My code doesn't compile. Why?
The number of times in my career I have been asked a variation on "why doesn't my application work" is shocking. When you meet up with Operations people for drinks, you'll hear endless variations on it. Application teams attempting to assign ownership of a bug to a networking team because they didn't account for timeouts. Infrastructure teams being paged in the middle of the night because an application suddenly logs 10x what it did before and there are disk space issues. But to me nothing beats the developer who pings me being like "I'm getting an error message in testing from my application and I'd like you to take a look".
It is baffling on many levels to me. First, I am not an application developer and never have been. I enjoy writing code, mostly scripting in Python, as a way to reliably solve problems in my own field. I have very little context on what your application may even do, as I deal with many application demands every week. I'm not in your retros or part of your sprint planning. I likely don't even know what "working" means in the context of your app.
Yet as the years go on the number of developers who approach me and say "this worked on my laptop, it doesn't work in the test environment, why" has steadily increased. Often they have not even bothered to do basic troubleshooting, things like read the documentation on what the error message is attempting to tell you. Sometimes I don't even get an error message in these reports, just a development saying "this page doesn't load for me now but it did before". The number of times I have sent a full-time Node developer a link to the Node.js docs is too high.
Part of my bafflement is this is not acceptable behavior among Operations teams. When I was starting out, I would never have wandered up to the Senior Network Administrator and reported a bug like "I sometimes have timeouts that go away. Do you know why?" I would have been politely but sternly told to do more troubleshooting. Because in my experience Operations is learned on the job, there was a culture of training and patience with junior members of the team. Along with that was a clear understanding that it was my obligation to demonstrate to the person I was reporting this error to:
1. What specifically the error was.
2. Why that error was something that belonged to them.
Somehow in the increased lack of distinction between Development and Operations, some developers, especially younger ones, have come to see Operations as their IT department. If a problem wasn't immediately recognizable as one resulting from their work, it might be because of "the servers" or "the network", meaning we could stop what we were doing and ask Operations to rule that out before continuing.
How did we get here?
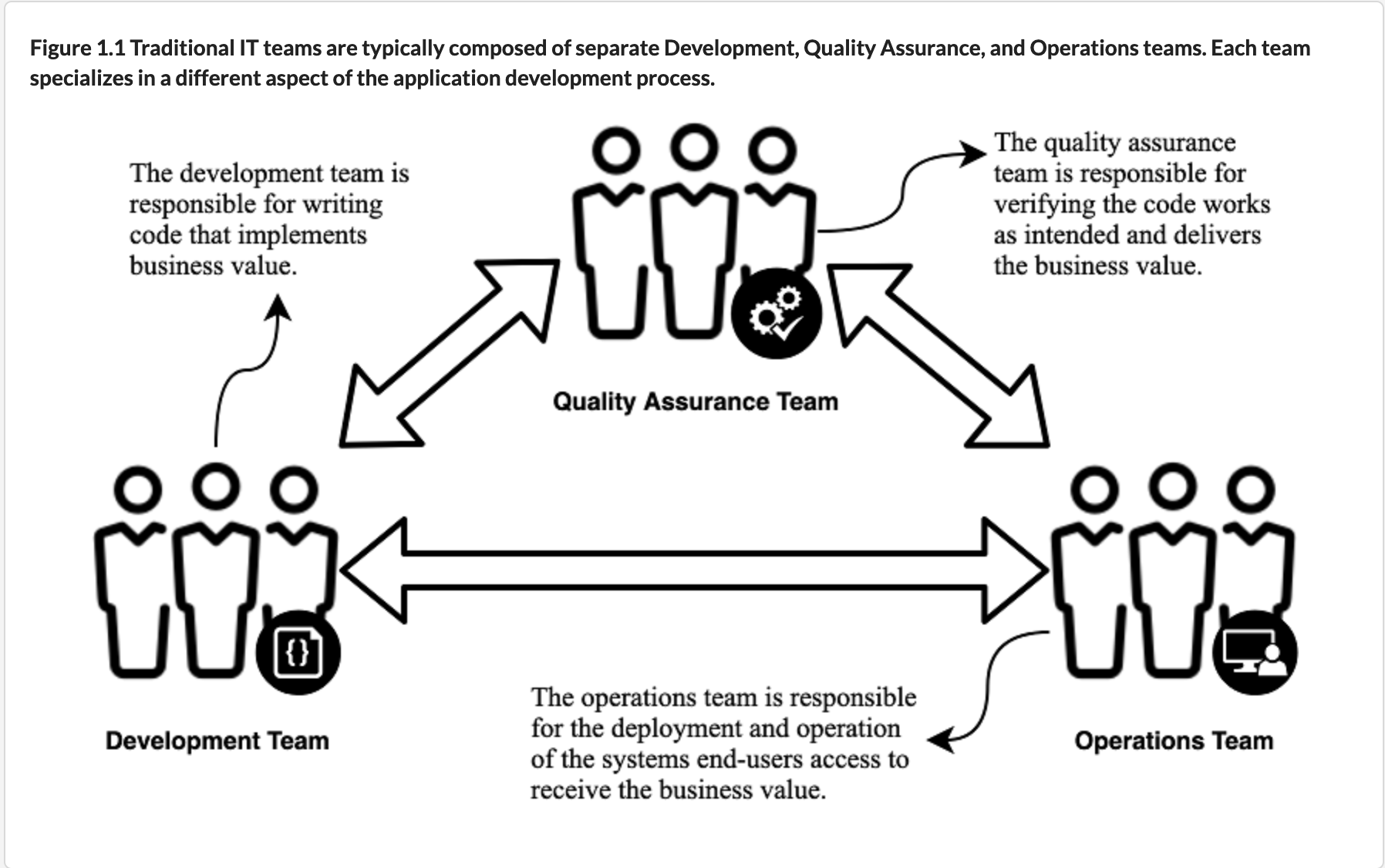
First they came for my QA team...
When I started my career in Operations, it was very different from what exists today. Everything lived in or around datacenters for us, the lead time on new servers was often measured in months not minutes and we mostly lived in our own world. There were network engineers, managing the switches and routers. The sysadmins ruled over the boxes and, if the org was large enough, we had a SAN engineer managing the massive collection of data.
Our flow in the pipeline was pretty simple. The QA team approved some software for release and we took that software to our system along with a runbook. We treated software mostly like a black box, with whatever we needed to know contained inside of the runbook. Inside were instructions on how to deploy it, how to tell if it was working and what to do if it wasn't working. There was very little expectation that we could do much to help you. If a deployment went poorly in the initial rollout, we would roll back and then basically wait for development to tell us what to do.
There was not a lot of debate over who "owned" an issue. If the runbook for an application didn't result in the successful deployment of an application, it went back to development. Have a problem with the database? That's why we have two DBAs. Getting errors on the SAN? Talk to the SAN engineer. It was a slow process at times, but it wasn't confusing. Because it was slower, often developers and these experts could sit down and share knowledge. Sometimes we didn't agree, but we all had the same goal: ship a good product to the customer in a low-stress way.
Deployments were events and we tried to steal from more mature industries. Runbooks were an attempt to quantify the chaotic nature of software development, requiring at least someone vaguely familiar with how the application worked to sit down and write something about it. We would all sit there and watch error logs, checking to see if some bash script check failed. It was not a fast process as compared to now but it was simple to understand.
Of course this flow was simply too straightforward and involved too many employees for MBAs to allow it to survive. First we killed QA, something I am still angry about. The responsibility for ensuring that the product "worked as intended" was shifted to development teams, armed with testing frameworks that allowed them to confirm that their API endpoints returned something like the right thing. Combined with the complete garbage fire that is browser testing, we now had incredibly clunky long running testing stacks that could roughly approximate a single bad QA engineer. Thank god for that reduced headcount.
With the removal of QA came increased pressure to ship software more often. This made sense to a lot of us as smaller more frequent changes certainly seemed less dangerous than infrequent massive changes of the entire codebase. Operations teams started to see more and more pressure to get stuff out the door quickly. New features attract customers, so being the first and fastest to ship had a real competitive advantage. Release windows shrunk, from cutting a release every month to every week. The pressure to ship also increased as management looked at the competitive landscape growing more aggressive with cycles.
Soon the runbook was gone and now developers ran their own deployment schedule, pushing code out all the time. This was embraced with a philosophy called DevOps, a concept that the two groups, now that QA was dead and buried, would be able to tightly integrate to close this gap even more. Of course this was sold to Development and Operations as if it would somehow "empower" better work out of them, which was of course complete nonsense.
Instead we now had a world where all ownership of problems was muddled and everyone ended up owning everything.

DevOps is not a decision made in isolation
When Operations shifted focus to the cloud and to more GitOps style processes, there was an understanding that we were all making a very specific set of tradeoffs. We were trading tight cost control for speed, so never again would a lack of resources in our data centers cause a single feature not to launch. We were also trading safety for speed. Nobody was going to sit there and babysit a deploy, the source of truth was in the code. If something went wrong or the entire stack collapsed, we could "roll back", a concept that works better in annoying tech conference slide decks then in practice.
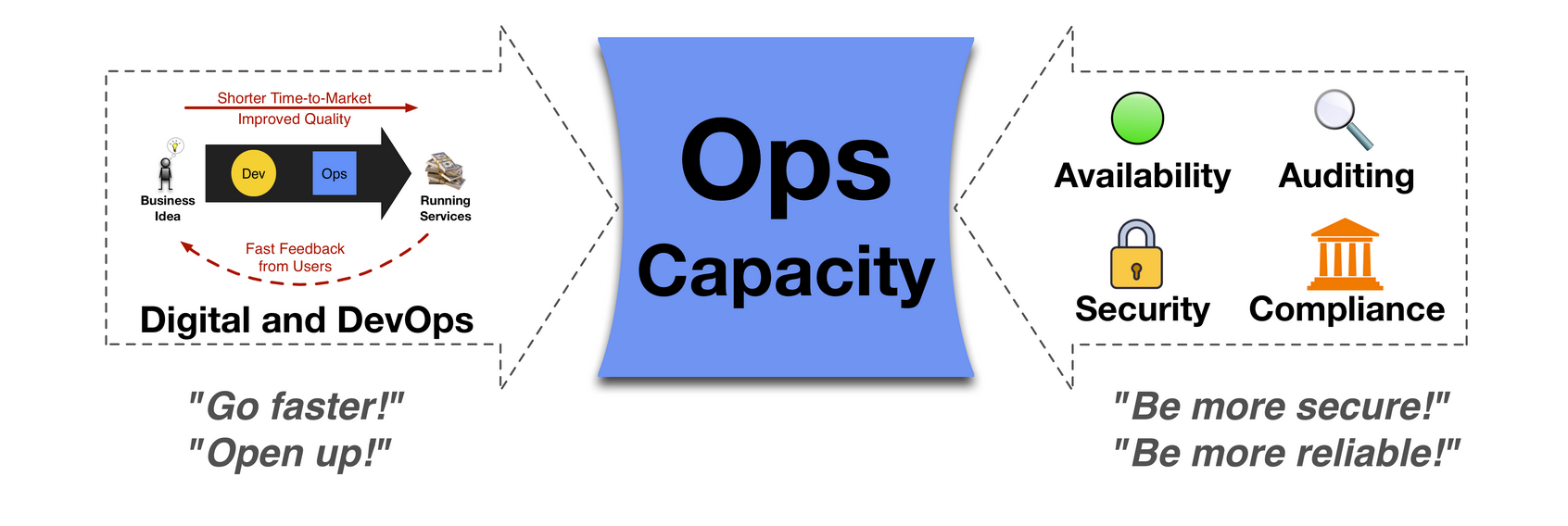
We soon found ourselves more pressed than ever. We still had all the responsibilities we had before, ensuring the application was available, monitored, secure and compliant. However we also built and maintained all these new pipelines, laying the groundwork for empowering development to get code out quickly and safely without us being involved. This involved massive retraining among operations teams, shifting from their traditional world of bash scripts and Linux to learning the low-level details of their cloud provider and an infrastructure as code system like Terraform.
For many businesses, the wheels came off the bus pretty quickly. Operations teams struggled to keep the balls in the air, shifting focus between business concerns like auditing and compliance to laying the track for Development to launch their products. Soon many developers, frustrated with waiting, would attempt to simply "jump over" Operations. If something was easy to do in the AWS web console on their personal account, certainly it was trivial and safe to do in the production system? We can always roll back!
In reality there are times when you can "roll back" infrastructure and there are times you can't. There are mistakes or errors you can make in configuring infrastructure that are so catastrophic it is difficult to estimate their potential impact to a business. So quickly Operations teams learned they needed to install rails to infrastructure as code, guiding people to the happy safe path in a reliable and consistent way. This is slow though and after awhile started to look a lot like what was happening before with datacenters. Businesses were spending more on the cloud than on their old datacenters but where was the speed?
Inside engineering, getting both sides of the equation to agree in the beginning "fewer blockers to deploying to production is good" was the trivial part. The fiercer fights were over ownership. Who is responsible in the middle of the night if an application starts to return errors? Historically operations was on-call, relying on those playbooks to either resolve the problem or escalate it. Now we had applications going out with no documentation, no clear safety design, no QA vetting and sometimes no developers on-call to fix it. Who owns an RDS problem?
Tools like Docker made this problem worse, with developers able to craft perfect application stacks on their laptops and push them to production with mixed results. As cloud providers came to provide more and more of the functionality, soon for many teams every problem with those providers also fell into Operations lap. Issues with SQS? Probably an Operations issue. Not sure why you are getting a CORS error on S3? I guess also an Operations problem!
The dream of perfect harmony was destroyed with the harsh reality that someone has to own a problem. It can't be a community issue, someone needs to sit down and work on it. You have an incentive in modern companies to not be the problem person, but instead to ship new features today. Nobody gets promoted for maintenance or passing a security audit.
Where we are now
In my opinion the situation has never been more bleak. Development has been completely overwhelmed with a massive increase in the scope of their responsibilities (RIP QA) but also with unrealistic expectations by management as to speed. With all restrictions lifted, it is now possible and expected that a single application will get deployed multiple times a day. There are no real limiters except for the team itself in terms of how fast they can ship features to customers.
Of course this is just a fundamental misunderstanding about how software development works. It isn't a factory and they aren't "code machines". The act of writing code is a creative exercise, something that people take pride in. Developers, in my experience, don't like shipping bad or rushed features. What we call "technical debt" can best be described as "the shortcuts taken today that have to be paid off later". Making an application is like building a house, you can take shortcuts but they aren't free. Someone pays for them later, but probably not the current executive in charge of your specific company so who cares.
Due to this, developers are not incentivized or even encouraged to gain broader knowledge of how their systems work. Whereas before you might reasonable be expected to understand how RabbitMQ works, SQS is "put message in, get message out, oh no message is not there, open ticket with Ops". This situation has gotten so bad that we have now seen the adoption of widespread large-scale systems like Kubernetes who attempt to abstract away the entire stack. Now there is a network overlay, a storage overlay, healthchecks and rollbacks all inside the stack running inside of the abstraction that is a cloud provider.
Despite the bullshit about how this was going to empower us to do "our best work faster", the results have been clear. Operations is drowning, forced to learn both all the fundamentals their peers had to learn (Linux, networking, scripting languages, logging and monitoring) along with one or more cloud providers (how do network interfaces attach to EC2 instances, what are the specific rules for how to invalidate caches on Cloudfront, walk me through IAM Profiles). On top of all of that, they need to understand the abstraction on top of this abstraction, the nuance of how K8 and AWS interact, how storage works with EBS, what are you monitoring and what is it doing. They also need to learn more code than before, now often expected to write relatively complicated internal applications which manage these processes.
With this came monitoring and observability responsibilities as well. Harvesting the metrics and logs, shipping them somewhere, parsing and shipping them, then finally making them consumable by development. A group of engineers who know nothing about how the application works, who have no control over how it functions or what decisions it makes, need to own determining whether it is working or not. The concept makes no sense. Nuclear reactor technicians don't ask me if the reactor is working well or not, I have no idea what to even look for.
Developers simply do not have the excess capacity to sit down and learn this. They are certainly intellectually capable, but their incentives are totally misaligned. Every meeting, retro and sprint is about getting features out the door faster, but of course with full test coverage and if it could be done in the new cool language that would be ideal. When they encounter a problem they don't know the answer to, they turn to the Operations team because we have decided that means "the people who own everything else in the entire stack".
It's ridiculous and unsustainable. Part of it is our fault, we sell tools like Docker and Kubernetes and AWS as "incredibly easy to use", not being honest that all of them have complexity which matter more as you go. That testing an application on your laptop and hitting a "go to production" button works, until it doesn't. Someone will always have to own that gap and nobody wants to, because there is no incentive to. Who wants to own the outage, the fuck up or the slow down? Not me.
In the meantime I'll be here, explaining to someone we cannot give full administrator IAM rights to their serverless application just because the internet said that made it easier to deploy. It's not their fault, they were told this was easy.

Thoughts/opinions? @duggan_mathew on twitter