Imagine you had a dog. You got the dog when it was young, trained and raised it. This animal was a part of your family and you gave it little collars and cute little clothes with your family name on it. The dog came to special events and soon thought of this place as its home and you all as loved ones. Then one day with no warning, you locked the dog out of the house. You and the other adults in the house had decided getting rid of any random dog was important to the bank that owned your self, so you locked the door. Eventually it wandered off, unsure of why you had done this, still wearing the sad little collar and t-shirt with your name.
If Americans saw this in a movie, people would be warning each other that it was "too hard to watch". In real life, this is an experience that a huge percentage of people working in tech will go through. It is a jarring thing to watch, seeing former coworkers told they don't work there anymore by deactivating their badges and watching them try to swipe through the door. I had an older coworker who we'll call Bob, upon learning it was layoffs, took off for home. "I can't watch this again" he said as he quickly shoved stuff into his bag and ran out the door.
In that moment all illusion vanishes. This place isn't your home, these people aren't your friends and your executive leadership would run you over with their cars if you stood between them and revenue growth. Your relationship to work changes forever. You will never again believe that you are "critical" to the company or that the company is interested in you as a person. I used to think before the layoffs that Bob was a cynic, never volunteering for things, always double-checking the fine print of any promise made by leadership. I was wrong and he was right.
Layoffs don't work
Let us set aside the morality of layoffs for a moment. Do layoffs work? Are these companies better positioned after they terminate some large percentage of people to compete? The answer appears to be no:
The current study investigated the financial effects of downsizing in Fortune 1000 Companies during a five-year period characterized by continuous economic growth. Return on assets, profit margin, earnings per share, revenue growth, and market capitalization were measured each year between 2003 and 2007. In general, the study found that both downsized and nondownsized companies reported positive financial outcomes during this period. The downsized companies, however, were outperformed consistently by the nondownsized ones during the initial two years following the downsizing. By the third year, these differences became statistically nonsignificant. Consequently, although many companies appear to conduct downsizing because the firm is in dire financial trouble, the results of this study clearly indicated that downsizing does not enhance companies' financial competitiveness in the near-term. The authors discuss the theoretical and practical implications of these findings.
In all my searching I wasn't able to find any hard data which suggests layoffs either enable a company to better compete or improve earnings in the long term. The logic executives employ seems to make sense on its face. You eliminate employees and departments which enable you to use that revenue to invest in more profitable areas of the business. You are scaling to meet demand, so you don't have employees churning away at something they don't need to be working on. Finally you are eliminating low performance employees.
It’s about the triumph of short-termism, says Wharton management professor Adam Cobb. “For most firms, labor represents a fairly significant cost. So, if you think profit is not where you want it to be, you say, ‘I can pull this lever and the costs will go down.’ There was a time when social norms around laying off workers when the firm is performing relatively well would have made it harder. Now it’s fairly normal activity.”
This all tracks until you start getting into the details. Think about it strictly from a financial perspective. Firms hire during boom periods, paying a premium for talent. Then they layoff people, incurring the institutional hit of losing all of that knowledge and experience. Next time they need to hire, they're paying that premium again. It is classic buying high and selling low. In retail and customer facing channels, this results in a worse customer experience, meaning the move designed to save you money costs you more in the long term. Investors don't even always reward you for doing it, even though they ask for them.
Among the current tech companies this logic makes even less sense. Meta, Alphabet, PayPal and others are profitable companies, so this isn't even a desperate bid to stay alive. These companies are laying people off in response to investor demand and imitative behavior. After decades of research, executive know layoffs don't do what it says on the box, but their board is asking why they aren't considering layoffs and so they proceed anyway.
Low-performing Employees
A common argument I've heard is "well ok, maybe layoffs don't help the company directly, but it is an opportunity to get rid of dead weight". Sure, except presumably at-will employers could have done that at any time if they had hard data that suggested this pool of employees weren't working out.
Recently, we asked 30 North American human resource executives about their experiences conducting white-collar layoffs not based on seniority — and found that many believed their organizations had made some serious mistakes. More than one-third of the executives we interviewed thought that their companies should have let more people go, and almost one-third thought they should have laid off fewer people. In addition, nearly one-third of the executives thought their companies terminated the wrong person at least 20% of the time, and approximately an additional quarter indicated that their companies made the wrong decision 10% of the time. More than one-quarter of the respondents indicated that their biggest error was terminating someone who should have been retained, while more than 70% reported that their biggest error was retaining someone who should have been terminated.
Coming up with a scientific way of determining who is doing a good job and who is doing a bad job is extremely hard. If your organization wasn't able to identify those people before layoffs, you can't do it at layoff time. My experience with layoffs is it is less a measure of quality and more an opportunity for leadership to purge employees who are expensive, sick or aren't friends with their bosses.
All in all we know layoffs don't do the following:
Layoffs don't increase productivity or employee engagement (link)
It doesn't keep the people you have. For example, layoffs targeting just 1% of the workforce preceded, on average, a 31% increase in turnover.Source
It doesn't help you innovate or reliably get rid of low-performance employees.
Human Cost
Layoffs also kill people. Not in the spiritual sense, but in the real physical sense. In the light beach book "MORTALITY, MASS-LAYOFFS, AND CAREER OUTCOMES: AN ANALYSIS USING ADMINISTRATIVE DATA" which you can download here we see some heavy human costs for this process.
We find that job displacement leads to a 15-20% increase in death rates during the following 20 years. If such increases were sustained beyond this period, they would imply a loss in life expectancy of about 1.5 years for a worker displaced at age 40.
This isn't a trivial amount of damage being done here. Whatever goodwill an employer has built with their employees is burned to the ground. The people you have left are going to trust you less, not work as hard, be more stressed and resent you more. This is at a time when you are asking more of the remaining teams, feeding into that increase in turnover.
If you were having trouble executing before, there is no way in hell it gets better after this.
Alternatives
“Companies often attempt to move out of an unattractive game and into an attractive one through acquisition. Unfortunately, it rarely works. A company that is unable to strategize its way out of a current challenging game will not necessarily excel at a different one—not without a thoughtful approach to building a strategy in both industries. Most often, an acquisition adds complexity to an already scattered and fragmented strategy, making it even harder to win overall.”
So if layoffs don't work, what are the options? SAS Institute has always been presented as a fascinating outlier in this area as a software company that bucks the trends. One example I kept seeing was SAS Institute has never done layoffs, instead hiring during downturns as a way to pick up talent for cheap. You can read about it here.
Now in reality the SAS Institute has done small rounds of layoffs, so this often-repeated story isn't as true as it sounds. Here they are laying off 100 people. These folks were in charge of a lot of office operations during a time when nobody was going to the office but it still counts. However the logic behind not doing mass layoffs still holds true despite the lie being repeated that SAS Institute never ever does them.
Steve Jobs also bucked this trend somewhat famously.
"We've had one of these before, when the dot-com bubble burst. What I told our company was that we were just going to invest our way through the downturn, that we weren't going to lay off people, that we'd taken a tremendous amount of effort to get them into Apple in the first place -- the last thing we were going to do is lay them off. And we were going to keep funding. In fact we were going to up our R&D budget so that we would be ahead of our competitors when the downturn was over. And that's exactly what we did. And it worked. And that's exactly what we'll do this time."
If you truly measure the amount of work it takes to onboard employees, get them familiar with your procedures and expectations and retain them during the boom times, it really stops making sense to jettison them during survivable downturns. These panic layoffs that aren't based in any sort of hard science or logic are amazing opportunities for company who are willing to weather some bad times and emerge intact with a motivated workforce.
It's not altruism at work. Rather, executives at no-layoff companies argue that maintaining their ranks even in terrible times breeds fierce loyalty, higher productivity, and the innovation needed to enable them to snap back once the economy recovers.
So if you work for any company, especially in tech, and leadership starts discussing layoffs, you should know a few things. They know it doesn't do what they say it does. They don't care that it is going to cause actual physical harm to some of the people they are doing it to. These execs are also aware it isn't going to be a reliable way of getting rid of low-performing employees or retaining high performing ones.
If you choose to stay after a round of layoffs, you are going to be asked to do more with less. The people you work with are going to be disinterested in their jobs or careers and likely less helpful and productive than ever before. Any loyalty or allegiance to the company is dead and buried, so expect to see more politics and manipulations as managers attempt to give leadership what they want in order to survive.
On the plus side you'll never have the same attitude towards work again.
In the light of GoTo admitting their breach was worse than initially reported I have found myself both discussing passwords with people more than ever before and directing a metric ton of business towards 1Password. However, it has raised an obvious question for me: why are users involved with passwords at all? Why is this still something I have to talk to my grandparents about?
Let us discuss your password storage system again
All the major browsers have password managers that sync across devices. These stores are (as far as I can tell) reasonably secure. Access to the device would reveal them, but excluding physical access to an unlocked computer they seem fine. There is a common API, the Credentials Management API docs here that allow for a website to query the password store inside of the browser for the login, even allowing for Federated logins or different or same logins for subdomains as part of the spec. This makes for a truly effortless login experience for users without needing them to do anything. These browsers already have syncing with a master password concept across mobile/desktop and can generate passwords upon request.
If the browser can: generate a password, store a password, sync a password and return the password when asked, why am I telling people to download another tool that does the exact same thing? A tool made by people who didn't make the browser and most of whom haven't been independently vetted by anybody.
Surely it can't be that easy
So when doing some searching about the Credentials Management API, one of the sites you run across a lot is this demo site: https://credential-management-sample.appspot.com/. This allows you to register an account, logout and then see the login auto-filled by the browser when you get back to it. The concept seems to work as expected on Chrome.
Bummer
Alright so it doesn't work on Firefox and Safari but honestly, neither do 10% of the websites I go to. 88% of all the users in the world still isn't bad, so I'm not willing to throw the idea out entirely.
Diving into how the process works, again, it seems pretty straight forward.
If the user has a login then get it. It supports federated logins or passwords and falls back to redirecting to the sign-in page if you cannot locate a login. I tried the samples available here and they seemed to mostly be plug and play. In fact in my testing this seemed to be a far superior user experience to using traditional password managers with browser extensions.
Also remember that even for browsers that don't support it, I'm just falling back to the normal password storage system. So for websites that support it, the experience is magical on Chrome and the same as using a password manager with every other browser. It doesn't cost anything, it isn't complicated and it is a better experience.
I know someone out there is gearing up
Are Password Managers Better?
One common theme when you search for this stuff is an often repeated opinion that browser password managers are trash and password managers are better. Looking more into how they work, this seems to come with some pretty big asterisks. Most password managers seem to use some JavaScript from their CDN to insert their interface into the form values.
This is a little nerve-racking because websites could interact with that element but also the communication between the password manager is a potential source of problems. Communication to a local HTTP target seems to make sense, but this can be the source of problems (and has been in the past). ExampleExampleExample
So at a minimum you'd need the tool you chose to meet these requirements to reach or exceed the same level of security as the browser built-in manager.
The add-on runs in a sandboxed background page
Communication between the password manager and the page isn't happening in the DOM
Any password element would need to be an iframe or something else that stops the site from interacting with the content
CSP is set up flawlessly
Communication between the extension and anything outside of the extension is secure and involves some verification step
Code validation in pretty much every direction: is the browser non-modified, is the server process valid, is the extension good, etc
This isn't even getting to the actual meat of the encryption on the secrets or the security of the syncing. We're just talking about whether the thing that interacts with the secrets and jams them into the page.
To make a product that does this and does it well and consistently across releases isn't an easy problem. Monitoring for regressions and breaches would be critical, disclosures would be super important to end users and you would need to get your stack vetted by an outside firm kind of a lot. I trust the developers of my web browser in part because I have to and because, over the years, Mozilla has been pretty good to me. The entire browser stack is under constant attack because it has effectively become the new OS we all run.
Well these companies are really good at all that
Are they? Frankly in my research I wasn't really blown away with the amount of technical auditing most of these companies seem to do or produce any evidence of. The only exception to this was 1Password and Bitwarden.
1Password
I love that they have a whitepaper available here but nobody finished writing it.
No rush I guess
However they do have actual independent audits of their software. Recent audits done by reputable firms and available for review. You can see all these here. For the record this should be on every single one of these companies website for public review.
Keeper Password Manager
I found what they call a whitepaper but it's 17 pages and basically says "We're ISO certified". That's great I guess, but not the level of detail I would expect at all. You can read it here. This doesn't mean you are doing things correctly, just that you have generated enough documentation to get ISO certified.
Not only do we implement the most secure levels of encryption, we also adhere to very strict internal
practices that are continually audited by third parties to help ensure that we continue to develop secure software and
provide the world’s most secure cybersecurity platform.
Great, can I read these audits?
Dropbox Password
Nothing seems to exist discussing this products technical merits at all. I don't know how it works. I can look into it more if someone can point me to something else, but it seems to be an encrypted file that lives in your Dropbox folder secured with a key generated by Dropbox and returned to you upon enrollment.
Dashlane
I found a great security assessment from 2016 that seemed to suggest the service was doing pretty well. You can get that here. I wasn't able to find one more recent. Reading their whitepaper here they actually do go into a lot of detail and explain more about how the service works, which is great and I commend them for that.
It's not sufficient though. I'm glad you understand how the process should work but I have no idea if that is still happening or if this is more of an aspirational document. I often understand the ideal way software should work but the real skill of the thing is getting it to work that way.
Bitwarden
They absolutely kill it in this department. Everything about them is out in the open like it should be. However sometimes they discover issues, which is good for the project but underscores what I was talking about above. It is hard to write a service that attempts to handle your most sensitive data and inject that data into random websites.
These products introduce a lot of complexity and failure points into the secret management game. All of them with the exception of 1Password seem to really bet the farm on the solo Master/Primary Password concept. This is great if your user picks a good password, but statistically this idea seems super flawed to me. This is a password they're going to enter all the time, won't they pick a crap one? Even with 100,000 iterations on that password it's pretty dangerous.
Plus if you are going to rely on the concept of "well if the Master/Primary Password is good then the account is secure" then we're certainly not justifying the extra work here. It's as good as the Firefox password manager and not as good as the Safari password manager. Download Firefox and set a good Primary Password.
Can we be honest with each other?
I want you to go to this website and I want you to type in your parents password. You know the one, the one they use for everything? The one that's been shouted through the halls and texted/emailed/written on so many post-it notes that any concept of security has long since left the building.
That's the password they're gonna use to secure the vault. They shouldn't, but they're gonna. Now I want you to continue on this trust exercise with me. If someone got access to read/write in a random cross-section of your coworkers computers, are passwords really the thing that is gonna destroy your life? Not an errant PDF, Excel document of customer data or unsecured AWS API key?
I get it, security stuff is fun to read. "How many super computers will it take to break in" feels very sci-fi.
Well but my family/coworkers/lovers all share passwords
I'm not saying there is zero value to a product where there is a concept of sharing and organizing passwords with a nice UI, but there's also no default universal way of doing it. If all the password managers made a spec that they held to that allowed for secure bidirectional sharing between these services, I'd say "yeah the cost/benefit is likely worth it". However chances are if we're in a rush and sharing passwords, I'm going to send you the password through an insecure system anyway.
Plus the concept of sharing introduces ANOTHER huge layer of possible problems. Permission mistakes, associating the secret with the wrong user, the user copying the secret into their personal vault and not getting updated when the shared secret is updated are all weird issues I've seen at workplaces. To add insult to injury, the requirements of getting someone added to a shared folder they need is often so time-consuming people will just bypass the process and copy/paste the secret anyway.
Also let's be honest among ourselves here. Creating one shared login for a bunch of employees to use was always a bad idea. We all knew it was a bad idea and you knew it while you were doing it. Somewhere in the back of your mind you were like "boy it'll suck if someone decides to quit and steals these".
I think we can all agree on this
I know, "users will do it anyway". Sure but you don't have to make it institutional policy. The argument of "well users are gonna share passwords so we should pay a service to allow them to do it easier" doesn't make a lot of sense. I also know sometimes you can't avoid it, but for those values, if they're that sensitive, it might not make sense to share them across all employees in a department. Might make more sense to set them up with a local tool like pass.
Browsers don't prompt the user to make a Master/Primary Password
That is true and perhaps the biggest point in the category of "you should use a password manager". The way the different browsers do this is weird. Chrome effectively uses the users login as the key, on Windows calling a Windows API that encrypts the sqlite database and decrypts it when the user logs in. On the Mac there is a login keychain entry of a random value that seems to serve the same function. If the user is logged in, the sqlite database is accessible. If they aren't, it isn't.
On Firefox there is a Primary Password that you can set that effectively works like most of the password managers that we saw. Unlike password managers this isn't synced, so you would set a different primary for every Firefox device. That means the Firefox account is still controlling what syncs to what, this just ensures that a user who takes the database of username and passwords would need this key to decrypt it.
So for Chrome if your user is logged in, the entire password database is available. On macOS they can get access to the decryption key through the login keychain and on Firefox the value is encrypted in the file but for additional security and disallowing for random users to interact with it through the browser. There is a great write-up of how local browser password stores work here.
There are more steps than Chrome but allows for a Master Password
Is that a sufficient level of security?
Honestly? Yeah I think so. The browser prompts the user to generate a secure value, stores the value, syncs the value securely and then, for 88% of the users on the web, the site can use a well-documented API to automatically fill in that value in the future. I'd love to see Chrome add a few more security levels, some concept of Primary Password so that I can lock the local password storage to something that isn't just me being logged into my user account.
However we're also rapidly reaching a point where the common wisdom is that everything important needs 2FA. So if we're already going to treat the password as a tiered approach, I think a pretty good argument could be made that it is safer for a user to store their passwords in the browser store (understanding that the password was always something that a malicious actor with access to their user account could grab through keyloggers/clipboard theft/etc) and having a 2FA on a phone as compared to what a lot of people do, which is keep the 2FA and the password inside of the same third-party password manager.
TOTPs are just password x2
When you scan that QR code, you are getting back a string that looks something like this:
This combined with time gets you your 6 digit code. The value of this approach is twofold: does the user posses another source of authentication and now there is a secret which we know is randomly generated that effectively serves as a second password. This secret isn't exposed to normal users as a string, so we don't need to worry about that.
If I have the secret value I can make the same code. If we remove the second device component like we do with password managers, what we're saying is "TOTP is just another random password". If we had a truly random password to begin with, I'm not adding much to the security model by adding in the 2FA but sticking it in the same place.
What if they break into my phone
On iOS even without a Primary password set on Firefox, it prompts for FaceID authentication before allowing someone access to the list of stored passwords. So that's already a pretty intense level of security. Add in a Primary password and we've reached the same level of security as 1Password. Chrome is the same story.
It's the same level of security with Android. Attempt to open the saved passwords, get a PIN or biometric check depending on the phone. That's pretty good! Extra worried about it? Use a TOTP app that requires biometrics before they reveal that code. Here is one for iOS
Even if someone steals your phone and attempts to break into your accounts, there are some non-trivial security measures in their way with the standard browser password storage combined with a free TOTP app that checks identity.
I use my password manager for more than passwords
Sure and so do I, but that doesn't really matter to my point. The common wisdom that all users would benefit from the use of a dedicated password manager is iffy at best. We've now seen a commonly recommended one become so catastrophically breached that anything stored there is now needs to be considered leaked. This isn't the first credential leak or the 10th or the 100th, but now there is just a constant never-ending parade of password leaks and cracks.
So if that is true and a single password cannot ever truly serve as the single step of authentication for important resources, then we're always going to be relying on adding on another factor. Therefore the value a normal user gets out of a password manager vs the browser they're already using is minimal. With passkeys and Credentials Management API the era of exposing the user to the actual values being used in the authentication step is coming to a close anyway. Keys synced by the browser vendor will become the default authentication step for users.
In the light of that reality, it doesn't really make sense to bother users with the additional work and hassle of running a new program to manage secrets.
Summary of my rant
Normal users don't need to worry about password managers and would be better served by using the passwords the browser generates and investing that effort into adding 2FA using a code app on their phone or a YubiKey.
In the face of new APIs and standards, the process of attempting to manage secrets with an external manager will becoming exceedingly challenging. It is going to be much much easier to pick one browser and commit to it everywhere vs attempting to use a tool to inject all these secrets
With the frequency of breaches we've already accepted that passwords at, at best, part of a complete auth story. The best solution we have right now is "2 passwords".
Many of the tools users rely on to manage all their secrets aren't frequently audited or if they are, any security assessment of their stack isn't being published.
For more technical users looking to store a lot of secrets for work, using something like pass will likely fulfill that need with a smaller less complicated and error-prone technical implementation. It does less so less stuff can fail.
If you are going to use a password manager, there are only two options: 1Password and Bitwarden. 1Password is the only one that doesn't rely exclusively on the user-supplied password, so if you are dealing with very important secrets this is the right option.
It is better to tell users "shared credentials are terrible and please only use them if you absolutely have no choice at all" than to set up a giant business-wide tool of shared credentials which are never rotated.
My hope is with passkeys and the Credentials Management API this isn't a forever problem. Users won't be able to export private keys, so nobody is going to be sharing accounts. The Credentials Management UI and flow is so easy for developers and users that it becomes the obvious choice for any new service. My suspicion is we'll still be telling users to set up 2FA well after its practical lifespan has ended, but all we're doing is replicating the same flow as the browser password storage.
Like it or not you are gonna start to rely on the browser password manager a lot soon, so might as well get started now.
One common question I see on Mastodon and Reddit is "I've inherited a cluster, how do I safely upgrade it". It's surprising that this still isn't a better understood process given the widespread adoption of k8s, but I've had to take over legacy clusters a few times and figured I would write up some of the tips and tricks I've found over the years to make the process easier.
A very common theme to these questions is "the version of Kubernetes is very old, what do I do". Often this question is asked with shame, but don't feel bad. K8s is better at the long-term maintenance story as compared to a few years ago, but is still a massive amount of work to keep upgraded and patched. Organizations start to fall behind almost immediately and teams are hesitant to touch a working cluster to run the upgrades.
NOTE: A lot of this doesn't apply if you are using hosted Kubernetes. In that case, the upgrade process is documented through the provider and is quite a bit less complicated.
How often do I need to upgrade Kubernetes?
This is something people new to Kubernetes seem to miss a lot, so I figured I would touch on it. Unlike a lot of legacy infrastructure projects, k8s moves very quickly in terms of versions. Upgrading can't be treated like switching to a new Linux distro LTS release, you need to plan to do it all the time.
To be fair to the Kubernetes team they've done a lot to help make this process less horrible. They have a support policy of N-2, meaning that the 3 most recent minor versions receive security and bug fixes. So you have time to get a cluster stood up and start the process of planning upgrades, but it needs to be in your initial cluster design document. You cannot wait until you are almost EOL to start thinking "how are we going to upgrade". Every release gets patched for 14 months, which seems like a lot but chances are you aren't going to be installing the absolute latest release.
Current support timeline
So the answer to "how often do you need to be rolling out upgrades to Kubernetes" is often. They are targeting 3 releases a year, down from the previous 4 releases a year. You can read the projects release goals here. However in order to vet k8s releases for your org, you'll likely need to manage several different versions at the same time in different environments. I typically try to let a minor version "bake" for at least 2 weeks in a dev environment and same for stage/sandbox whatever you call the next step. Prod version upgrades should ideally have a month of good data behind them suggesting the org won't run into problems.
My staggered layout
Dev cluster should be as close to bleeding edge as possible. A lot of this has to do with establishing SLAs for the dev environment, but the internal communication should look something like "we upgrade dev often during such and such a time and rely on it to surface early problems". My experience is you'll often hit some sort of serious issue almost immediately when you try to do this, which is good. You have time to fix it and know the maximum version you can safely upgrade to as of the day of testing.
Staging is typically a minor release behind dev. "Doesn't this mean you can get into a situation where you have incompatible YAMLs?" It can but it is common practice at this point to use per-environment YAMLs. Typically folks are much more cost-aware in dev environments and so some of the resource requests/limits are going to change. If you are looking to implement per-environment configuration check out Kustomize.
Production I try to keep as close to staging as possible. I want to keep my developers lives as easy as possible, so I don't want to split the versions endlessly. My experience with Kubernetes patch releases has been they're pretty conservative with changes and I rarely encounter problems. My release cadence for patches on the same minor version is two weeks in staging and then out to production.
IMPORTANT. Don't upgrade the minor version until it hits patch .2 AT LEAST. What does this mean?
Right now the latest version of Kubernetes is 1.26.0. I don't consider this release ready for a dev release until it hits 1.26.2. Then I start the timer on rolling from dev -> stage -> production. By the time I get the dev upgrade done and roll to staging, we're likely at the .3 release (depending on the time of year).
That's too slow. Maybe, but I've been burned quite a few times in the past by jumping too early. It's nearly impossible for the k8s team to possibly account for every use-case and guard against every regression and by the time we hit .2, there tends to be wide enough testing that most issues have been discovered. A lot of people wait until .5, which is very slow (but also the safest path).
You also need to do this with patch releases, which typically come out monthly.
If you prefer to keep track of this in RSS, good news! If you add .atom to the end of the release URL, you can add it to a reader. Example: https://github.com/kubernetes/kubernetes/releases.atom. This makes it pretty easy to keep a list of all releases. You can also just subscribe in GitHub but I find the RSS method to be a bit easier (plus super simple to script, which I'll publish later).
As new releases come out, roll latest to dev once it hits .2. I typically do this as a new cluster, leaving the old cluster there in case of serious problems. Then I'll cut over deployments to new cluster and monitor for issues. In case of massive problems, switch back to old cluster and start the documentation process for what went wrong.
When I bump the dev environment, I then circle around and bump the stage environment to one minor release below that. I don't typically do a new cluster for stage (although you certainly can). There's a lot of debate in the k8s community over "should you upgrade existing vs make new". I do it for dev because I would rather upgrade often with fewer checks and have the option to fall back.
Finally we bump prod. This I rarely will make a new cluster. This is a matter of personal choice and there are good arguments for starting fresh often, but I like to maintain the history in etcd and I find with proper planning a rolling upgrade is safe.
This feels like a giant pain in the ass.
I know. Thankfully cloud providers tend to maintain their own versions which buy you a lot more time, which is typically how people are going to be using it. But I know a lot of people like to run their own clusters end to end or just need to for various reasons. It is however a pain to do this all the time.
Is there an LTS version?
So there was a Kubernetes working group set up to discuss this and their conclusion was it didn't make sense to do. I don't agree with this assessment but it has been discussed.
My dream for Kubernetes would be to add a 2 year LTS version and say "at the end of two years there isn't a path to upgrade". I make a new cluster with the LTS version, push new patches as they come out and then at the end of two years know I need to make a new cluster with the new LTS version. Maybe the community comes up with some happy path to upgrade, but logistically it would be easier to plan a new cluster every 2 years vs a somewhat constant pace of pushing out and testing upgrades.
How do I upgrade Kubernetes?
See if you can upgrade safely against API paths. I use Pluto. This will check to see if you are calling deprecated or removed API paths in your configuration or helm charts. Run Pluto against local files with: pluto detect-files -d. You can also check Helm with: pluto detect-helm -owide. Adding all of this to CI is also pretty trivial and something I recommend for people managing many clusters.
2. Check your Helm releases for upgrades. Since typically things like the CNI and other dependencies like CoreDNS are installed with Helm, this is often the fastest way to make sure you are running the latest version (check patch notes to ensure they support the version you are targeting). I use Nova for this.
3. Get a snapshot of etcd. You'll want to make sure you have a copy of the data in your production cluster in the case of a loss of all master nodes. You should be doing this anyway.
3. Start the upgrade process. The steps to do this are outlined here.
If you are using managed Kubernetes
This process is much easier. Follow 1 + 2, set a pod disruption budget to allow for node upgrades and then follow the upgrade steps of your managed provider.
I messed up and waited too long, what do I do?
Don't feel bad, it happens ALL the time. Kubernetes is often set up by a team that is passionate about it, then that team is disbanded and maintenance becomes a secondary concern. Folks who inherit working clusters are (understandably) hesitant to break something that is working.
With k8s you need to go from minor -> minor in order, not jumping releases. So you need to basically (slowly) bump versions as you go. If you don't want to do that, your other option is to make a new cluster and migrate to it. I find for solo operators or small teams the upgrade path is typically easier but more time consuming.
The big things you need to anticipate are as follows:
Ingress. You need to really understand how traffic is coming into the cluster and through what systems.
Service mesh. Are you using one, what does it do and what version is it set at? Istio can be a BEAR to upgrade, so if you can switch to Linkerd you'll likely be much happier in the long term. However understanding what controls access to what namespaces and pods is critical to a happy upgrade.
CSI drivers. Do you have them, do they need to be upgraded, what are they doing?
CNI. Which one are you using, is it still supported, what is involved in upgrading it.
Certificates. By default they expire after a year. You get fresh ones with every upgrade, but you can also trigger a manual refresh whenever with kubeadm certs renew. If you are running an old cluster PLEASE check the expiration dates of your client certificates with: kubeadm certs check-expiration now.
Do you have stateful deployments? Are they storing something, where are they storing it and how do you manage them? This would be databases, redis, message queues, applications that hold state. These are often the hardest to move or interact with during an upgrade. You can review the options for moving those here. The biggest thing is to set the pod disruption budget so that there is some minimum available during the upgrade process as shown here.
Are you upgrading etcd? Etcd supports restoring from snapshots that are taken from an etcd process of the major.minor version, so be aware if you are going to be jumping more than a patch. Restoring might not be an option.
Otherwise follow the steps above along with the official guide and you should be ok. The good news is once you bite the bullet and do it once up to a current version, maintenance is easier. The bad news is the initial EOL -> Supported path is soul-sucking and incredibly nerve-racking. I'm sorry.
I'm running a version older than 1.21 (January 2023)
So you need to do all the steps shown above to check that you can upgrade, but my guiding rule is if the version is more than 2 EOL versions ago, it's often easier to make a new cluster. You CAN still upgrade, but typically this means nodes have been running for a long time and are likely due for OS upgrades anyway. You'll likely have a more positive experience standing up a new cluster and slowly migrating over.
You'll start with fresh certificates, helm charts, node OS versions and everything else. Switching over at the load balancer level shouldn't be too bad and it can be a good opportunity to review permissions and access controls to ensure you are following the best procedures.
I hate that advice
I know. It's not my favorite thing to tell people. I'm sorry. I don't make the rules.
Note on Node OS choices
A common trend I will see in organizations is to select whatever Linux distro they use for VMs as their Node OS. Debian, Ubuntu, Rocky, etc. I don't recommend this. You shouldn't think of Nodes as VMs that you SSH into on a regular basis and do things in. They're just platforms to run k8s on. I've had a lot of success with Flatcar Linux here. Upgrading the nodes is as easy as rebooting, you can easily define things like SSH with a nice configuration system shown here.
With Node OS I would much rather get security updates more quickly and know that I have to reboot the node on a regular basis as opposed to keeping track of traditional package upgrades and the EOL for different linux distros, then track whether reboots are required. Often folks will combine Flatcar Linux with Rancher Kubernetes Engine for a super simple and reliable k8s standup process. You can see more about that here. This is a GREAT option if you are making a new cluster and want to make your life as easy as possible in the future. Check out those docs here.
If you are going to use a traditional OS, check out kured. This allows you to monitor the "reboot-required" at /var/run/reboot-required and schedule automatic cordon, draining, uncordon of the node. It also ensures only one node is touched at a time. This is something almost everyone forgets to do with kubernetes, which is maintain the Node.
Conclusion
I hope this was helpful. The process of keeping Kubernetes upgraded is less terrible the more often you do it, but the key things are to try and get as much time in your environment baking each minor release. If you stay on a regular schedule, the process of upgrading clusters is pretty painless and idiot-proof as long as you do some checking.
If you are reading this and think "I really want to run my own cluster but this seems like a giant nightmare" I strongly recommend checking out Rancher Kubernetes Engine with Flatcar Linux. It's tooling designed to be idiot-proof and can be easily run by a single operator or a pair. If you want to stick with kubeadm it is doable, but requires more work.
With the recent exodus from Twitter due to Elon being a deranged sociopath, many folks have found themselves moving over to Mastodon. I won't go into Mastodon except to say I've moved over there as well (@[email protected]) and have really enjoyed myself. It's a super nice community and I have a lot of hope for the ActivityPub model.
However when I got on Mastodon I found a lot of abandoned bot accounts. These accounts, for folks who don't know, tend to do things like scrape RSS feeds and pump that information into Twitter so you can have everything in one pane of glass. Finding a derelict Ars Technica bot, I figured why not take this opportunity to make a bot of my own. While this would be very easy to do with SQLite, I wanted it to be an AWS Lambda so it wouldn't rely on some raspberry pi being functional (or me remembering that it was running on some instance and then accidentally terminating it because I love to delete servers).
Criteria for the project
Pretty idiot-proof
Runs entirely within the free tier of AWS
Set and forget
Step 1 - DynamoDB
I've never used dynamoDB before, so I figured this could be a fun challenge. I'm still not entirely sure I used it correctly. To be honest I ran into more problems than I was expecting given its reputation as an idiot-proof database.
Some things to keep in mind. Because of how DynamoDB stores numbers, the type of the number is Decimal, not int or float. This can cause some strange errors when attempting to store and retrieve ID values. You can read the conversation about it here. I ended up storing the ID as a string which is probably not optimal performance but did make the error go away.
When using DynamoDB, it is vital to not use scan. Query is what I ended up using for all my requests, since then I get to make lookups on my secondary tables with the key. The difference in speed during load testing when I generated a lot of fake URLs was pretty dramatic, 100s of milliseconds vs 10s of seconds.
Now that I've spent some time playing around with DynamoDB, I do see the appeal. It is a surprisingly generous free tier. I've allocated 5 provisioned Read and Write units but honestly we need a tiny fraction of that.
NOTE: This is not production-grade python. This is hobby-level python. Were this a work project I would have changed some things about its design. Before you ping me about collision, I calculate that with that big a range of random IDs to pull from it would take ~6 thousands of years of work in order to have a 1% probability of at least one collision. So please, for the love of all things holy, don't ping me. Wanna use UUIDs? Go for it.
For those who haven't deployed to AWS Lambda before, it's pretty easy.
Make sure you have Python 3.9 installed (since AWS doesn't support 3.10)
Copy that snippet to a directory and call it lambda_function.py
Change the rss_feed = to be whatever feed you want to make a bot of.
run python3.9 -m venv venv
run source venv/bin/activate
Then you need to install the dependencies: - pip install --target ./package feedparser - pip install --target ./package Mastodon.py - pip install --target ./package python-dotenv
You'll want to cd into the package directory and then run zip -r ../my-deployment-package.zip . to bundle the dependencies together.
Finally take the actual python file you want to run and copy it into the zip directory. zip my-deployment-package.zip lambda_function.py
You can also use serverless or AWS SAM to do this all but I find the ZIP file is pretty idiot-proof. Then you just upload it through the AWS web interface, but hold off on doing that. Now that we have the Python environment setup we can generate the credentials.
Step 3 - Mastodon Credentials
Now we're back in the python virtual environment we made before in the directory.
Run source venv/bin/activate
Start the Python 3.9 REPL
Run from mastodon import Mastodon
Run: Mastodon.create_app('your-app-name', scopes=['read', 'write'], api_base_url="https://c.im") (note I'm using c.im but you can use any server you normally use)
You'll get back three values by the end. CLIENT_ID, CLIENT_SECRET from when you registered the bot with the server and then finally an ACCESS_TOKEN after you make an account for the bot and pass the email/password.
6. Copy these values to a .env file in the same directory as the lambda_function.py file from before.
Watch as your Lambda triggers on a regular interval.
Step 5 - Cleanup
Inside of the Mastodon bot account there are a few things you'll want to check. First you want to make sure that the following two options are selected under "Profile"
Imagine my surprise when writing a simple Python script on my Mac, I suddenly got SSL errors on every urllib request over HTTPS. I checked the site certificate, looked good. I even confirmed on the Apple help documentation that they included the CAs for this certificate (in this case the Amazon certificates). I was really baffled on what to do until I stumbled across this.
\f0\b0 \ulnone \
This package includes its own private copy of OpenSSL 1.1.1. The trust certificates in system and user keychains managed by the
\f2\i Keychain Access
\f0\i0 application and the
\f2\i security
\f0\i0 command line utility are not used as defaults by the Python
\f3 ssl
\f0 module. A sample command script is included in
\f3 /Applications/Python 3.11
\f0 to install a curated bundle of default root certificates from the third-party
\f3 certifi
\f0 package ({\field{\*\fldinst{HYPERLINK "https://pypi.org/project/certifi/"}}{\fldrslt https://pypi.org/project/certifi/}}). Double-click on
\f3 Install Certificates
\f0 to run it.\
Apparently starting in Python 3.6, Python stopped relying on the Apple OpenSSL and started bundling their own without certificates. The way this manifests is:
This will install the certifi package, which has all the Mozilla certificates. This solved the problem and hopefully will help you in the future. Really weird choice by the Mac Python team here since it basically breaks Python.
Podman Desktop is here and it works great. When Docker changed their license to the following, it was widely understood that its time as the default local developer tool was coming to an end.
Docker Desktop remains free for small businesses (fewer than 250 employees AND less than $10 million in annual revenue), personal use, education, and non-commercial open source projects.
Hope you never get acquired I guess
Podman, already in many respects the superior product, didn't initially have a one to one replacement for Docker Desktop, the commonly used local development engine. However now it does and it works amazingly well. Works with your existing Dockerfiles, has all the Kubernetes functionality and even allows you to use multiple container engines (like Docker) at the same time.
I'm shocked how good it is for a not 1.0 release, but for anyone out there installing Docker Desktop at work, stop and use this instead. Download it here.
With the release of iOS 16 and MacOS Ventura, we are now in the age of passkeys. This is happening through WebAuthn, a specification written by the W3C and FIDO with the involvement of all of the major vendors such as Google, Mozilla, etc. The basic premise is familiar to anyone who has used SSH in their career: you login through the distribution of public keys, keeping the private key on the device.
Like all security initiatives, someone took the problem of "users sometimes reuse passwords" and decided the correct solution is to involve biometric security when I log into my coffee shop website to put my order in. I disagree with the basic premise of the standard on a personal level. I think it probably would have been fine to implement an API where the service simply requested a random password and then stored it in the existing browser password sync. It would have solved the first problem of password reuse, allowed for export and didn't require a total change in how all authentication works. However I am not the kind of person who writes these whitepapers full of math so I defer to the experts.
How WebAuthn works is the server receives from the user a public key and randomly generated ID. This private key is distributed and stored in the client vendor sync process, meaning it is available to different devices as long as those devices exist within the same vendor ecosystem. This stuck out to me as a fascinating transition for passwords and one with long-term implications for user retention across the different platforms.
Imagine being Apple or Google and getting to tell users "if you abandon this platform, you are going to lose every login you have". This is a tremendous threat and since all platforms will effectively be able to share it at the same time, not a legal threat. Let's get into the details of what WebAuthn is and how it works, then walk through how this provides tremendous value to platform holders as a way of locking in users.
WebAuthn Properties
WebAuthn is a web-based API that allows web servers, called Relying Parties to communicate with authenticators on a users device. I'll refer to these as RPs from now on. To get started, the wserver creates new credentials by calling navigator.credentials.create() on the client.
challenge: a buffer of random bytes generated by the server to prevent replay attacks.
rp: basically the website, needs to be a subset of the domain currently in the browser.
user: information about the user. Suggested not to use PII data but even if you use name and displayName it doesn't appear that this is ever relayed to the rp source
pubKeyCredParams: what public keys are acceptable to the server
authenticatorSelection: do you want anything to be allowed to be an authenticator or do you want a cross-platform authenticator like only a YubiKey
timeout: self-documenting
attestation: information from the authenticator that could be used to track users.
Attestation
What you are getting back as the service is the attestation statement, which is a somewhat vague concept. It's a signed data object that includes info about the public key and some other pieces of information. You can see the generic object below
This part is kind of interesting. There are actually 4 tiers of "information you get back about the user".
none: You don't want anything and is the default
indirect: the client is allowed how to obtain such a statement. The client may replace an authenticator-generated statement with one generated with an Anonymization CA.
direct: you want the statement
enterprise: you want the statement that may include uniquely identifying information. The authenticator needs to be configured to say "this rp ID is allowed to request this information", so presumably this will be for devices enrolled in some sort of MDM.
You get back an attestationObject at the end of all of this which basically allows you to parse metadata about the registration event as well as the public key, along with the fmt of the attestation which is effectively the type of authenticator you used. Finally you have the statement itself.
When a user wants to sign in, the process works pretty simply. We call navigator.credentials.get() on the client, which basically says go get me the credentials I specify in allowCredentials. You can say what the ID is and how to get the credentials (through usb, bluetooth, nfc, etc).
The key to how this all works is that the private key is synced by the vendor to the different devices (allowing for portability) but also allows for phone delegation. So for instance if you are a Windows Chrome user and want to sign in using passkeys, you can, as long as you still have the Apple device that you originally created the passkey on.
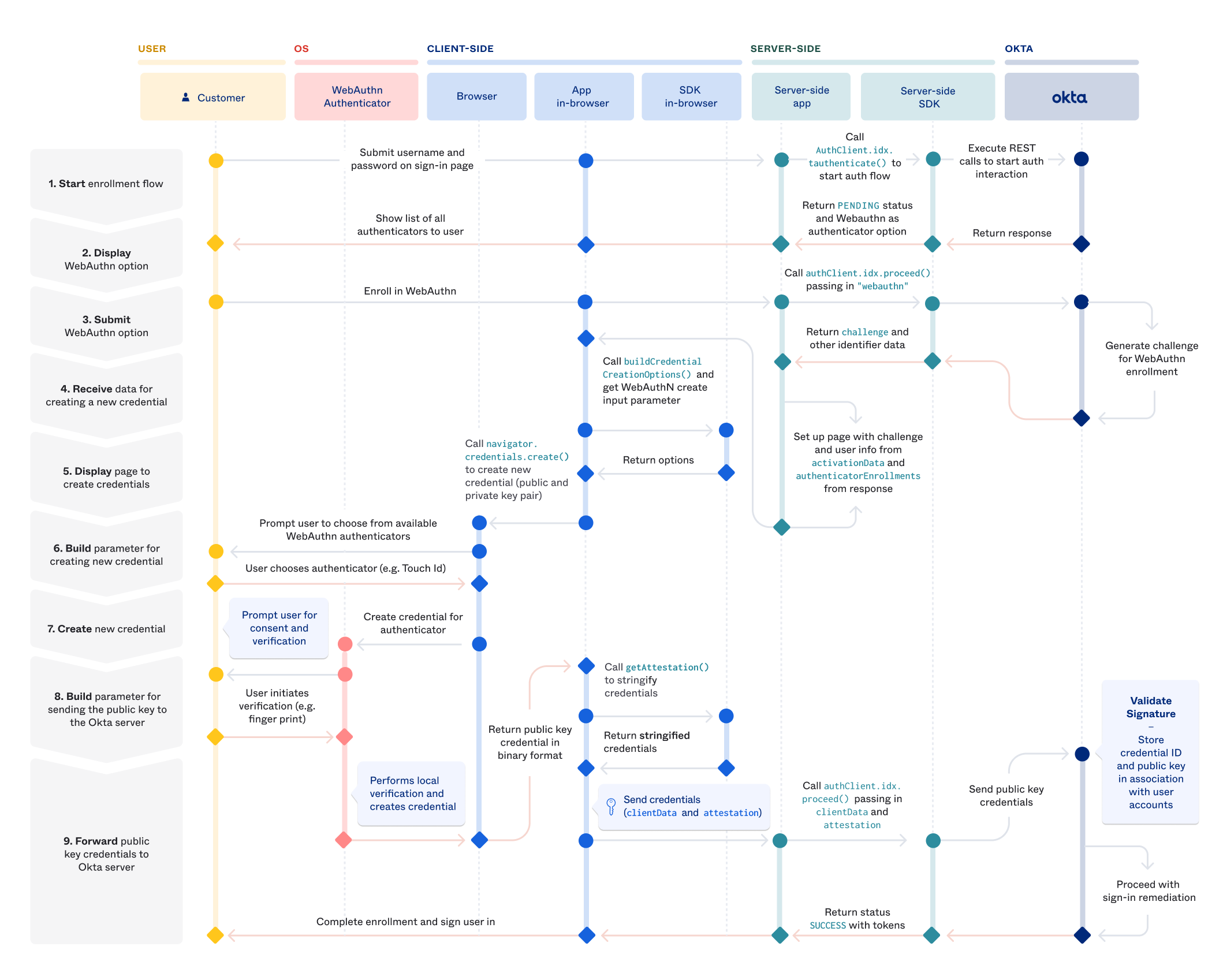
Good diagram if you are using the Okta service, but still valuable either way
Passkey cross-device flow
The vendor supplies a "Passkey from nearby devices" option when the user is logging in
The web site displays a QR code
The device which contains the passkey points its camera and starts an auth flow
The two devices perform a Bluetooth handshake to ensure they are actually near each others and agree on a server to use as an exchange post
The device with the passkey is used to perform the actual auth process.
Now in theory the service should offer some sort of "would you like to make a new passkey on this device".
At no point did you transfer the private key anywhere. That entire sync process is controlled by the vendor, meaning your option for portable authentication is going to be a roaming authentiator (aka a YubiKey).
It's important to note here that a lot of assumptions have been made about developers around the requirement of local storage of private keys. This isn't necessarily the case. Authenticators have the option of not storing their private keys locally at all. You have the option of instead storing the private keys with the rp, encrypted under a symmetric key held by the authenticator. This elasticity to the spec comes up a lot, with many decisions deferred to the vendors.
Why Does This Matter?
WebAuthn has taken a strong "decentralized" design philosophy, which makes sense until you realize that the inability to export private keys isn't....really true. Basically by submitting an attestation, the vendor is saying "these devices private keys cannot be stolen". You can see the initial conversation on GitHub here. It's making the problem someone else's issue.
By saying, in essence, portability of private keys is not a concern of the spec and leaving it entirely in the hands of vendors, we have created one of the greatest opportunities for user lock-in in recent history. It is now on the individual services and the vendors to allow for users to seamlessly sign in using different devices. The degree by which platform owners want to allow these devices to work with each other is entirely within their own control.
We can see that vendors understand this to some extent. Apple has announced that once passkey is supported in the OS, device-bound keys will no longer be supported. You will not have the option of not using iCloud (or Chrome Sync services). Administrators will likely not love the idea of critical keys being synced to devices possibly beyond their control (although the enterprise attestation provides some protection against this). So already in these early days we see a lot of work being done to ensure a good user experience but at the cost of increased vendor buy-in.
Scenario
You are a non-technical user, who used their iPhone in the normal way. When presented with a login you let the default of "use passkeys" ride, without doing anything special. You lose your phone, but don't own any other Apple products. By default iCloud Keychain only works on iOS, iPadOS and macOS. In order to seamlessly log into any service that you registered through your phone with passkeys, you have to purchase another Apple product.
If you attempt to switch to Android, while it supports passkeys, it is between you and the RP on how controlling access to your original account will work. Since allowing users to reset their passkeys through requesting a passkey reset through an email link eliminates a lot of the value of said service, I'm not exactly sure how this is going to be handled. Presumably there will need to be some other out-of-band login.
Also remember that from the RPs side, what you are getting is almost no information about the user. You aren't even (confidently) getting what kind of authenticator. This is great from a GDPR perspective, not having to hold email addresses and names and all sorts of other PII in your database (and does greatly eliminate many of the security concerns around databases). However if I am a web developer who goes "all-in" with this platform, it's hard to see how at some point I'm not going to fall back to "email this user a link to perform some action" and require the email address for account registration.
On the RP side they'll need to: verify this is the right user (hopefully they got some other ID in the registration flow), remove the passphrase and then have the user enroll again. This isn't a terrible flow, but is quite a bit more complicated than the story today of: log in again through SSO or by resetting a password by sending a reset link to email.
What about Chrome?
Chrome supports the standard, but not in a cross-platform way.
Passkeys are synchronized across devices that are part of the same ecosystem. For example, if a user creates a passkey on Android, it is available on all Android devices as long as the user is signed in to the same Google account. However, the same passkey is not available on iOS, macOS or Windows, even if you are using the same browser, like Chrome.
Ultimately it is the hardware you are generating the key on that matters for vendor syncing, not the browser or OS.
The result of this is going to be pretty basic: as years go on, the inertia required to switch platforms will increase as more services are added as passkeys. There exists no way currently that I'm able to find that would allow you to either: add a secondary device to the exchange process or to bulk transfer out of Vendor A and into Vendor B. Instead any user who wants to switch services will need to go through the process of re-enrolling in each services with a new user ID, presumably hoping that email was captured as part of the sign-up flow so that the website or app can tie the two values together.
There is a proposed spec that would allow for dual enrollment, but only from the start. Meaning you would need to have your iOS authenticator, then attach your Chromebook authenticator to it from the start. There is no way to go back through and re-sync all logins with the new device and you would need constant access to both devices to complete the gesture element of the auth.
Yubico has an interesting idea here based on ARKG or Asynchronous Remote Key Generation. The basic idea is that you have a primary authenticator and a secondary authenticator that has no data transfer between the two. The proposed flow looks as follows
Backup device generators a private-public key pair and transfers the public key to the primary authenticator
This is used by the primary authenticator to derive new public keys on behalf of the backup device
Then the primary generates a new pair for each backup device registered and sends this on to the RP along with its primary key.
If the primary disappears, the backup device can request the cred from the RP and use it to derive the key used. In order to retrieve the cred associated with a user, there needs to be some sort of identifier outside of the user ID in the spec which is a random value not surfaced to the user.
ARKG functionality. ARKG allows arbitrary public keys pk′ to
be derived from an original pk, with corresponding sk′ being cal-
culated at a later time—requiring private key sk for the key pair
(sk, pk) and credential cred.
Definition 3.1 (ARKG). The remote key generation and recovery
scheme ARKG B (Setup, KGen, DerivePK, DeriveSK, Check) con-
sists of the following algorithms:
• Setup(1𝜆 ) generates and outputs public parameters pp =
((G, 𝑔, 𝑞), MAC, KDF1, KDF2) of the scheme for the security
parameter 𝜆 ∈ N.
• KGen(pp), on input pp, computes and returns a private-
public key pair (sk, pk).
• DerivePK(pp, pk, aux) probabilistically returns a new public
key pk′ together with the link cred between pk and pk′, for
the inputs pp, pk and auxiliary data aux. The input aux is
always required but may be empty.
• DeriveSK(pp, sk, cred), computes and outputs either the new
private key sk′, corresponding to the public key pk′ using
cred, or ⊥ on error.
• Check(pp, sk′, pk′), on input (sk′, pk′), returns 1 if (sk′, pk′)
forms a valid private-public key pair, where sk′ is the cor-
responding private key to public key pk′, otherwise 0.
Correctness. An ARKG scheme is correct if, ∀𝜆 ∈ N, pp ←
Setup(1𝜆 ), the probability Pr [Check(pp, sk′, pk′) = 1] = 1 if
(sk, pk) ← KGen(pp);
(pk′, cred) ← DerivePK(pp, pk, ·);
sk′ ← DeriveSK(pp, sk, cred).
Look at all those fun characters.
Challenges
The WebAuthn presents a massive leap forward for security. There's no disputing that. Not only does it greatly reduce the amount of personal information flowing around the auth flow, it also breaks the reliance on email address or phone numbers as sources of truth. The back-bone of the protocol is a well-understand handshake process used for years and extremely well-vetted.
However the spec still has a lot of usability challenges that need to be addressed especially as adoption speeds up.
Here are the ones I see in no particular order:
Users and administrators will need to understand and accept that credentials are backed up and synced across unknown devices employing varying levels of biometric security.
Core to the concept of WebAuthn is the idea of unlinkability. That means different keys must be used for every new account at the RP. Transferring or combining accounts is a problem for the RP which will require some planning on the part of service providers.
In order to use this feature, services like iCloud Sync will be turned on and the security of that vendor account is now the primary security of the entire collection of passwords. This is great for consumers, less great for other systems.
There currently exists no concept of delegation. Imagine I need to provide you with some subset of access which I can delegate, grant and revoke permissions, etc. There is an interesting paper on the idea of delegation which you can find here.
Consumers should be aware of the level of platform buy-in they're committing to. Users acclimated to Chromebooks and Chrome on Windows being mostly interchangeable should be made aware that this login is now tied to a class of hardware.
We need some sort of "vendor exchange" process. This will be a challenge since part of the spec is that you are including information about the authenticator (if the RP asks for it). So there's no reason to think a service which generated an account for you based on one type of authenticator will accept another one. Presumably since the default is no information on this, a sync would mostly work across different vendors.
The vendor sync needs to extend outside of OEMs. If I use iCloud passkeys for years and then enroll in 1Password, there's no reason why I shouldn't be able to move everything to that platform. I understand not allowing them to be exposed to users (although I have some platform ownership questions there like 'isn't it my passkey'), but some sort of certified exchange is a requirement and one that should have been taken care of before the standard was launched.
Conclusion
This is a giant leap forward in security for average users. It is also, as currently implemented, one of the most effective platform lock-ins I've ever seen. Forget the "green text" vs "blue text", as years go on and users rely more and more on passkeys for logins (which they should), switching platforms entirely will go from "a few days of work" to potentially needing to reach out and attempt to undo every single one of these logins and re-enroll. For folks who keep their original devices or a device in the ecosystem, this is mostly time consuming.
For users who don't, which will be a non-trivial percentage (why would a non-technical user keep their iphone around and not sell it if they have a brand new android), this is going to be an immense time commitment. This all assumes a high degree of usage of this standard, but I have trouble imagining web developers won't want to use this. It is simple a better more secure system that shifts a lot of the security burden off of them.
It always starts the same way. A demo is shown where a previously complex problem set is reduced down to running one Magic Tool. It is often endorsed by one of the Big Tech Companies or maintained by them. Some members of the organization start calling for the immediate adoption of this technology. Overnight this new tool becomes a shorthand for "solution to all of our problems".
By the time it gets to the C-level, this tool is surrounded by tons of free press. You'll see articles like "X technology is deprecated, it's time to get onboard with Magic Tool". Those of you new to working in tech probably assume some due-diligence was done to see if the Magic Tool was good or secure or actually a good fit for that particular business. You would be incorrect.
Soon an internal initiative is launched. Some executive decides to make it an important project and teams are being told they have to adopt the Magic Tool. This is typically where the cracks first start to show up, when teams who are relatively apathetic towards the Magic Tool start to use them. "This doesn't do all the things our current stuff does and accounting for the edge cases is a lot more difficult than we were told".
Sometimes the team attempting to roll out this new tech can solve for the edge cases. As time drags on though, the new Magic Tool starts to look as complicated and full of sharp edges as their current tooling. At the end of all this work and discussion, organizations are lucky to see a 2-5% gain in productivity and nothing like the quantum leap forward implied by the advocates for Magic Tool.
Why is this such a common pattern?
We are obsessed with the idea that writing software shouldn't be this hard. None of us really know what we're doing when we start. Your credentials for this job are you learned, at school or at home, how to make small things by yourself. Birdhouses of Java, maybe a few potato clocks of Python. Then you pass a series of interviews where people ask you random, mostly unrelated questions to your job. "How would you make a birdhouse that holds 100,000 birds?" Finally you start working and are asked to construct a fighter jet with 800 other people. The documentation you get when you start describes how to make an F-150 pickup.
So when we see a tutorial or demo which seems to just do the right thing all the time, it lights a fire in people. Yes, that's how this was always supposed to be. The issue wasn't me or my coworkers, the problem was our technology was wrong. The clouds part, the stars align, everything makes sense again. However almost always that's wrong. Large technology changes that touch many teams and systems are never going to be easy and they're never going to just work. The technology might still be superior to be clear, but easy is a different beast.
I'll present 3 examples of good technologies whose user experience for long-term users is worse because of a desire to keep on-boarding as simple as possible. Where the enthusiasm for adoption ultimately hurts the daily usage of these tools. Docker, Kubernetes and Node. All technologies wildly loved in the community whose features are compelling but who hide the true complexity of adoption behind fast and simple tutorials.
To be clear I'm not blaming the maintainers of this software. What I'm trying to suggest is we need to do a better job of frontloading complexity, letting people know the scope and depth of a thing before we attempt to sell it to the industry at large. Often we get into these hype bubbles where this technology is presented as "inevitable", only to have intense disappointment when the reality sinks in.
Your app shouldn't be root inside of a container
Nowhere I think is this more clear than how we have fundamentally failed the container community in fundamental security. Job after job, meetup after meetup, I encounter folks who are simply unaware that the default model for how we build containers is the wrong way to do it. Applications in containers should not be root by default.
But what does root in a container even mean? It's actually not as simple as it sounds. A lot of work has happened behind the scenes to preserve the simple user experience and hide this complexity from you. Let's talk about how Docker went at this problem and how Podman attempts to fix it.
However you need to internalize this. If you are running a stock configured container with a root user and someone escapes that container, you are in serious trouble. Kubernetes or no Kubernetes.
In the off-chance you aren't familiar with how containers work.
Docker
When Docker launched and started to become popular, a lot of eyebrows were raised at it running as root on the host. The explanation made sense though for two reasons: mounting directories without restriction inside of the container and for binding to ports below 1024 on Linux. For those that don't know, any port at or below 1024 on Linux is a privileged port. Running the daemon as root is no longer a requirement of Docker but there are still the same restrictions in terms of port and directory mounting along with host networking and a bevy of other features.
This caused a lot of debate. It seemed crazy to effectively eliminate the security of Linux users for the sake of ease of deployment and testing, but community pressure forced the issue through. We were told this didn't really matter because "root in containers wasn't really root". It didn't make a ton of sense at first but we all went with it. Hello to kernel namespaces.
Namespaces in Linux are, confusingly, nothing like namespaces in Kubernetes. They're an isolation feature, meaning one service running in one namespace cannot see or access a process running in another namespace. There are user namespaces allowing users to have root in a namespace without that power transferring over. Process ID namespaces, meaning there can be multiple PID 1s running isolated from one another. Network namespace with a networking stack, mount namespace which allows for mounting and unmounting without changing the host, IPC namespaces for distinct and isolated POSIX message queues and finally UTS namespaces for different host and domain names.
The sales pitch makes sense. You can have multiple roots, running a ton of processes that are isolated from each other in distinct networking stacks that change mounts and send messages inside of a namespace without impacting other namespaces. The amount of resources and the priority of those resources are controlled by cgroups, which is how cpu and memory limits work for containers.
Sound great. What's the issue?
Namespaces and cgroups are not perfect security and certainly not something you can bet the farm on without a lot of additional context. For instance, running a container with --privileged eliminates the namespace value. This is common in CI/CD stacks when you need to run Docker in Docker. Docker also doesn't use all the namespace options, most importantly supporting but not mandating user namespaces to remap root to another user on the host.
To be fair they're gone to great lengths to try and keep the Docker container experience as simple as possible while attempting to improve security. By default Docker drops some Linux capabilities and you can expand that list as needed. Here is a list of all of the Linux capabilities. Finally, here are the ones that Docker uses. You can see here a security team trying desperately to get ahead of the problem and doing a good job.
The problem is that none of this was communicated to people during the adoption process. It's not really mentioned during tutorials, not emphasized during demos and requires an understanding of Linux to really go at this problem space. If Docker had frontloaded this requirement into the tooling, pushing you to do the right thing from the beginning, we'd have an overall much more secure space. That would have included the following:
Warning users a lot when they run the --privileged flag
By default creating a new user or userspace with containers that isn't root and creating one common directory for that user to write to.
Having --cap-drop=all be the default and having users add each cap they needed.
Running --security-opt=no-new-privileges as default
Helping people to write AppArmor or some security tooling as shown here.
Turning User Namespaces on by default if you are root. This allows a container root user to be mapped to a non uid-0 user outside the container and reduces the value of escaping the container.
Instead we've all adopted containers as a fundamental building block of our technologies and mostly did it wrong. Podman solves a lot of these problems btw and should be what you use from now on. By starting fresh they skipped a lot of the issues with Docker and have a much more sustainable and well-designed approach to containers and security in general. Hats off to that team.
How do I tell if my containers are correctly made?
Docker made a great tool to help with this which you can find here. Called Docker Bench for Security, it allows you to scan containers, see if they're made securely and suggests recommendations. I'm a big fan and have learned a lot about the correct ways to use Docker from using it.
Jeff aged 25 after attempting to brute-force Kubernetes adoption
Kubernetes
I was introduced to Kubernetes years ago as "the system Google uses". Now this turns out not to actually be true, the internal Google system branched off from the design of K8s a long time ago, but it still represented a giant leap forward in terms of application design. Overnight organizations started to adopt it aggressively, often not truly understanding what it was or the problem it tried to solve. Like all tools, Kubernetes is good at some problem areas and terrible at others.
I personally love k8s and enjoy working with it. But many of the early pitches promised things that, in retrospect, were insane. K8s is neither easy to understand or easy to implement, with many sharp edges and corner cases which you run into with surprising frequency. Minikube demos are not a realistic representation of what the final product looks like.
Here's the truth: k8s is a bad choice for most businesses.
The demos for Kubernetes certainly look amazing, right? You take your containers, you shove them into the cloud, it does the right thing, traffic goes to the correct place, it's all magical. Things scale up, they scale down, you aren't locked into one specific vendor or solution. There's an API for everything so you can manage every element from one single control plane. When you first start using k8s it seems magical, this overlay on top of your cloud provider that just takes care of things.
I like how routers, storage and LBs are just "other"
The Reality
The reality is people should have been a lot more clear when introducing k8s as to what problems it is trying to solve and which ones it isn't. K8s is designed for applications that are totally ephemeral, they don't rely on local storage, they receive requests, process them and can be terminated with very little thought. While there might (now) be options for storage, they're a bad idea to use generally due to how storage works with different AZs in cloud providers. You can do things like batch jobs and guaranteed runs inside of k8s, but that's a different design pattern from the typical application.
K8s is also not bulletproof. You'll often run into issues with DNS resolution at scale since the internal networking is highly dependent on it. It comes by default wide open, allowing you to make namespaces that do not isolate network traffic (common mistake I hear all the time). Implementing a service mesh is mandatory as is some sort of tracing solution as you attempt to find what route is causing problems. Control plane problems are rare but catastrophic when they happen. Securing API endpoints and traffic in general requires diligence.
You also need to do a ton of research before you even start k8s. What CNI is best for you, how is external DNS going to work, how are you going to load balance traffic, where is SSL termination happening, how are you going to upgrade the nodes actually running these containers, monitoring and graphs and alerting and logs all need to be mapped out and planned. Are your containers secure? Do you understand your application dependencies between apps?
In order to run k8s at scale across a few hundred developers, a few people in your org need to become extremely familiar with how it works. They will be the technical troubleshooting resource as application teams attempt to work backwards to the problem space. These people will need to be available for questions all the time. Remember you are taking:
A entire cloud environment with IAM, VPCs, security policies, Linux servers, buckets, message queues, everything else
Adding effectively an entirely new environment on top of that. These two systems still interact and can cause problems for each other, but they have very little visibility from one into the other. This can cause infuriatingly hard to diagnose problems.
So in order to do this correctly, you need people who understand both problem spaces and can assist with sorting where each step is happening.
So when should I use kubernetes?
You are spending a ton of money on containers that are being underused or adding additional capacity to try and keep uptime during failures. K8s is really amazing at resource management and handling node or pod failure.
You are deeply committed to microservices. K8s meshes well with typical microservices, allowing you to bake in monitoring and tracing along with clear relationships between microservices through service meshes.
Multicloud is a requirement. Be super careful about making this a requirement. It's often a giant mistake.
Vendor lock-in is a serious concern. Only applicable if you are a Fortune 500. Otherwise don't waste brain cycles on this.
Uptime is critical above all. The complexity pays off in uptime.
You are trying to find a bridge technology between your datacenter and the cloud
Otherwise use literally one of a million other options. Starting a new company? Use Lightsail. Too big for Lightsail? Try ECS. You can grow to an extremely large size on these much simpler technologies. If you have maxed out Lightsail, good news, you are now big enough to hire a team. If you decide to go to k8s understand and map out exactly what you want from it. Don't assume turning it on and pushing out some yaml is good enough.
Planning for k8s correctly
The best guide I've seen and one I've used a few times is the NSA k8s hardening guide. It walks through all the common issues and concerns with using k8s at scale, offering good common-sense recommendations at each step. If you are an organization considering using k8s or currently using it and are unsure whether you have it correctly set up, walking through this guide and discussing the points it brings up should at least allow you to approach the project with the correct mindset.
Node.js
Node by itself I have no issues with. I have no particular dog in that race of "should we be writing the backend and frontend in the same language". No, my issue with Node is really with NPM. After working with teams relying on NPM extensively to provide both private, internal packages and to build applications using external third-party dependencies, I'm convinced it is unsafe at any speed.
NPM: Easy over Safe
For a long time application development has followed a pretty stable path in terms of dependencies. You try to write as much as possible with the standard library of your given programming language, only pulling in third-party dependencies when it saved a tremendous amount of time or when they were taking care of something normal people shouldn't be getting involved in (like hashing passwords or creating database connections).
Typically you moved these dependencies into your project for the rest of the projects life, so during a code review process there was often a debate over "does it make sense to import x lines of code forever" in order to save time or add this new functionality. Often the debate hinged on maintenance burdens, where writing functionality using only the standard library made it relatively easy to upgrade between versions.
However dependencies, especially complicated or big dependencies, introduce a lot of possible long term issues. They themselves often have dependencies, or take advantage of more esoteric aspects of a language in order to solve for problems that your project often doesn't have (since the library has a wider use case than just you).
Here's an example. I was working on a PHP application with someone else and I needed to do some junk with S3. I (of course) added the official AWS SDK for PHP, thinking this was the correct way to do things. A more experienced developer stopped me, pointing out correctly that I was adding a ton of new code to the repo forever and maybe there was a better way to do this.
As it turns out this was relatively easy to do without loading the entire SDK into our codebase forever and introducing a lot of new dependencies. However this back and forth consumes time and often requires folks to becomes much more familiar with the services their applications consume. Client libraries for SaaS often hide this complexity behind very simple methods that allow you to quickly drop in an API key and keep going.
Rise of Node
Node emerged onto the scene with a very different promise as compared to most server-side languages. What if, instead of front and backend teams working on different applications forever waiting for new API endpoints to get added, they were maintained by the same group. Driven by these potential cost and effort savings, Node was introduce to the world and has (mostly) lived up to this core promise.
I remain impressed by the concurrency model for Node, which I feel I need to say in order to stop people from accusing me of attacking the platform simply because it is Javascript. I've worked with teams that have exclusively lived inside of Node for years, many of them have extremely positive things to say. There is certainly a part of me that is jealous of their ability to become deep experts on Javascript and using that skillset across a wide variety of tooling.
The real advantage of Node though was the speed by which teams could build complex functionality even with limited backend knowledge. The low barrier to entry to NPM meant anyone was able to very quickly take some classes and make them available to the entire internet. At first this seemed fine, with developers enjoying how easy it was to have reproducible builds across different workspaces and machines with NPM.
As time went on these endless lists of dependencies started to introduce real maintenance burdens well in excess of their value. By emphasizing speed over safety NPM (and by extension Node) has now become dangerous to recommend for anyone to use in handling customer data in virtually any capacity.
NPM Problems
My first large Node application, I was shocked when I measured the count of third-party code to code in the actual application. We had almost a million lines of external code to our several thousand lines of application code. Graphing out these dependencies was like attempting to catch a money-laundering operation. Unlike, say, the PHP applications I had worked on in the past, it was impossible to even begin to vet this many external vendors. Since they're all required, we were open to security issues from any of them.
Let's walk through how I attempted to fix the problem.
Obviously started with the basics like npm audit, which works but is a purely reactionary element. It relies on developers maintaining the package, reporting the issue, someone initially reporting the issue. In a Python world where I am using maybe 6 big common dependencies, that makes sense. However in NPM land when I have thousands, many of which are maintained by one person, this isn't practical
Fine, can we vet each package before we add it? Even assuming I had the technical ability to assess each package against some sort of "known-good" parameter, the scale of the task would require a thousand people working full-time. Look at the dependency graph for just NPM itself which, remember, is often called by the root user in many tutorials.
Alright well that's an impossible task. Maybe we can at least mitigate the problem by sticking with packages that are scoped. At least then we know its from the right org and isn't the result of a typo. Turns almost almost none of the most-downloaded packages from NPM are scoped. React, lodash, express, the list goes on and on. You can see the top NPM packages here.
Fine, is there a way I can tell if the NPM package at least requires 2FA to upload the thing? As far as I can tell, you cannot. Package maintainers can enforce 2FA, but I can't check to see if its there.
Now NPM has actually taken some great steps here to ensure the package hasn't been tampered with through ECDSA which you can see here for an example: https://registry.npmjs.org/underscore/1.13.6 under the "signatures": [{ "keyid": "SHA256:{{SHA256_PUBLIC_KEY}}", "sig": "a312b9c3cb4a1b693e8ebac5ee1ca9cc01f2661c14391917dcb111517f72370809..." section.
But I still have the same underlying issue. While I can verify that the person publishing the package signed it (which is great), I'm still importing thousands of them. Plus signing the package isn't required so while many of the big packages have it, many don't.
In Practice
What this means is Node apps start to "rot" at an extremely aggressive rate. While they're fast to write and get stood up, they require constant monitoring against security issues with dependency trees spanning thousands of packages. You also constantly run into nested dependency version conflicts (which NPM handles through nesting). In order to keep a Node application patched you need to be willing to override some package dependencies to get a secure version (however you don't know if the actual higher-level dependency will function with the new version or not).
Example of a common pattern in Node application dependencies
You are installing the same thing over and over with slightly different versions. You need to constantly monitor the entire dependency graph and check for declared issues, then hope against hope that everyone is checking everything for you on the internet and reporting like they should. Finally you need to hope that none of these maintainers get their stuff hijacked or simply give up.
Sustainable model of Node
I'm not sure what can be done now to fix this problem. I suspect a great option might be to force packages to "flatten" the dependency space, only allowing for top-level dependencies and not allowing for nested dependencies. However at this point the train has likely left the station.
If you are looking to write safe, long-term Node code, I think your only option is to be extremely aggressive about not allowing packages into your codebase and trying to use the Node Core Modules as outlined here as much as possible. I want to praise the NPM team for switching to a more sustainable signing system and hope it gains widespread adoption (which it seems on track to). Otherwise you basically need to hope and pray that nobody in the thousands of people you rely on decides to blow up your app today.
However in the desire to demonstrate how fast it is to start writing Node by using NPM, we have doomed Node by ensuring that long-term maintenance is nearly impossible. If you fix packages with known-security issues manually and tests starting failing, it can be a massive task to untangle the ball of yarn and figure out what specifically changed.
Conclusion
All of these technologies mostly deliver real, measurable value. They are often advancements over what came before. However organizations were often misled by tutorials and demos that didn't accurately portray the realities of running this technology, instead attempting to encourage adoption by presenting the most positive light possible. I don't blame enthusiasts for this, but I think as a field we should be more honest when showing new technology to peers.
As for the maintainers of these technologies, it ultimately hurts you and your reputation when you don't frontload the complexity into either the tooling or the documentation. I'm going to hit those sharp edges eventually, so why not prepare me for it from the beginning? If at some point I'm going to need to rewrite all of my containers, why not help me do it correctly from the start? If you know I'm going to need to constantly patch my NPM dependencies, maybe add a more robust chain of dependencies so I can audit what is coming in and from where.
Ultimately we help each other by being more honest. I want you to use my tool and get the maximum value out of it, even if the maximum value for you is not to use my tool.
I adore classic arcade machines. They're interested to look at, fun to play and designed for a different era of hardware and software design. While I've certainly spent some time poking around some of the FPGA code for classic arcade cores, I'm still pretty novice when it comes to the low level technical specifications for these machines. The brand that I have the most fond memories of is the old Capcom machines.
Fabian Sanglard has written just this amazing book on the internals of those early Capcom classics like Street Fighter 2. Going into extreme detail on the legendary CPS-1 board, you get more information than I've ever seen before on how it worked, how arcades at the time overall worked and every gritty detail in-between. It's a joy to read with amazing art and diagrams.
Come on, you are curious about how this all works.
The book is available for a pay what you want at his website. His system for generating the book is also pretty clever with the source code available here.
There's also a great post about the PS2. Both were a lot of fun to read. It's always a blast to learn more about these machines that I spent hundreds of hours with as a kid. Link to Playstation 2 Architecture
I've never worked at Google, but I've been impressed with a lot of the data manipulation and storage tools inside of GCP like BigQuery and Cloud Spanner. If you ever worked at Google, this might be a great way to find a replacement for an internal tool you loved. For the rest of us, it's a fascinating look at the internal technology stack of Google.