
A cautionary tale of K8s CRDs and Linkerd.
A few months ago I had the genius idea of transitioning our production load balancer stack from Ingress to Gateway API in k8s. For those unaware, Ingress is the classic way of writing a configuration to tell a load balancer what routes should hit what services, effectively how do you expose services to the Internet. Gateway API is the re-imagined process for doing this where the problem domain is scoped, allowing teams more granular control over their specific services routes.
Ingress
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb
spec:
controller: example.com/ingress-controller
parameters:
apiGroup: k8s.example.com
kind: IngressParameters
name: external-lbThis is what setting up a load balancer in Ingress looks like
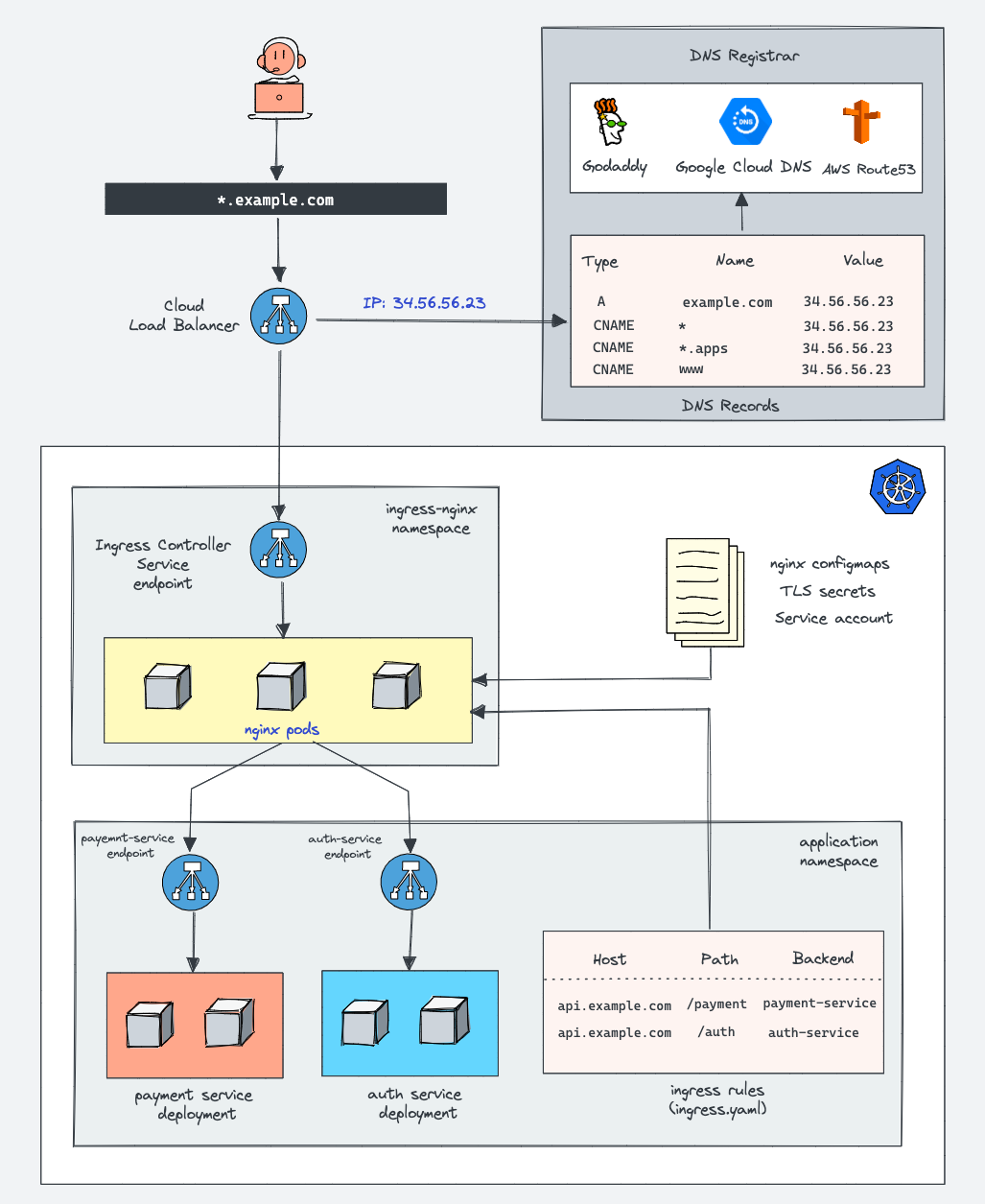
After conversations with various folks at GCP it became clear to me that while Ingress wasn't deprecated or slated to be removed, Gateway API is where all the new development and features are moving to. I decided that we were a good candidate for the migration since we are a microservice based backend with lower and higher priority hostnames, meaning we could safely test the feature without cutting over all of our traffic at the same time.
I had this idea that we would turn on both Ingress and Gateway API and then cut between the two different IP addresses at the Cloudflare level. From my low-traffic testing this approach seemed to work ok, with me being able to switch between the two and then letting Gateway API bake for a week or two to shake out any problems. Then I decided to move to prod. Due to my lack of issues in the lower environments I decided that I wouldn't set up Cloudflare load balancing between the two and manage the cut-over in Terraform. This turned out to be a giant mistake.
The long and short of it is that the combination of Gateway API and Linkerd in GKE fell down under high volume of requests. Low request volume there were no problems, but once we got to around 2k requests a second the Linkerd-proxy sidecar container memory usage started to grow unbounded. When I attempted to cut back from Gateway API to Ingress, I encountered a GKE bug I hadn't seen before in the lower environments.
"Translation failed: invalid ingress spec: service "my_namespace/my_service" is type "ClusterIP", expected "NodePort" or "LoadBalancer";
What we were seeing was a mismatch between the annotations automatically added by GKE.
Ingress adds these annotations:
cloud.google.com/neg: '{"ingress":true}'
cloud.google.com/neg-status: '{"network_endpoint_groups":{"80":"k8s1pokfef..."},"zones":["us-central1-a","us-central1-b","us-central1-f"]}'
Gateway adds these annotations:
cloud.google.com/neg: '{"exposed_ports":{"80":{}}}'
cloud.google.com/neg-status: '{"network_endpoint_groups":{"80":"k8s1-oijfoijsdoifj-..."},"zones":["us-central1-a","us-central1-b","us-central1-f"]}'
Gateway doesn't understand the Ingress annotations and vice-versa. This obviously caused a massive problem and blew up in my face. I had thought I had tested this exact failure case, but clearly prod surfaced a different behavior than I had seen in lower environments. Effectively no traffic was getting to pods while I tried to figure out what had broken.
I ended up making to manually modify the annotations to get things working and had a pretty embarrassing blow-up in my face after what I had thought was careful testing (but was clearly wrong).
Fast Forward Two Months
I have learned from my mistake regarding the Gateway API and Ingress and was functioning totally fine on Gateway API when I decided to attempt to solve the Linkerd issue. The issue I was seeing with Linkerd was high-volume services were seeing their proxies consume unlimited memory, steadily growing over time but only while on Gateway API. I was installing Linkerd with their Helm libraries, which have 2 components, the Linkerd CRD chart here: https://artifacthub.io/packages/helm/linkerd2/linkerd-crds and the Linkerd control plane: https://artifacthub.io/packages/helm/linkerd2/linkerd-control-plane
Since debug logs and upgrades hadn't gotten me any closer to a solution as to why the proxies were consuming unlimited memory until they eventually were OOMkilled, I decided to start fresh. I removed the Linkerd injection from all deployments and removed the helm charts. Since this was a non-prod environment, I figured at least this way I could start fresh with debug logs and maybe come up with some justification for what was happening.
Except the second I uninstalled the charts, my graphs started to freak out. I couldn't understand what was happening, how did removing Linkerd break something? Did I have some policy set to require Linkerd? Why was my traffic levels quickly approaching zero in the non-prod environment?
Then a coworker said "oh it looks like all the routes are gone from the load balancer". I honestly hadn't even thought to look there, assuming the problem was some misaligned Linkerd policy where our deployments required encryption to communicate or some mistake on my part in the removal of the helm charts. But they were right, the load balancers didn't have any routes. kubectl confirmed, no HTTProutes remained.
So of course I was left wondering "what just happened".
Gateway API
So a quick crash course in "what is gateway API". At a high level, as discussed before, it is a new way of defining Ingress which cleans up the annotation mess and allows for a clean separation of responsibility in an org.
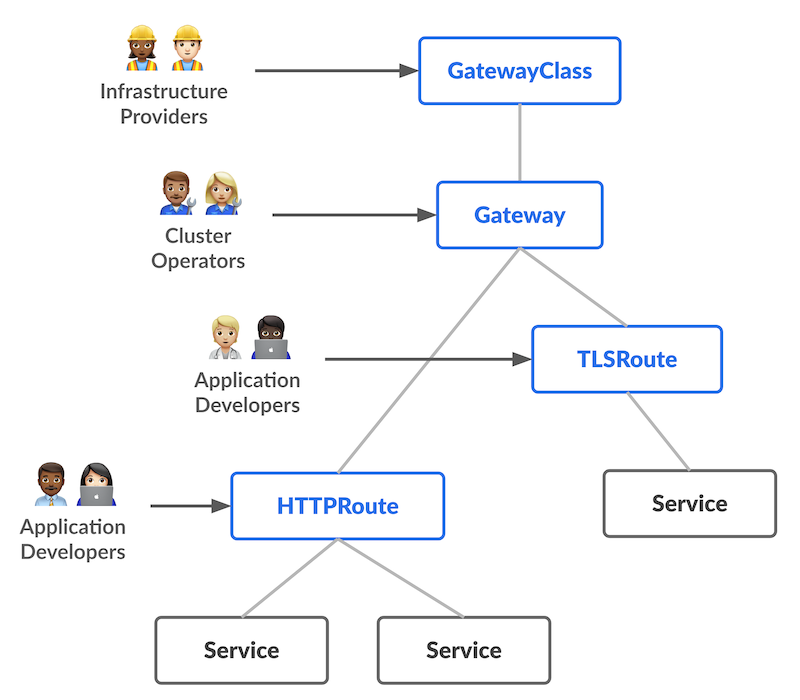
So GCP defines the GatewayClass, I make the Gateway and developer provide the HTTPRoutes. This means developers can safely change the routes to their own services without the risk that they will blow up the load balancer. It also provides a ton of great customization for how to route traffic to a specific service.
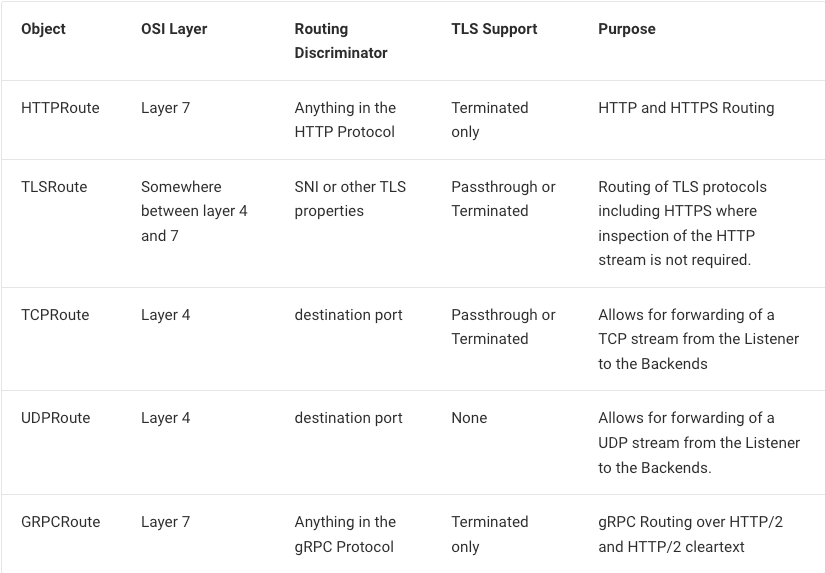
So first you make a Gateway like so in Helm or whatever:
---
kind: Gateway
apiVersion: gateway.networking.k8s.io/v1beta1
metadata:
name: {{ .Values.gateway_name }}
namespace: {{ .Values.gateway_namespace }}
spec:
gatewayClassName: gke-l7-global-external-managed
listeners:
- name: http
protocol: HTTP
port: 80
allowedRoutes:
kinds:
- kind: HTTPRoute
namespaces:
from: Same
- name: https
protocol: HTTPS
port: 443
allowedRoutes:
kinds:
- kind: HTTPRoute
namespaces:
from: All
tls:
mode: Terminate
options:
networking.gke.io/pre-shared-certs: "{{ .Values.pre_shared_cert_name }},{{ .Values.internal_cert_name }}"Then you provide a different YAML of HTTPRoute for the redirect of http to https:
kind: HTTPRoute
apiVersion: gateway.networking.k8s.io/v1beta1
metadata:
name: redirect
namespace: {{ .Values.gateway_namespace }}
spec:
parentRefs:
- namespace: {{ .Values.gateway_namespace }}
name: {{ .Values.gateway_name }}
sectionName: http
rules:
- filters:
- type: RequestRedirect
requestRedirect:
scheme: httpsFinally you can set policies.
---
apiVersion: networking.gke.io/v1
kind: GCPGatewayPolicy
metadata:
name: tls-ssl-policy
namespace: {{ .Values.gateway_namespace }}
spec:
default:
sslPolicy: tls-ssl-policy
targetRef:
group: gateway.networking.k8s.io
kind: Gateway
name: {{ .Values.gateway_name }}Then your developers can configure traffic to their services like so:
kind: HTTPRoute
apiVersion: gateway.networking.k8s.io/v1beta1
metadata:
name: store
spec:
parentRefs:
- kind: Gateway
name: internal-http
hostnames:
- "store.example.com"
rules:
- backendRefs:
- name: store-v1
port: 8080
- matches:
- headers:
- name: env
value: canary
backendRefs:
- name: store-v2
port: 8080
- matches:
- path:
value: /de
backendRefs:
- name: store-german
port: 8080
Seems Straightforward
Right? There isn't that much to the thing. So after I attempted to re-add the HTTPRoutes using Helm and Terraform (which of course didn't detect a diff even though the routes were gone because Helm never seems to do what I want it to do in a crisis) and then ended up bumping the chart version to finally force it do the right thing, I started looking around. What the hell had I done to break this?
When I removed linkerd crds it somehow took out my httproutes. So then I went to the Helm chart trying to work backwards. Immediately I see this:
{{- if .Values.enableHttpRoutes }}
---
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
annotations:
api-approved.kubernetes.io: https://github.com/kubernetes-sigs/gateway-api/pull/1923
gateway.networking.k8s.io/bundle-version: v0.7.1-dev
gateway.networking.k8s.io/channel: experimental
{{ include "partials.annotations.created-by" . }}
labels:
helm.sh/chart: {{ .Chart.Name }}-{{ .Chart.Version | replace "+" "_" }}
linkerd.io/control-plane-ns: {{.Release.Namespace}}
creationTimestamp: null
name: httproutes.gateway.networking.k8s.io
spec:
group: gateway.networking.k8s.io
names:
categories:
- gateway-api
kind: HTTPRoute
listKind: HTTPRouteList
plural: httproutes
singular: httproute
scope: Namespaced
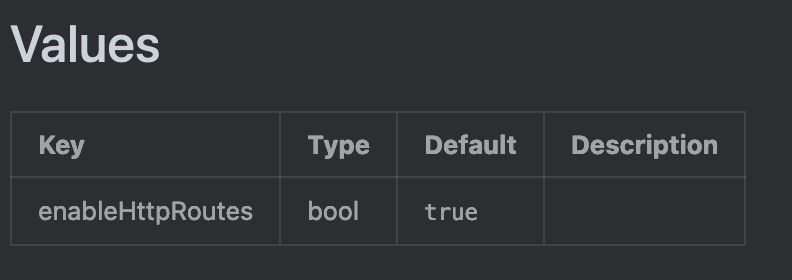
versions:Sure enough, Linkerd CRD Helm chart has that set to default True:
I also found this issue: https://github.com/linkerd/linkerd2/issues/12232
So yeah, Linkerd is, for some reason, pulling this CRD from a pull request from April 6th of last year that is marked as "do not merge". https://github.com/kubernetes-sigs/gateway-api/pull/1923
Linkerd is aware of the possible problem but presumes you'll catch the configuration option on the Helm chart: https://github.com/linkerd/linkerd2/issues/11586
To be clear I'm not "coming after Linkerd" here. I just thought the whole thing was extremely weird and wanted to make sure, given the amount of usage Linkerd gets out there, that other people were made aware of it before running the car into the wall at 100 MPH.
What are CRDs?
Kubernetes Custom Resource Definitions (CRDs) essentially extend the Kubernetes API to manage custom resources specific to your application or domain.
- CRD Object: You create a YAML manifest file defining the Custom Resource Definition (CRD). This file specifies the schema, validation rules, and names of your custom resource.
- API Endpoint: When you deploy the CRD, the Kubernetes API server creates a new RESTful API endpoint for your custom resource.
Effectively when I enabled Gateway API in GKE with the following I hadn't considered that I could end up in a CRD conflict state with Linkerd:
gcloud container clusters create CLUSTER_NAME \
--gateway-api=standard \
--cluster-version=VERSION \
--location=CLUSTER_LOCATION
What I suspect happened is, since I had Linkerd installed before I had enabled the gateway-api on GKE, when GCP attempted to install the CRD it failed silently. Since I didn't know there was a CRD conflict, I didn't understand that the CRD that the HTTPRoutes relied on was actually the Linkerd maintained one, not the GCP one. Presumably had I attempted to do this the other way it would have thrown an error when the Helm chart attempted to install a CRD that was already present.
To be clear before you call me an idiot, I am painfully aware that the deletion of CRDs is a dangerous operation. I understand I should have carefully checked and I am admitting I didn't in large part because it just never occurred to me that something like Linkerd would do this. Think of my failure to check as a warning to you, not an indictment against Kubernetes or whatever.
Conclusion
If you are using Linkerd and Helm and intend to use Gateway API, this is your warning right now to go in there and flip that value in the Helm chart to false. Learn from my mistake.
Questions/comments/concerns: https://c.im/@matdevdug