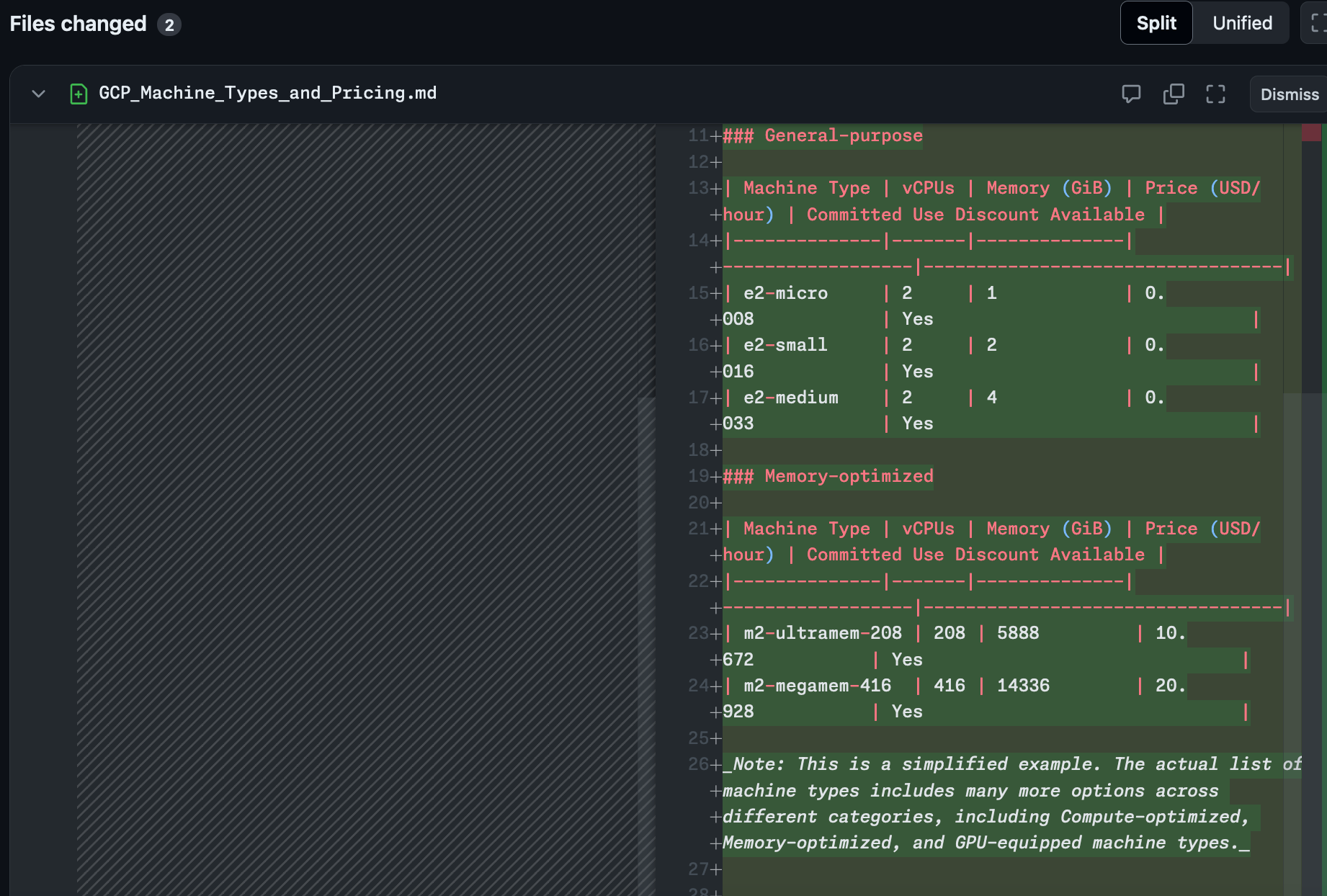
It makes a Pull Request:
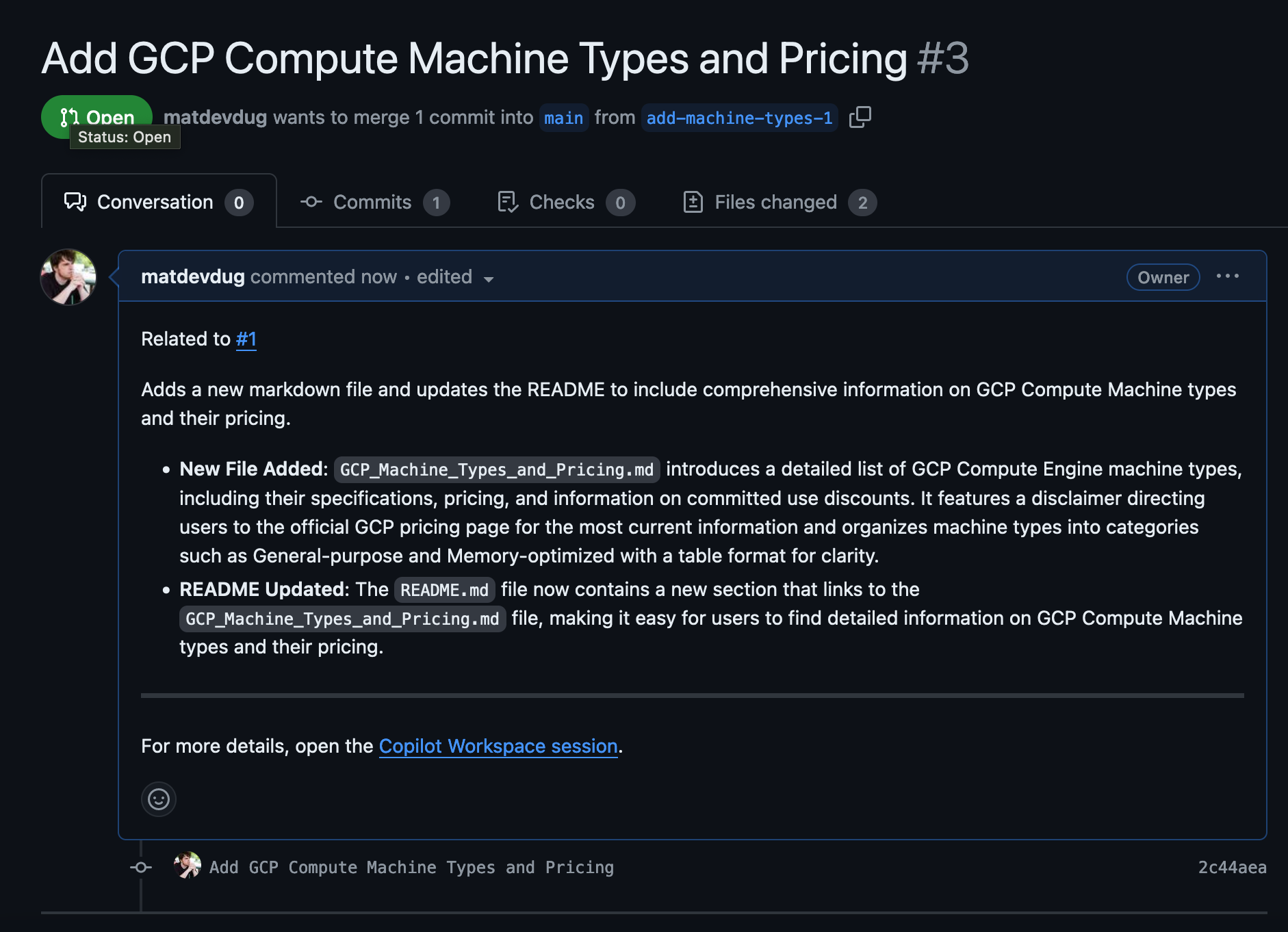
Great right? Well except it didn't do any of it right.
- It didn't add a route to the Flask app to expose this information
- It didn't stick with the convention of storing the information in JSON files, writing it out to Markdown for some reason
- It decided the way that it was going to reveal this information was to add it to the README
- Finally it didn't get anywhere near all the machine types.

Baby Web App
So the app I've written here is primarily for my own use and it is very brain dead simple. The entire thing is the work of roughly an afternoon of poking around while responding to Slack messages. However I figured this would be a good example of maybe a more simple internal tool where you might trust AI to go a bit nuts since nothing critical will explode if it messes up.
How the site works it is relies on the output of the gcloud CLI tool to generate JSON of all of IAM permissions for GCP and then output them so that I can put them into categories and quickly look for the one I want. I found the official documentation to be slow and hard to use, so I made my own. It's a Flask app, which means it is pretty stupid simple.
import os
from flask import *
from all_functions import *
import json
app = Flask(__name__)
@app.route('/')
def main():
items = get_iam_categories()
role_data = get_roles_data()
return render_template("index.html", items=items, role_data=role_data)
@app.route('/all-roles')
def all_roles():
items = get_iam_categories()
role_data = get_roles_data()
return render_template("all_roles.html", items=items, role_data=role_data)
@app.route('/search')
def search():
items = get_iam_categories()
return render_template('search_page.html', items=items)
@app.route('/iam-classes')
def iam_classes():
source = request.args.get('parameter')
items = get_iam_categories()
specific_items = get_specific_roles(source)
print(specific_items)
return render_template("iam-classes.html", specific_items=specific_items, items=items)
@app.route('/tsid', methods=['GET'])
def tsid():
data = get_tsid()
return jsonify(data)
@app.route('/eu-eea', methods=['GET'])
def eueea():
country_code = get_country_codes()
return is_eea(country_code)
if __name__ == '__main__':
app.run(debug=False)I also have an endpoint I use during testing if I need to test some specific GDPR code so I can curl it and see if the IP address is coming from EU/EEA or not along with a TSID generator I used for a brief period of testing that I don't need anymore. So again, pretty simple. It could be rewritten to be much better but I'm the primary user and I don't care, so whatever.
So effectively what I want to add is another route where I would also have a list of all the GCP machine types because their official documentation is horrible and unreadable. https://cloud.google.com/compute/docs/machine-resource
What I'm looking to add is something like this: https://gcloud-compute.com/
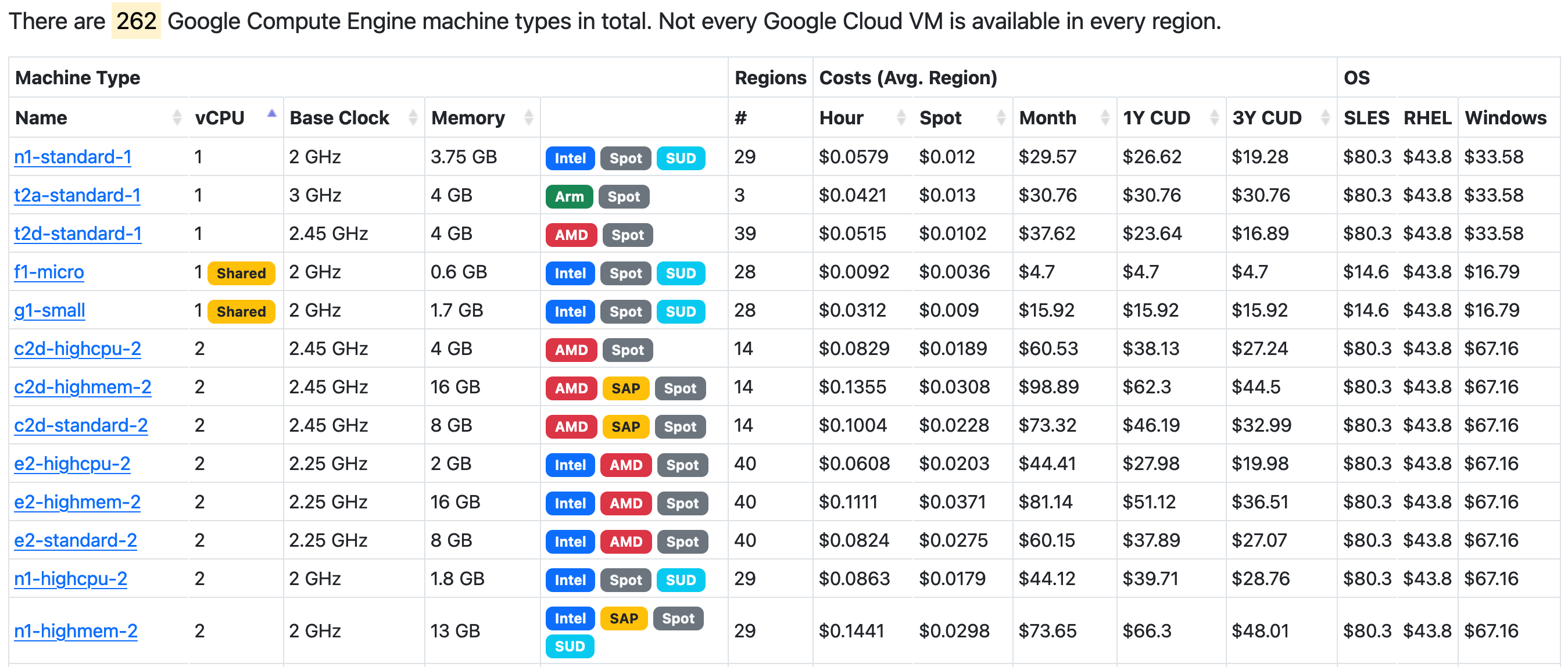
Look how information packed it is! My god, I can tell at a glance if a machine type is eligible for Sustained Use Discounts, how many regions it is in, Hour/Spot/Month pricing and the breakout per OS along with Clock speed. If only Google had a team capable of making a spreadsheet.
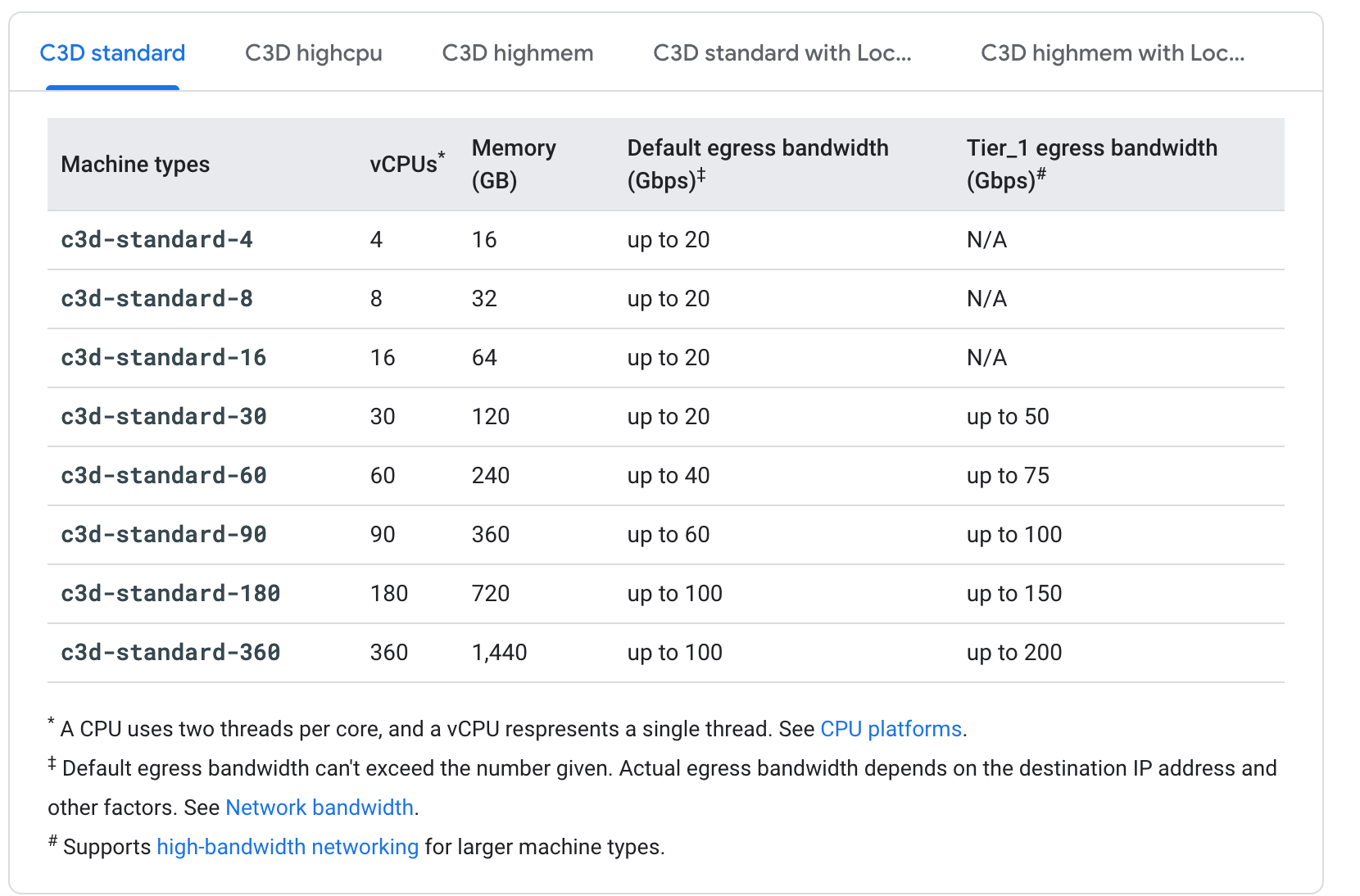
Nothing I enjoy more than nested pages with nested submenus that lack all the information I would actually need. I'm also not clear what a Tier_1 bandwidth is but it does seem unlikely that it matters for machine types when so few have it.
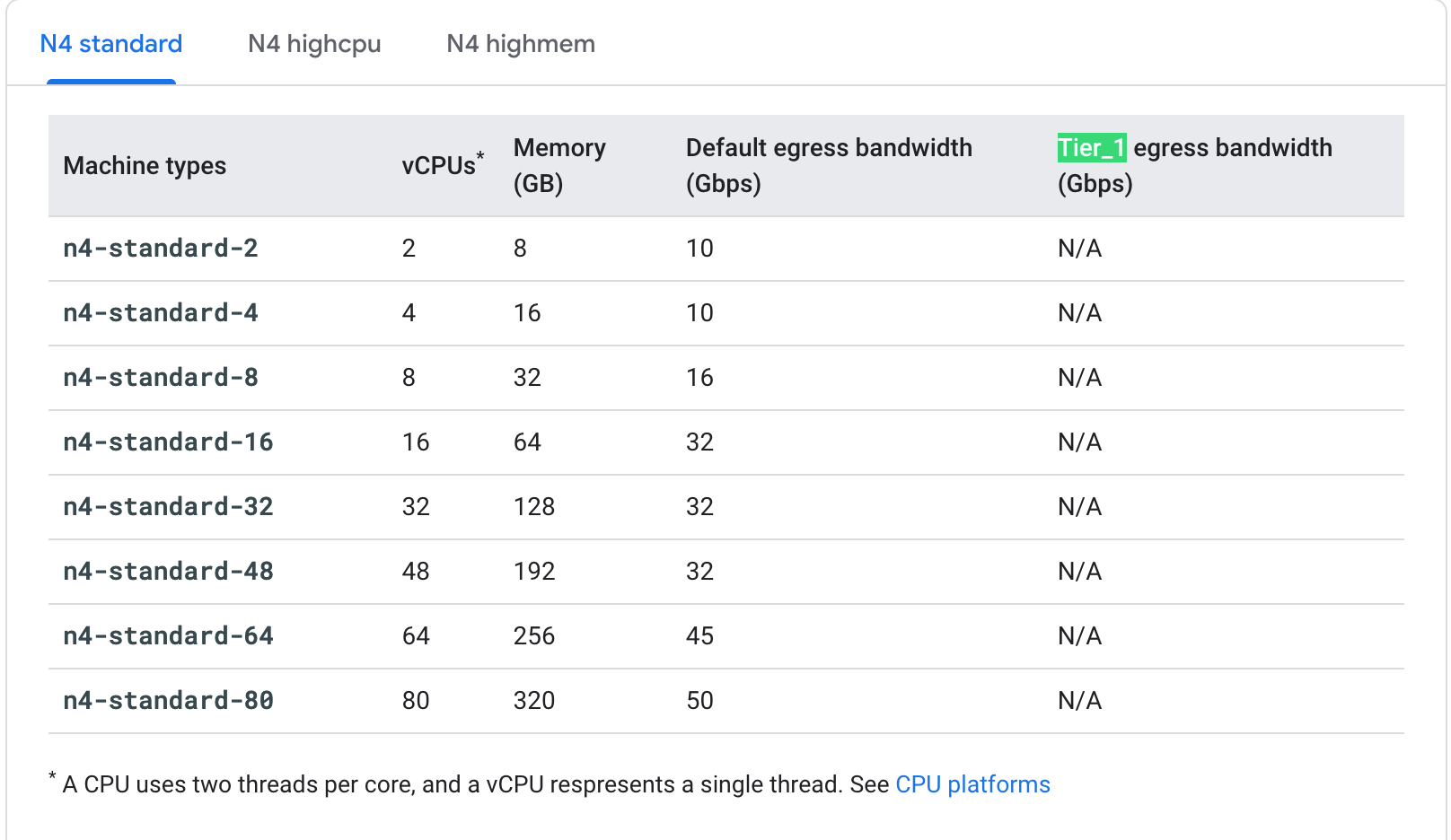
I could complain about how GCP organizes information all day but regardless the information exists. So I don't need anything to this level, but could I make a simpler version of this that gives me some of the same information? Seems possible.
How I Would Do It
First let's try to stick with the gcloud CLI approach.
gcloud compute machine-types list --format="json"
Only problem with this is that it does output the information I want, but for some reason it outputs a JSON file per region.
{
"creationTimestamp": "1969-12-31T16:00:00.000-08:00",
"description": "4 vCPUs 4 GB RAM",
"guestCpus": 4,
"id": "903004",
"imageSpaceGb": 0,
"isSharedCpu": false,
"kind": "compute#machineType",
"maximumPersistentDisks": 128,
"maximumPersistentDisksSizeGb": "263168",
"memoryMb": 4096,
"name": "n2-highcpu-4",
"selfLink": "https://www.googleapis.com/compute/v1/projects/sybogames-artifact/zones/africa-south1-c/machineTypes/n2-highcpu-4",
"zone": "africa-south1-c"
}I don't know why but sure. However I don't actually need every region so I can cheat here. gcloud compute machine-types list --format="json" gets me some of the way there.
Where's the price?
Yeah so Google doesn't expose pricing through the API as far as I can tell. You can download what is effectively a global price list for your account at https://console.cloud.google.com/billing/[your billing account id]/pricing. That's a 13 MB CSV that includes what your specific pricing will be, which is what I would use. So then I would combine the information from my region with the information from the CSV and then output the values. However since I don't know whether the pricing I have is relevant to you, I can't really use this to generate a public webpage.
Web Scraping
So realistically my only option would be to scrape the pricing page here: https://cloud.google.com/compute/all-pricing. Except of course it was designed in such a way as to make it as hard to do that as possible.
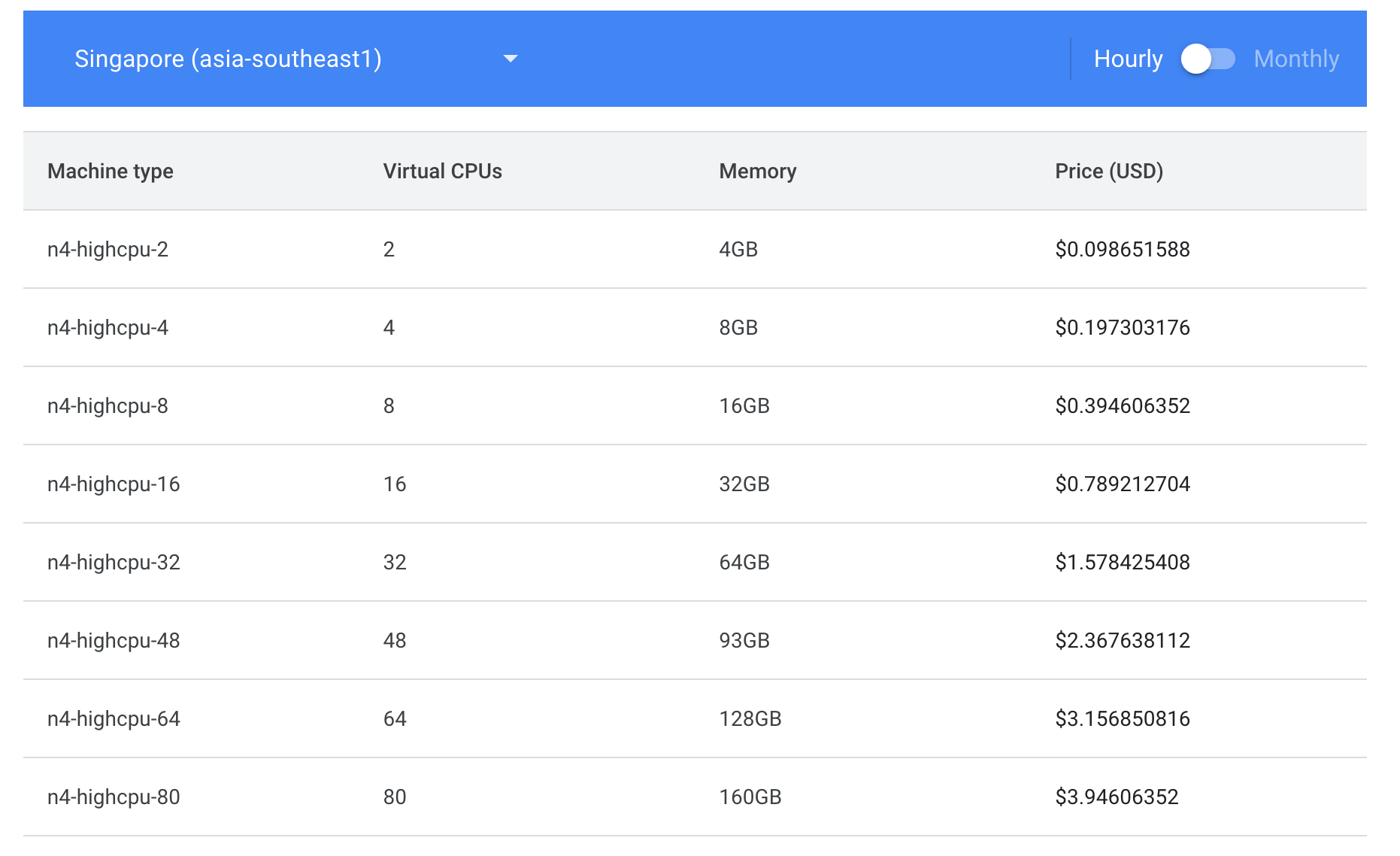
Boy it is hard to escape the impression GCP does not want me doing large-scale cost analysis. Wonder why?
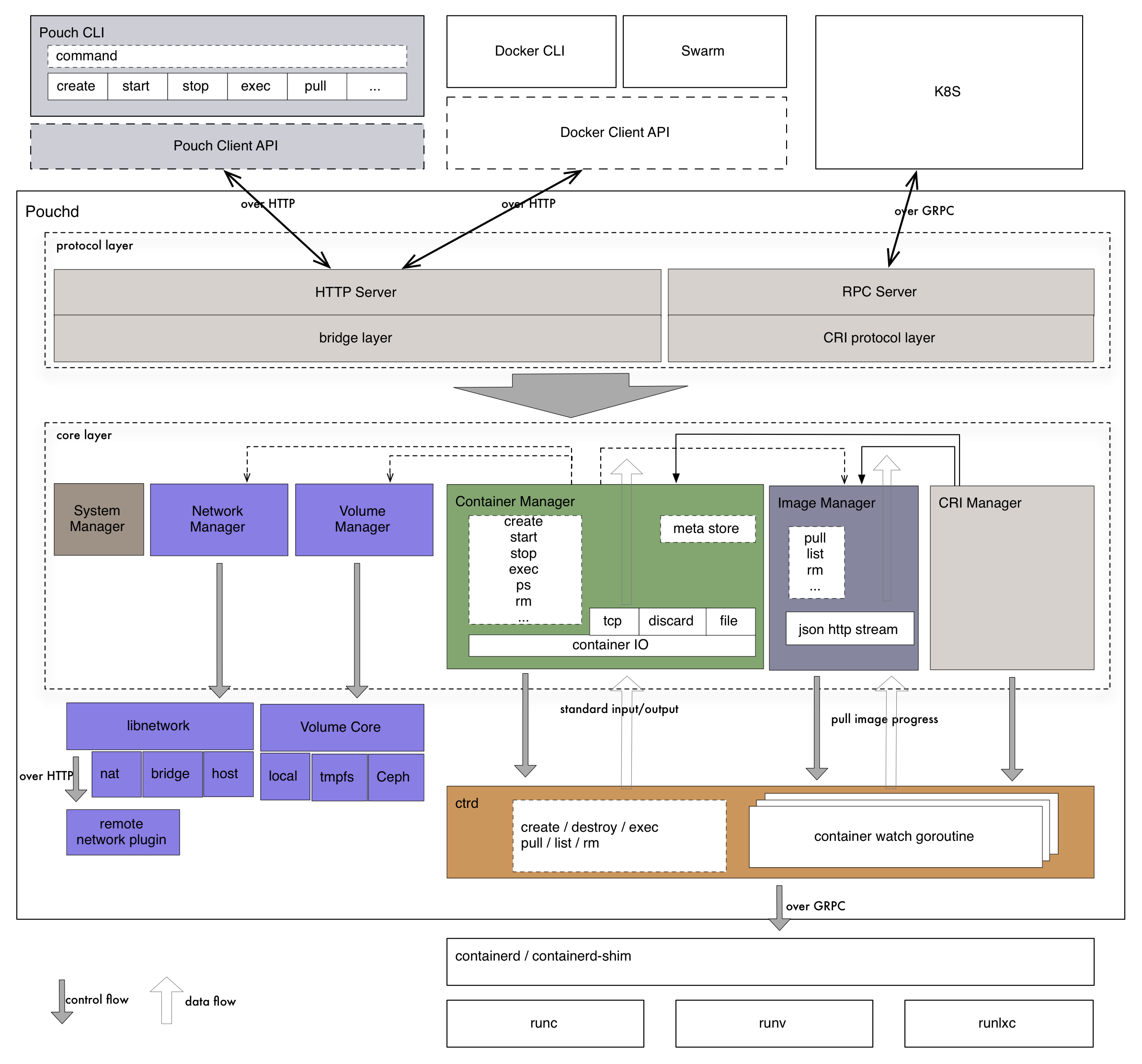
So there's actually a tool called gcosts which seems to power a lot of these sites running price analysis. However it relies on a pricing.yml file which is automatically generated weekly. The work involved in generating this file is not trivial:
+--------------------------+ +------------------------------+
| Google Cloud Billing API | | Custom mapping (mapping.csv) |
+--------------------------+ +------------------------------+
↓ ↓
+------------------------------------------------------------+
| » Export SKUs and add custom mapping IDs to SKUs (skus.sh) |
+------------------------------------------------------------+
↓
+----------------------------------+ +-----------------------------+
| SKUs pricing with custom mapping | | Google Cloud Platform info. |
| (skus.db) | | (gcp.yml) |
+----------------------------------+ +-----------------------------+
\ /
+--------------------------------------------------+
| » Generate pricing information file (pricing.pl) |
+--------------------------------------------------+
↓
+-------------------------------+
| GCP pricing information file |
| (pricing.yml) |
+-------------------------------+Alright so looking through the GitHub Action that generates this pricing.yml file, here, I can see how it works and how the file is generated. But also I can just skip that part and pull the latest for my usecase whenever I regenerate the site. That can be found here.
Effectively with no assistance from AI, I have now figured out how I would do this:
- Pull down the
pricing.ymlfile and parse it - Take that information and output it to a simple table structure
- Make a new route on the Flask app and expose that information
- Add a step to the Dockerfile to pull in the new pricing.yml with every Dockerfile build just so I'm not hammering the GitHub CDN all the time.
Why Am I Saying All This?
So this is a perfect example of an operation that should be simple but because the vendor doesn't want to make it simple, is actually pretty complicated. As we can now tell from the PR generated before, AI is never going to be able to understand all the steps we just walked through to understand how one actually get the prices for these machines. We've also learned that because of the hard work of someone else, we can skip a lot of the steps. So let's try it again.
Attempt 2
Maybe if I give it super specific information, it can do a better job.
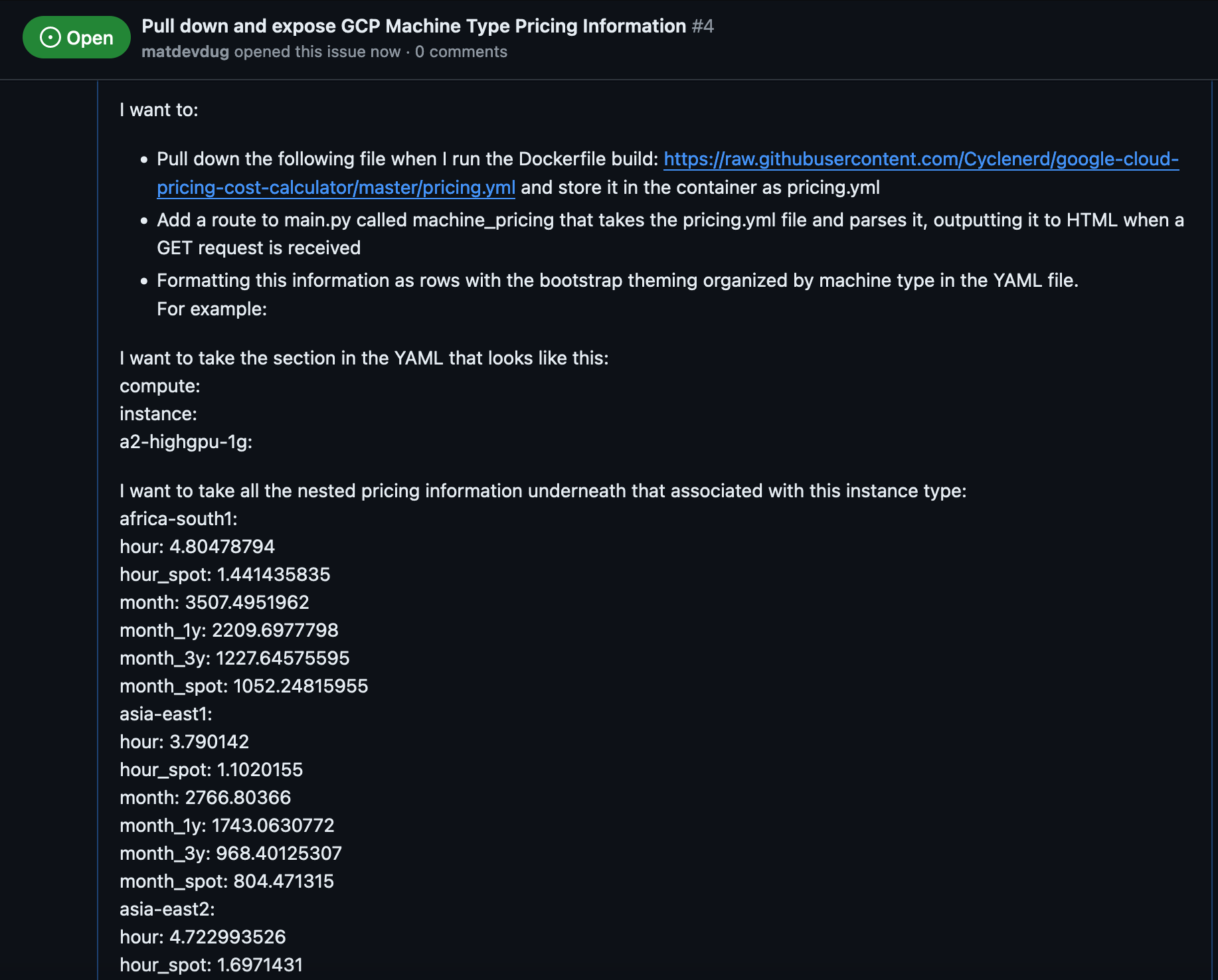
You can see the issue here: https://github.com/matdevdug/gcp-iam-reference/issues/4
I think I've explained maybe what I'm trying to do. Certainly a person would understand this. Obviously this isn't the right way to organize this information, I would want to do a different view and sort by region and blah blah blah. However this should be easier for the machine to understand.
Note: I am aware that Copilot has issues making calls to the internet to pull files, even from GitHub itself. That's why I've tried to include a sample of the data. If there's a canonical way to pass the tool information inside of the issue let me know at the link at the bottom.
Results
So at first things looked promising.
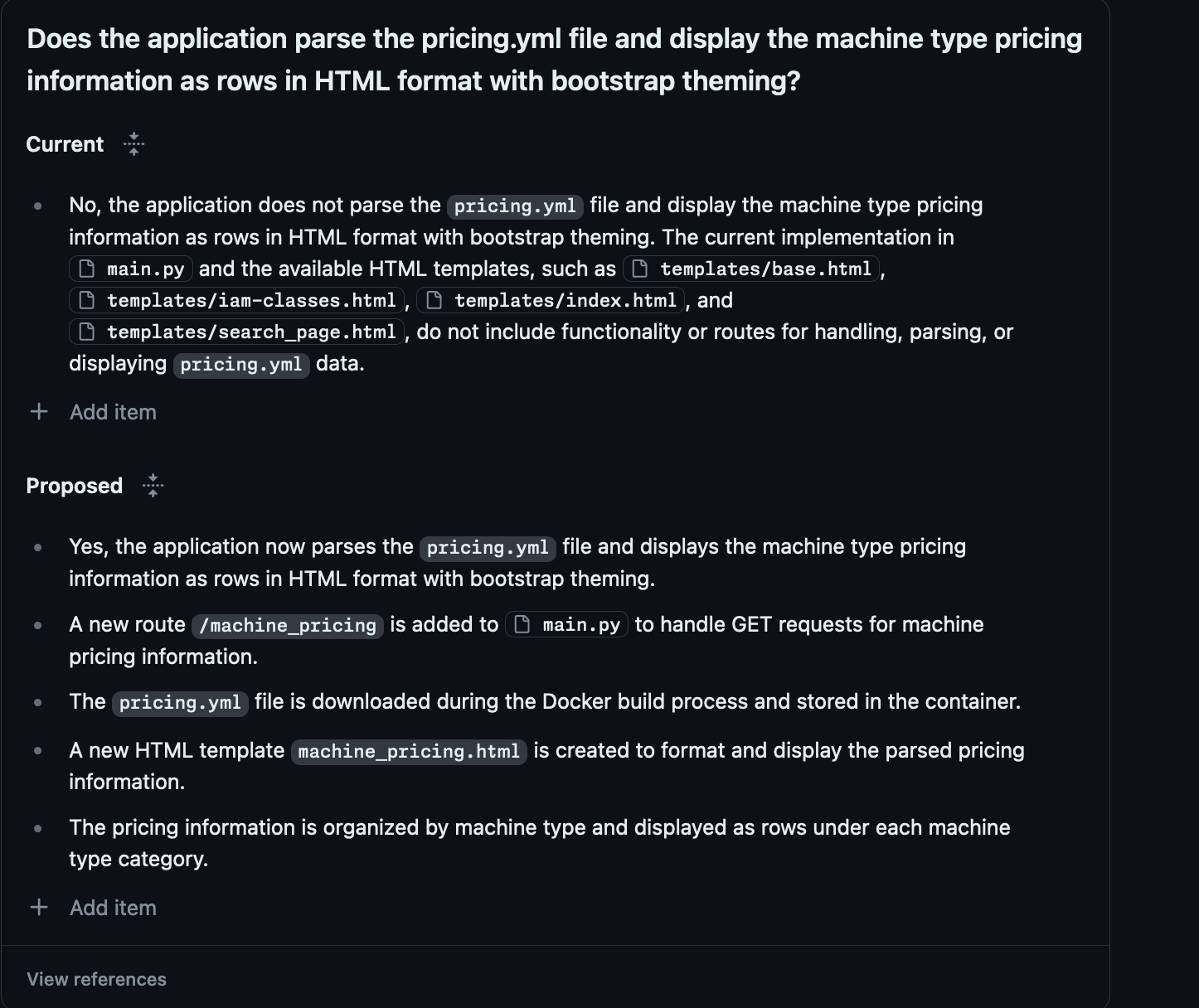
It seems to understand what I'm asking and why I'm asking it. This is roughly the correct thing. The plan also looks ok:
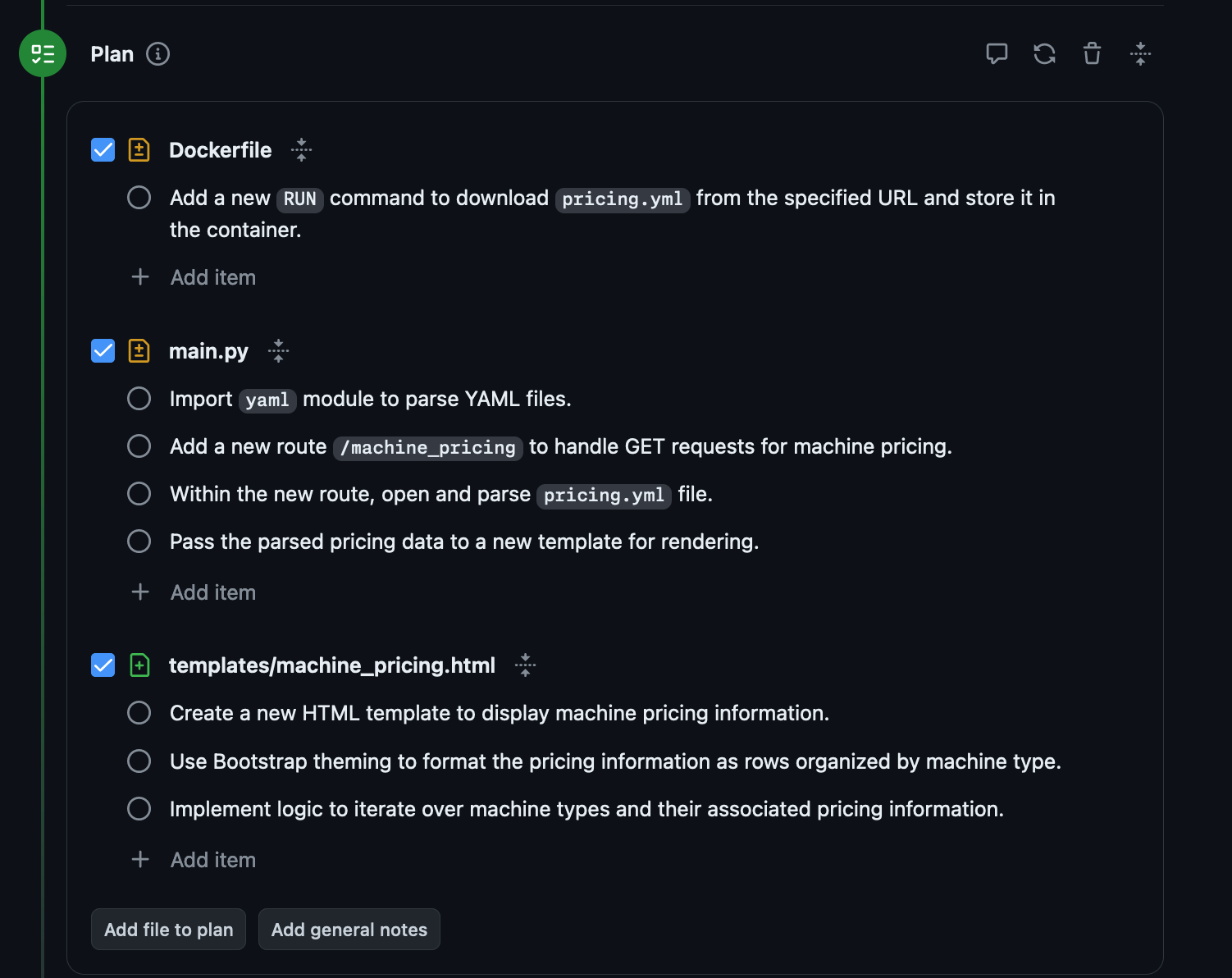
You can see the PR it generated here: https://github.com/matdevdug/gcp-iam-reference/pull/5
So this is much closer but it's still not really "right". First like most Flask apps I have a base template that I want to include on every page: https://github.com/matdevdug/gcp-iam-reference/blob/main/templates/base.html
Then for every HTML file after that we extend the base:
{% extends "base.html" %}
{% block main %}
<style>
table {
border-collapse: collapse;
width: 100%;
}
th, td {
border: 1px solid #dddddd;
text-align: left;
padding: 8px;
}
tr:nth-child(even) {
background-color: #f2f2f2;
}
</style>
The AI doesn't understand that we've done this and is just re-implementing Bootstrap: https://github.com/matdevdug/gcp-iam-reference/pull/5/files#diff-a8e8dd2ad94897b3e1d15ec0de6c7cfeb760c15c2bd62d828acba2317189a5a5
It's not adding it to the menu bar, there are actually a lot of pretty basic misses here. I wouldn't accept this PR from a person, but let's see if it works!
=> ERROR [6/8] RUN wget https://raw.githubusercontent.com/Cyclenerd/google-cloud-pricing-cost-calculator/master/pricing.yml -O pricing.yml 0.1s
------
> [6/8] RUN wget https://raw.githubusercontent.com/Cyclenerd/google-cloud-pricing-cost-calculator/master/pricing.yml -O pricing.yml:
0.104 /bin/sh: 1: wget: not foundNo worries, easy to fix.
Alright fixed wget, let's try again!
2024-06-18 11:18:57 File "/usr/local/lib/python3.12/site-packages/gunicorn/util.py", line 371, in import_app
2024-06-18 11:18:57 mod = importlib.import_module(module)
2024-06-18 11:18:57 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2024-06-18 11:18:57 File "/usr/local/lib/python3.12/importlib/__init__.py", line 90, in import_module
2024-06-18 11:18:57 return _bootstrap._gcd_import(name[level:], package, level)
2024-06-18 11:18:57 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2024-06-18 11:18:57 File "<frozen importlib._bootstrap>", line 1387, in _gcd_import
2024-06-18 11:18:57 File "<frozen importlib._bootstrap>", line 1360, in _find_and_load
2024-06-18 11:18:57 File "<frozen importlib._bootstrap>", line 1331, in _find_and_load_unlocked
2024-06-18 11:18:57 File "<frozen importlib._bootstrap>", line 935, in _load_unlocked
2024-06-18 11:18:57 File "<frozen importlib._bootstrap_external>", line 995, in exec_module
2024-06-18 11:18:57 File "<frozen importlib._bootstrap>", line 488, in _call_with_frames_removed
2024-06-18 11:18:57 File "/app/main.py", line 2, in <module>
2024-06-18 11:18:57 import yaml
2024-06-18 11:18:57 ModuleNotFoundError: No module named 'yaml'Yeah I did anticipate this one. Alright let's add PyYAML so there's something to import. I'll give AI a break on this one, this is a dumb Python thing.
Ok so it didn't add it to the menu, it didn't follow the style conventions, but did it at least work? Also no.
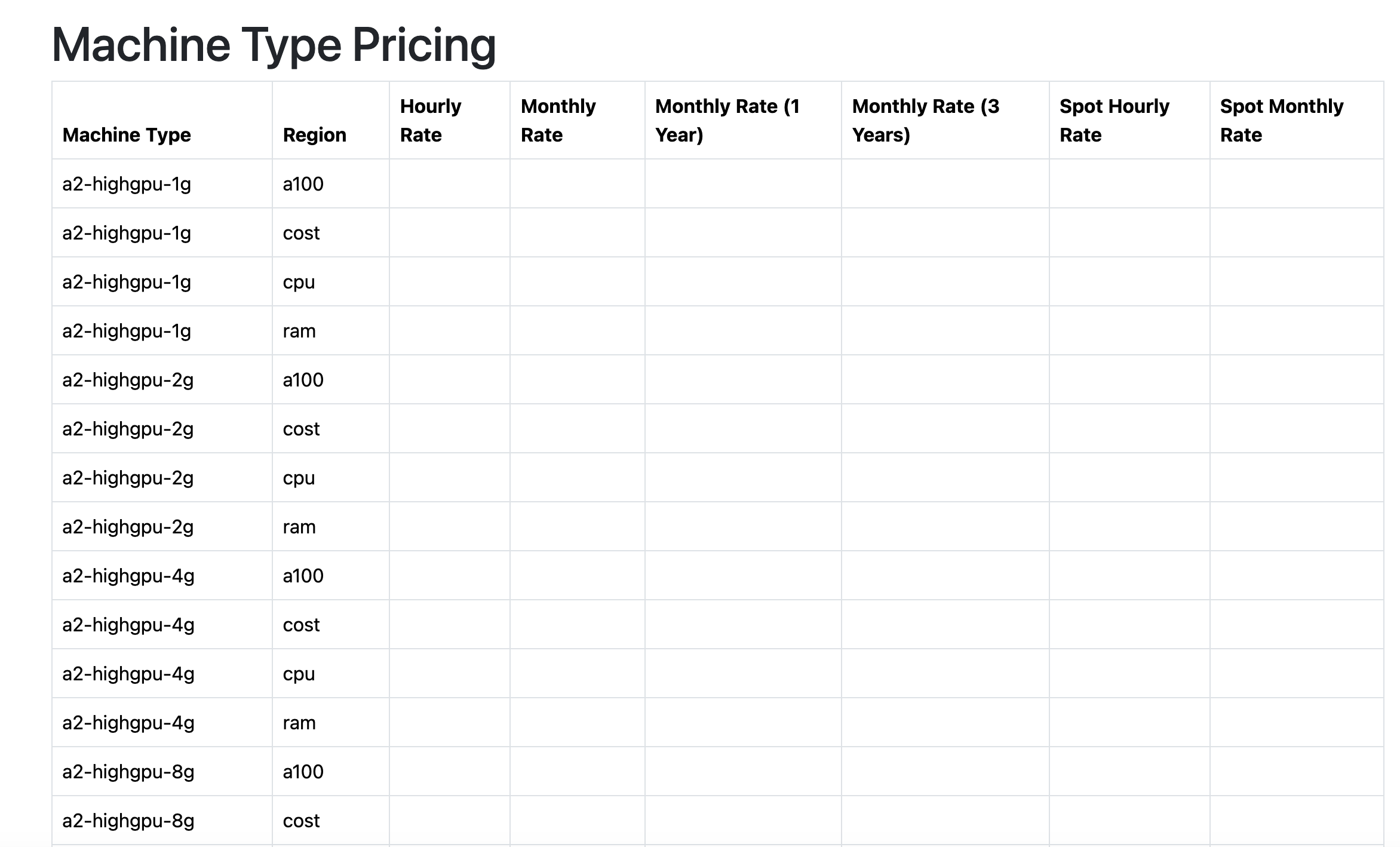
I'm not sure how it could have done a worse job to be honest. I understand what it did wrong and why this ended up like it did, but the work involved in fixing it exceeds the amount of work it would take for me to do it myself by scratch. The point of this was to give it a pretty simple concept (parse a YAML file) and see what it did.
Conclusion
I'm sure this tool is useful to someone on Earth. That person probably hates programming and gets no joy out of it, looking for something that could help them spend less time doing it. I am not that person. Having a tool that makes stuff that looks right but ends up broken is worse than not having the tool at all.
If you are a person maintaining an extremely simple thing with amazing test coverage, I guess go for it. Otherwise this is just a great way to get PRs that look right and completely waste your time. I'm sure there are ways to "prompt engineer" this better and if someone wants to tell me what I could do, I'm glad to re-run the test. However as it exists now, this is not worth using.
If you want to use it, here are my tips:
- Your source of data must be inside of the repo, it doesn't like making network calls
- It doesn't seem to go check any sort of requirements file for Python, so assume the dependencies are wrong
- It understands Dockerfile but not checking if a binary is present so add a check for that
- It seems to do better with JSON than YAML
Questions/comments/concerns: https://c.im/@matdevdug