There is no denying that containers have taken over the mindset of most modern teams. With containers, comes the need to have orchestration to run those containers and currently there is no real alternative to Kubernetes. Love it or hate it, it has become the standard platform we have largely adopted as an industry. If you exceed the size of docker-compose, k8s is the next step in that journey.
Despite the complexity and some of the hiccups around deploying, most organizations that use k8s that I've worked with seem to have positive feelings about it. It is reliable and the depth and width of the community support means you are never the first to encounter a problem. However Kubernetes is not a slow-moving target by infrastructure standards.

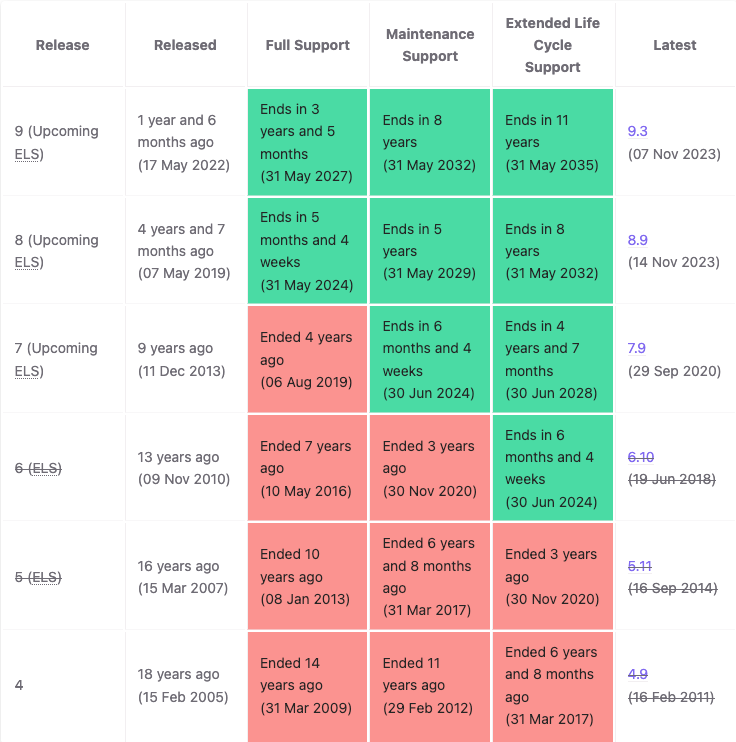
Kubernetes follows an N-2 support policy (meaning that the 3 most recent minor versions receive security and bug fixes) along with a 15-week release cycle. This results in a release being supported for 14 months (12 months of support and 2 months of upgrade period). If we compare that to Debian, the OS project a lot of organizations base their support cycles on, we can see the immediate difference.

Red Hat, whose entire existence is based on organizations not being able to upgrade often, shows you at what cadence some orgs can roll out large changes.
Now if Kubernetes adopted this cycle across OSS and cloud providers, I would say "there is solid evidence that it can be done and these clusters can be kept up to date". However cloud providers don't hold their customers to these extremely tight time windows. GCP, who has access to many of the Kubernetes maintainers and works extremely closely with the project, doesn't hold customers to anywhere near these timelines.
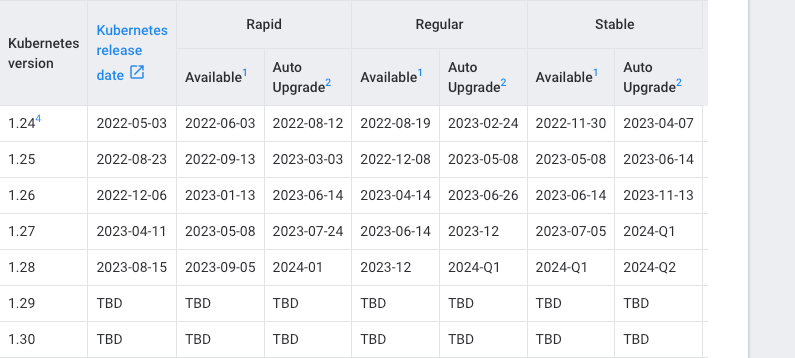
Neither does AWS or Azure. The reality is that nobody expects companies to keep pace with that cadence of releases because the tooling to do so doesn't really exist. Validating that a cluster can be upgraded and that it is safe to do so requires the use of third-party tooling or to have a pretty good understanding of what APIs are getting deprecated when. Add in time for validating in staging environments along with the sheer time involved in babysitting a Kubernetes cluster upgrade and a clear problem emerges.
What does upgrading a k8s cluster even look like?
For those unaware of what a manual upgrade looks like, this is the rough checklist.
- Check all third-party extensions such as network and storage plugins
- Update etcd (all instances)
- Update kube-apiserver (all control plane hosts)
- Update kube-controller-manager
- Update kube-scheduler
- Update the cloud controller manager, if you use one
- Update kubectl
- Drain every node and either replace the node or upgrade the node and then readd and monitor to ensure it continues to work
- Run
kubectl convertas required on manifests
None of this is rocket science and all of it can be automated, but it still requires someone to effectively be super on top of these releases. Most importantly it is not substantially easier than making a new cluster. If upgrading is, at best, slightly easier than making a new cluster and often quite a bit harder, teams can get stuck unsure what is the correct course of action. However given the aggressive pace of releases, spinning up a new cluster for every new version and migrating services over to it can be really logistically challenging.
Consider that you don't want to be on the .0 of a k8s release, typically .2. You lose a fair amount of your 14 month window waiting for that criteria. Then you spin up the new cluster and start migrating services over to it. For most teams this involves a fair amount of duplication and wasted resources, since you will likely have double the number of nodes running for at least some period in there. CI/CD pipelines need to get modified, docs need to get changed, DNS entries have to get swapped.
None of this is impossible stuff, or even terribly difficult stuff, but it is critical and even with automation the risk of one of these steps failing silently is high risk enough that few folks I know would fire and forget. Instead clusters seem to be in a state of constant falling behind unless the teams are empowered to make keeping up with upgrades a key value they bring to the org.
My experience with this has been extremely bad, often joining teams where a cluster has been left to languish for too long and now we're running into concerns over whether it can be safely upgraded at all. Typically my first three months running an old cluster is telling leadership I need to blow our budget out a bit to spin up a new cluster and cut over to it namespace by namespace. It's not the most gentle onboarding process.
Proposed LTS
I'm not suggesting that the k8s maintainers attempt to keep versions around forever. Their pace of innovation and adding new features is a key reason the platform has thrived. What I'm suggesting is a dead-end LTS with no upgrade path out of it. GKE allowed customers to be on 1.24 for 584 days and 1.26 for 572 days. Azure has a more generous LTS date of 2 years from the GA date and EKS from AWS is sitting at around 800 days that a version is supported from launch to end of LTS.
These are more in line with the pace of upgrades that organizations can safely plan for. I would propose an LTS release with a 24 months of support from GA and an understanding that the Kubernetes team can't offer an upgrade to the next LTS. The proposed workflow for operations teams would be clusters that live for 24 months and then organizations need to migrate off of them and create a new cluster.
This workflow makes sense for a lot of reasons. First creating fresh new nodes at regular intervals is best practice, allowing organizations to upgrade the underlying linux OS and hypervisor upgrades. While you should obviously be upgrading more often than every 2 years, this would be a good check-in point. It also means teams take a look at the entire stack, starting with a fresh ETCD, new versions of Ingress controllers, all the critical parts that organizations might be loathe to poke unless absolutely necessary.
I also suspect that the community would come in and offer a ton of guidance on how to upgrade from LTS to LTS, since this is a good injection point for either a commercial product or an OSS tool to assist with the process. But this wouldn't bind the maintainers to such a project, which I think is critical both for pace of innovation and just complexity. K8s is a complicated collection of software with a lot of moving pieces and testing it as-is already reaches a scale most people won't need to think about in their entire careers. I don't think its fair to put this on that same group of maintainers.
LTS WG
The k8s team is reviving the LTS workgroup, which was disbanded previously. I'm cautiously optimistic that this group will have more success and I hope that they can do something to make a happier middle ground between hosted platform and OSS stack. I haven't seen much from that group yet (the mailing list is empty: https://groups.google.com/a/kubernetes.io/g/wg-lts) and the Slack seems pretty dead as well. However I'll attempt to follow along with them as they discuss the suggestion and update if there is any movement.
I really hope the team seriously considers something like this. It would be a massive benefit to operators of k8s around the world to not have to be in a state of constantly upgrading existing clusters. It would simplify the third-party ecosystem as well, allowing for easier validation against a known-stable target that will be around for a little while. It also encourages better workflows from cluster operators, pushing them towards the correct answer of getting in the habit of making new clusters at regular intervals vs keeping clusters around forever.