
When you start using Kubernetes one of the first suggestions you'll get is to install a service mesh. This, of course, on top of the 900 other things you need to install. For those unaware, everything in k8s is open to everything else by default when you start and traffic isn't encrypted between services. Since encrypting traffic between services and controlling what services can talk to which requires something like a JWT and client certificates, teams aren't typically eager to take on this work even though its increasingly a requirement of any stack.
Infrastructure teams can usually implement a feature faster than every app team in a company, so this tends to get solved by them. Service meshes exploded in popularity as it became clear they were easy ways to implement enforced encryption and granular service to service access control. You also get better monitoring and some cool features like circuit breaking and request retries for "free". As the scale of deployments grew with k8s and started to bridge multiple cloud providers or a cloud provider and a datacenter, this went from "nice to have" to an operational requirement.
What is a service mesh?

Service meshes let you do a few things easily
- Easy metrics on all service to service requests since it has a proxy that knows success/failure/RTT/number of requests
- Knowledge that all requests are encrypted with automated rotation
- Option to ensure only encrypted requests are accepted so you can have k8s in the same VPC as other things without needing to do firewall rules
- Easy to set up network isolation at a route/service/namespace level (great for k8s hosting platform or customer isolation)
- Automatic retries, global timeout limits, circuit breaking and all the features of a more robustly designed application without the work
- Reduces change failure rate. With a proxy sitting there holding and retrying requests, small blips don't register anymore to the client. Now they shouldn't anyway if you set up k8s correctly but its another level of redundancy.
This adds up to a lot of value for places that adopt them with a minimum amount of work since they're sidecars injected into existing apps. For the most part they "just work" and don't require a lot of knowledge to keep working.
However, it's 2024 and stuff that used to be free isn't anymore. The free money train from VCs has ended and the bill has come due. Increasingly, this requirement for deploying production applications to k8s is going to come with a tax that you need to account for when budgeting for your k8s migration and determining whether it is worth it. Since December 2023 the service mesh landscape has changed substantially and it's a good time for a quick overview of what is going on.
NOTE: Before people jump down my throat, I'm not saying these teams shouldn't get paid. If your tool provides real benefits to businesses it isn't unreasonable to ask them to materially contribute to it. I just want people to be up to speed on what the state of the service mesh industry is and be able to plan accordingly.
Linkerd
My personal favorite of the service meshes, Linkerd is the most idiot proof of the designs. It consists of a control plane and a data plane with a monitoring option included. It looks like this:

Recently Linkerd has announced a change to their release process, which I think is a novel approach to the problem of "getting paid for your work". For those unaware, Linkerd has always maintained a "stable" and an "edge" version of their software, along with an enterprise product. As of Linkerd 2.15.0, they will no longer publish stable releases. Instead the concept of a stable release will be bundled into their Buoyant Enterprise for Linkerd option. You can read the blog post here.
Important to note that unlike some products, Linkerd doesn't just take a specific release of Edge and make it Enterprise. There are features that make it to Edge that never get to Enterprise, Stable is also not a static target (there are patch releases to the Stable branch as well), so these are effectively three different products. So you can't do the workaround of locking your org to specific Edge releases that match up with Stable/Enterprise.
Pricing
Update: Linkerd changed their pricing to per-pod. You can see it here: https://buoyant.io/pricing. I'll leave the below for legacy purposes but the new pricing addresses my concerns.
Buoyant has selected the surprisingly high price of $2000 a cluster per month. The reason this is surprising to me is the model for k8s is increasingly moving towards more clusters with less in a cluster, vs the older monolithic cluster where the entire company lives in one. This pricing works against that goal and removes some of the value of the service mesh concept.
If the idea of the Linkerd team is that orgs are going to stick with fewer, larger clusters, then it makes less sense to me to go with Linkerd. With a ton of clusters, I don't want to think about IP address ranges or any of the east to west networking designs, but if I just have like 2-3 clusters that are entirely independent of each other, then I can get a similar experience to Linkerd with relatively basic firewall rules, k8s network policies and some minor changes to an app to encrypt connections. There's still value to Linkerd, but the per-cluster pricing when I was clearly fine hosting the entire thing myself before is strange.
$2000 a month for a site license makes sense to me to get access to enterprise. $2000 a month per cluster when Buoyant isn't providing me with dashboards or metrics on their side seems like they picked an arbitrary number out of thin air. There's zero additional cost for them per cluster added, it's just profit. It feels weird and bad. If I'm hosting and deploying everything and the only support you are providing me is letting me post to the forum, where do you come up with the calculation that I owe you per cluster regardless of size?
Now you can continue to use Linkerd, but you need to switch to Edge. In my experience testing it, Edge is fine. It's mostly production ready, but there are sometimes features which you'll start using and then they'll disappear. I don't think it'll matter for most orgs most of the time, since you aren't likely constantly rolling out service mesh upgrades. You'll pick a version of Edge, test it, deploy it and then wait until you are forced to upgrade or you see a feature you like.
You also can't just buy a license, you need to schedule a call with them to buy a license with discounts available before March 21st, 2024. I don't know about you but the idea of needing to both buy a license and have a call to buy a license is equally disheartening. Maybe just let me buy it with the corporate card or work with the cloud providers to let me pay you through them.
Cilium
Cilium is the new cool kid on the block when it comes to service meshes. It eliminates the sidecar container, removing a major source of failure in the service mesh design. You still get encryption, load balancing, etc but since it uses eBPF and is injected right into the kernel you remove that entire element of the stack.

You also get a LOT with Cilium. It is its own CNI, which in my testing has amazing performance. It works with all the major cloud providers, it gives you incredibly precise network security and observability. You can also replace Kube-proxy with cilium. Here is how it works in a normal k8s cluster with Kube-proxy:
Effectively Kube-proxy works with the OS filtering layer (typically iptables) to allow network communication to your pods. This is a bit simplified but you get the idea.
With the BPF Kube-proxy replacement we remove a lot of pieces in that design.
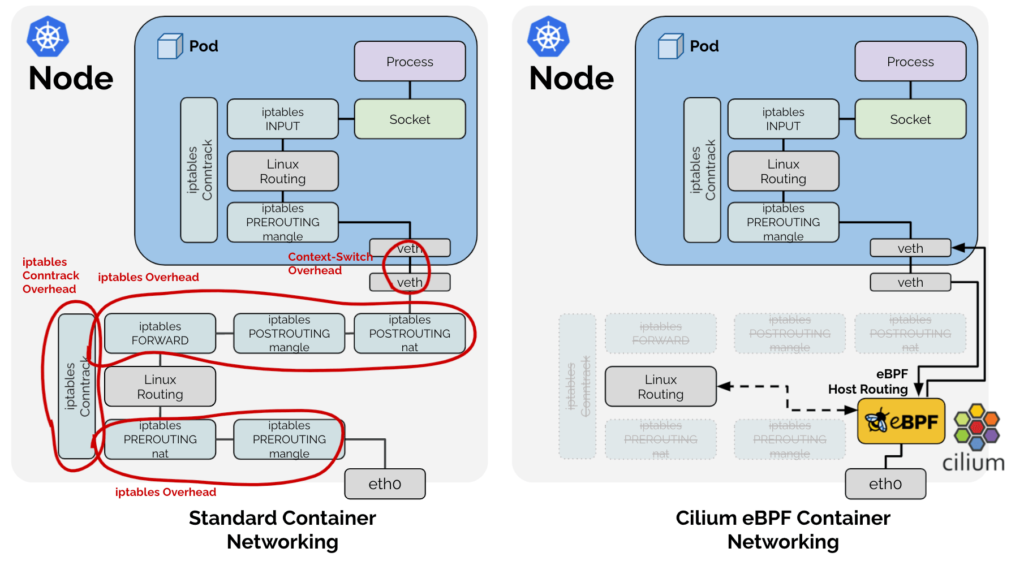
This is only a tiny fraction of what Cilium does. It has developed a reputation for excellence, where if you full adopt the stack you can replace almost all the cloud-provider specific pieces for k8s to a generic stack that works across providers at a lower cost and high performance.
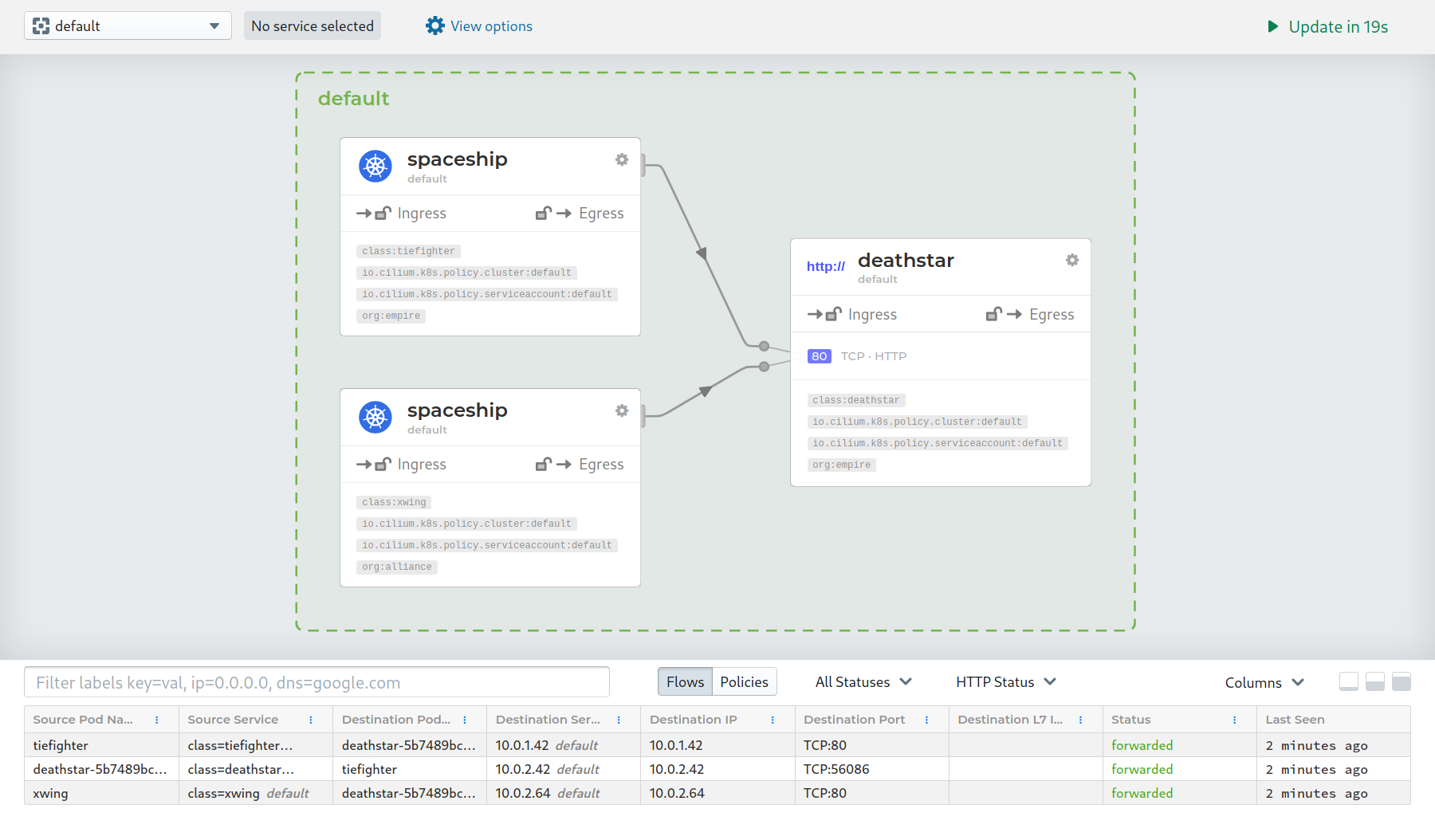
A Wild Cisco Appears
Cisco recently acquired Isovalent in December of 2023, apparently to get involved in the eBPF space and also likely to augment their acquisition of Splunk. Cilium provides the metrics and traces as well as generating great flow logs and Splunk ingests them for you. If you are on Linkerd and considering moving over to Cilium to avoid paying, you should be aware that with Cisco having purchased them the bill is inevitable.
You will eventually be expected to pay and my guess based on years of ordering Cisco licenses and hardware is you'll be expected to pay a lot. So factor that in when considering Cilium or migrating to Cilium. I'll go out on a limb here and predict that Cilium is priced as a premium multi-cloud product with a requirement of the enterprise license for many of the features before the end of 2024. I will also predict that Linkerd ends up as the cheapest option on the table by the end of 2024 for most orgs.
Take how expensive Splunk is and extrapolate that into a service mesh license and I suspect you'll be in the ballpark.
Istio

Istio, my least favorite service mesh. Conceptually Istio and Linkerd share many of the same ideas. Both platforms use a two-part architecture now: a control plane and a data plane. The control plane manages the data plane by issuing configuration updates to the proxies in the data plane. The control plane also provides security features such as mTLS encryption and authentication.
Istio uses Envoy proxies vs rolling their own like Linkerd and tends to cover more possible scenarios than Linkerd. Here's a feature comparison:
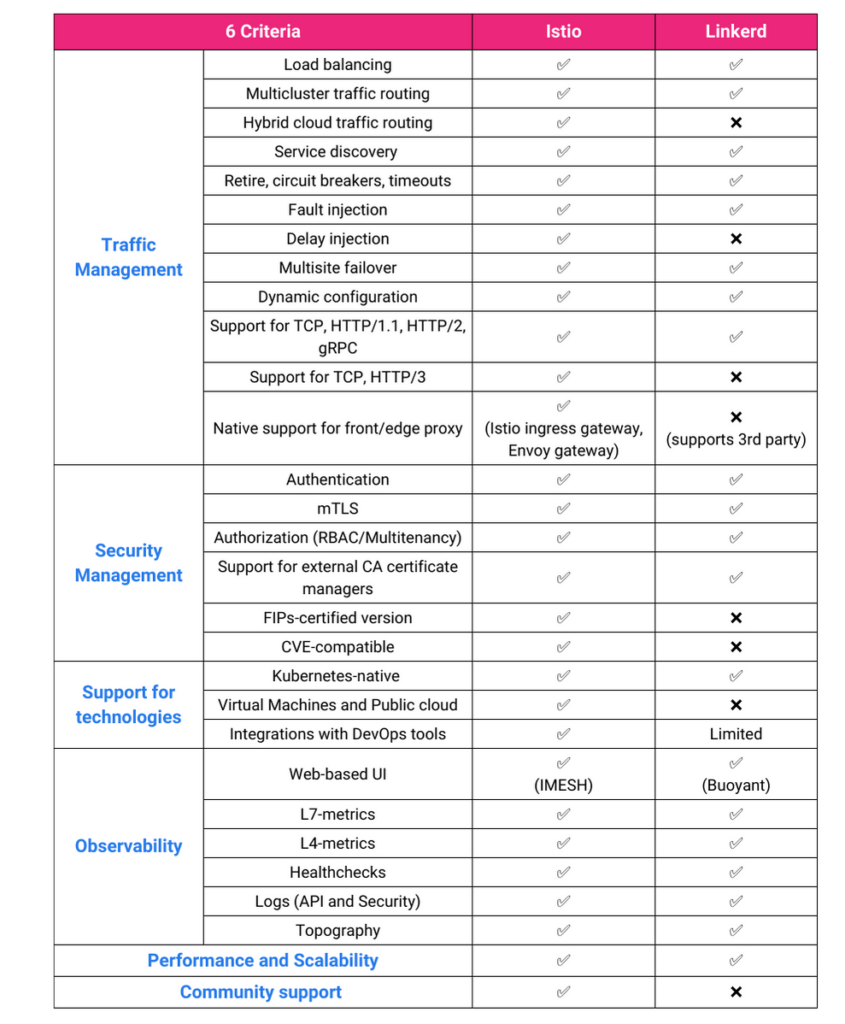
Istio's primary differences are that it supports VMs, runs its own Ingress Controller and is 10x the complexity of setting up any other option. Istio has become infamous among k8s infrastructure staff as being the cause of more problems than any other part of the stack. Now many of these can be solved with minor modifications to the configuration (there is absolutely nothing structurally wrong with Istio), but since a service mesh failure can be "the entire cluster dies", it's tricky.
The reality is Istio is free and open source, but you pay in other ways. Istio has so many components and custom resources that can interact with each other in surprising and terrifying ways that you need someone in your team who is an Istio expert. Otherwise any attempt to create a self-service ecosystem will result in lots of downtime and tears. You are going to spend a lot of time in Istio tracking down performance problems, weird network connectivity issues or just strange reverse proxy behavior.
Some of the earlier performance complaints of Envoy as the sidecar have been addressed, but I still hear of problems when organizations scale up to a certain number of requests per second (less than I used to). The cost for Istio, to me, exceeds the value of a service mesh most of the time. Especially since Linkerd has caught up with most of the traffic management stuff like circuit breaking.
Consul Connect
The next service mesh we'll talk about is Consul Connect. If Istio is highly complicated to set up and Linkerd is easiest but fewest knobs to turn, Consul sits right in the middle. It has a great story when it comes to observability and has performance right there with Linkerd and superior to Istio.

Consul is also very clearly designed to be deployed by large companies, with features around stability and cross-datacenter design that only apply to the biggest orgs. However people who have used it seem to really like it, based on the chats I've had. The ability to use Terraform with Consul with its Consul-Terraform-Sync functionality to get information about services and interact with those services at a networking level is massive, especially for teams managing thousands of nodes or where pods need strict enforced isolation (such as SaaS products where customer app servers can't interact).
Pricing
Consul starts at $0.027 an hour, but in practice your price is gonna be higher than that. It goes up based on how many instances and clusters you are running. It's also not available on GCP, just AWS and Azure. You also don't get support with that, seemingly needing to upgrade your package to ask questions.

I'm pretty down on Hashicorp after the Terraform change, but people have reported a lot of success with Consul so if you are considering a move, this one makes a lot of sense.
Cloud Provider Service Meshes
GCP has Anthos (based on Istio) as part of their GKE Enterprise offering, which is $.10/cluster/hour. It comes with a bunch of other features but in my testing was a much easier way to run Istio. Basically Istio without the annoying parts. AWS App Mesh still uses Envoy but has a pretty different architecture. However it comes with no extra cost which is nice.
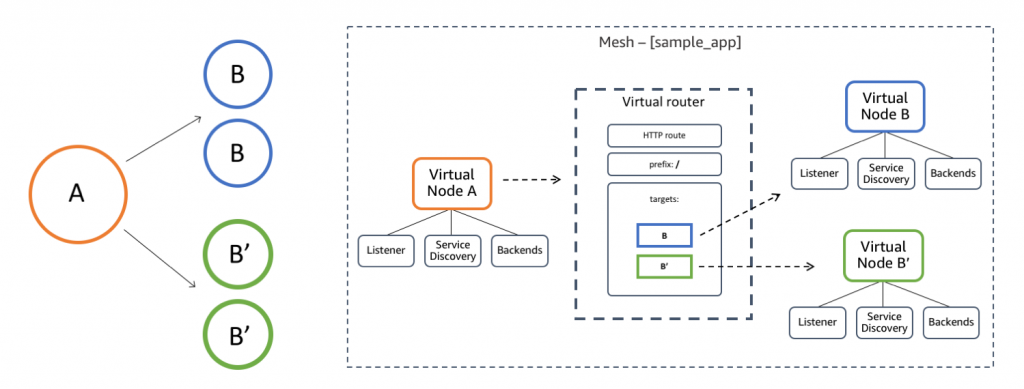
AWS App Mesh is also great for orgs that aren't all-in for k8s. You can bridge systems like ECS and traditional EC2 with it, meaning its a super flexible tool for hybrid groups or groups where the k8s-only approach isn't a great fit.
Azure uses Open Service Mesh which is now a deprecated product. Despite that, it's still their recommend solution according to a Google search. Link

Once again the crack team at Azure blows me away with their attention to detail. Azure has a hosted Istio add-on in preview now and presumably they'll end up doing something similar to GKE with Anthos. You can see that here.
What do you need to do
So the era of the free Service Mesh is coming to a close. AWS has decided to use it as an incentive to stay on their platform, Linkerd is charging you, Cilium will charge you At Some Point and Consul is as far from free now as it gets. GKE and Azure seem to be betting on Istio where they move the complexity into their stack, which makes sense. This is a reflection of how valuable these meshes are for observability and resilience as organizations transition to microservices and more specifically split stacks, where you retain your ability to negotiate with your cloud provider by running things in multiple places.
Infrastructure teams will need to carefully pick what horse they want to back moving forward. It's a careful balance between cloud lock-in vs flexibility at the cost of budget or complexity. There aren't any clear-cut winners in the pack, which wasn't true six months ago when the recommendation was just Linkerd or Cilium. If you are locked into either Linkerd or Cilium, the time to start discussing a strategy moving forward is probably today. Either get ready for the bill, commit to running Edge with more internal testing, or brace yourself for a potentially much higher bill in the future.