
It always starts the same way. A demo is shown where a previously complex problem set is reduced down to running one Magic Tool. It is often endorsed by one of the Big Tech Companies or maintained by them. Some members of the organization start calling for the immediate adoption of this technology. Overnight this new tool becomes a shorthand for "solution to all of our problems".
By the time it gets to the C-level, this tool is surrounded by tons of free press. You'll see articles like "X technology is deprecated, it's time to get onboard with Magic Tool". Those of you new to working in tech probably assume some due-diligence was done to see if the Magic Tool was good or secure or actually a good fit for that particular business. You would be incorrect.
Soon an internal initiative is launched. Some executive decides to make it an important project and teams are being told they have to adopt the Magic Tool. This is typically where the cracks first start to show up, when teams who are relatively apathetic towards the Magic Tool start to use them. "This doesn't do all the things our current stuff does and accounting for the edge cases is a lot more difficult than we were told".
Sometimes the team attempting to roll out this new tech can solve for the edge cases. As time drags on though, the new Magic Tool starts to look as complicated and full of sharp edges as their current tooling. At the end of all this work and discussion, organizations are lucky to see a 2-5% gain in productivity and nothing like the quantum leap forward implied by the advocates for Magic Tool.
Why is this such a common pattern?
We are obsessed with the idea that writing software shouldn't be this hard. None of us really know what we're doing when we start. Your credentials for this job are you learned, at school or at home, how to make small things by yourself. Birdhouses of Java, maybe a few potato clocks of Python. Then you pass a series of interviews where people ask you random, mostly unrelated questions to your job. "How would you make a birdhouse that holds 100,000 birds?" Finally you start working and are asked to construct a fighter jet with 800 other people. The documentation you get when you start describes how to make an F-150 pickup.
So when we see a tutorial or demo which seems to just do the right thing all the time, it lights a fire in people. Yes, that's how this was always supposed to be. The issue wasn't me or my coworkers, the problem was our technology was wrong. The clouds part, the stars align, everything makes sense again. However almost always that's wrong. Large technology changes that touch many teams and systems are never going to be easy and they're never going to just work. The technology might still be superior to be clear, but easy is a different beast.
I'll present 3 examples of good technologies whose user experience for long-term users is worse because of a desire to keep on-boarding as simple as possible. Where the enthusiasm for adoption ultimately hurts the daily usage of these tools. Docker, Kubernetes and Node. All technologies wildly loved in the community whose features are compelling but who hide the true complexity of adoption behind fast and simple tutorials.
To be clear I'm not blaming the maintainers of this software. What I'm trying to suggest is we need to do a better job of frontloading complexity, letting people know the scope and depth of a thing before we attempt to sell it to the industry at large. Often we get into these hype bubbles where this technology is presented as "inevitable", only to have intense disappointment when the reality sinks in.
Your app shouldn't be root inside of a container
Nowhere I think is this more clear than how we have fundamentally failed the container community in fundamental security. Job after job, meetup after meetup, I encounter folks who are simply unaware that the default model for how we build containers is the wrong way to do it. Applications in containers should not be root by default.
But what does root in a container even mean? It's actually not as simple as it sounds. A lot of work has happened behind the scenes to preserve the simple user experience and hide this complexity from you. Let's talk about how Docker went at this problem and how Podman attempts to fix it.
However you need to internalize this. If you are running a stock configured container with a root user and someone escapes that container, you are in serious trouble. Kubernetes or no Kubernetes.
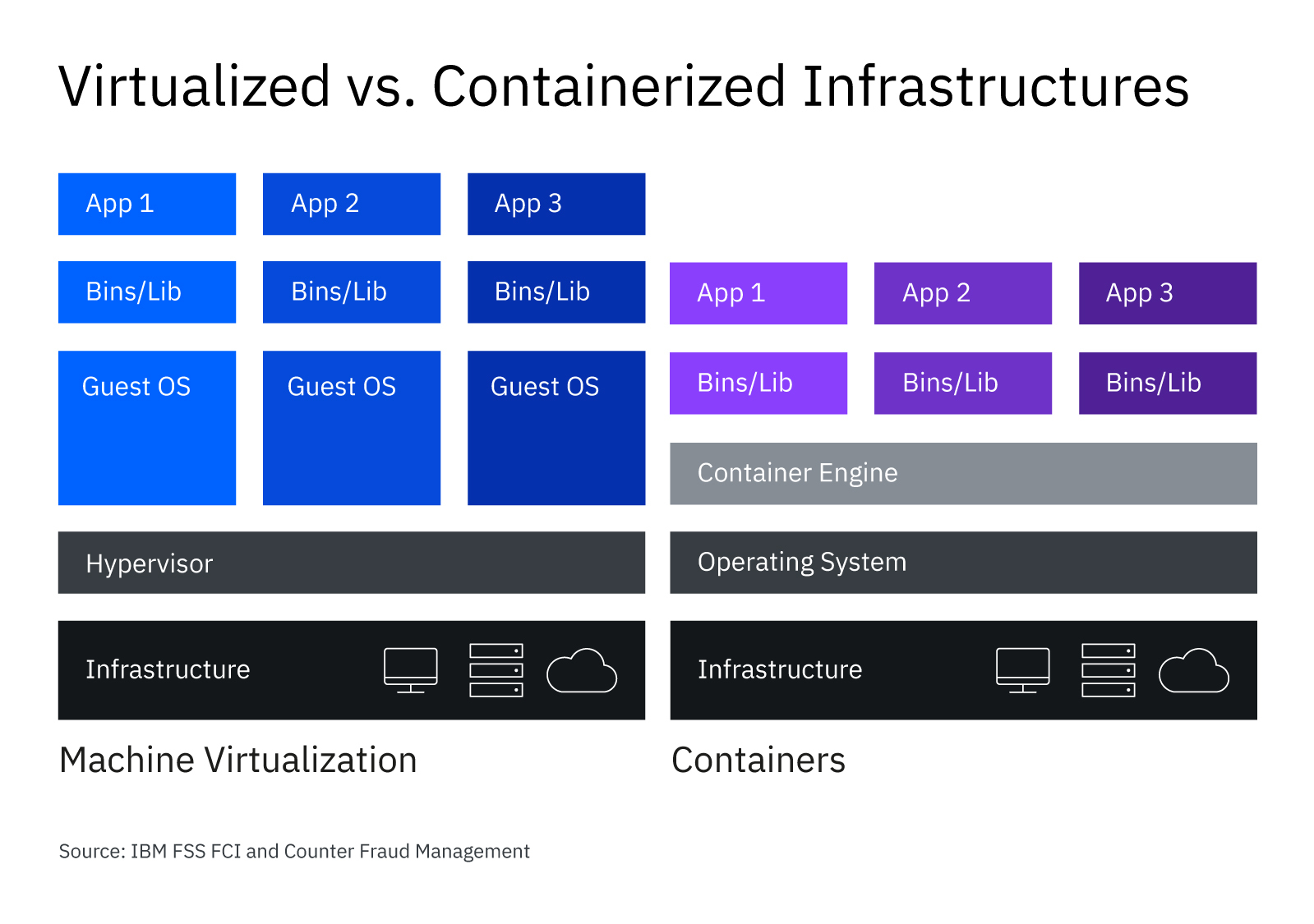
Docker
When Docker launched and started to become popular, a lot of eyebrows were raised at it running as root on the host. The explanation made sense though for two reasons: mounting directories without restriction inside of the container and for binding to ports below 1024 on Linux. For those that don't know, any port at or below 1024 on Linux is a privileged port. Running the daemon as root is no longer a requirement of Docker but there are still the same restrictions in terms of port and directory mounting along with host networking and a bevy of other features.
This caused a lot of debate. It seemed crazy to effectively eliminate the security of Linux users for the sake of ease of deployment and testing, but community pressure forced the issue through. We were told this didn't really matter because "root in containers wasn't really root". It didn't make a ton of sense at first but we all went with it. Hello to kernel namespaces.
Namespaces in Linux are, confusingly, nothing like namespaces in Kubernetes. They're an isolation feature, meaning one service running in one namespace cannot see or access a process running in another namespace. There are user namespaces allowing users to have root in a namespace without that power transferring over. Process ID namespaces, meaning there can be multiple PID 1s running isolated from one another. Network namespace with a networking stack, mount namespace which allows for mounting and unmounting without changing the host, IPC namespaces for distinct and isolated POSIX message queues and finally UTS namespaces for different host and domain names.
The sales pitch makes sense. You can have multiple roots, running a ton of processes that are isolated from each other in distinct networking stacks that change mounts and send messages inside of a namespace without impacting other namespaces. The amount of resources and the priority of those resources are controlled by cgroups, which is how cpu and memory limits work for containers.
Sound great. What's the issue?
Namespaces and cgroups are not perfect security and certainly not something you can bet the farm on without a lot of additional context. For instance, running a container with --privileged
To be fair they're gone to great lengths to try and keep the Docker container experience as simple as possible while attempting to improve security. By default Docker drops some Linux capabilities and you can expand that list as needed. Here is a list of all of the Linux capabilities. Finally, here are the ones that Docker uses. You can see here a security team trying desperately to get ahead of the problem and doing a good job.
The problem is that none of this was communicated to people during the adoption process. It's not really mentioned during tutorials, not emphasized during demos and requires an understanding of Linux to really go at this problem space. If Docker had frontloaded this requirement into the tooling, pushing you to do the right thing from the beginning, we'd have an overall much more secure space. That would have included the following:
- Warning users a lot when they run the
--privilegedflag - By default creating a new user or userspace with containers that isn't root and creating one common directory for that user to write to.
- Having
--cap-drop=allbe the default and having users add each cap they needed. - Running
--security-opt=no-new-privilegesas default - Adding resource definitions by default as outlined here: https://docs.docker.com/engine/reference/run/#runtime-constraints-on-resources
- Helping people to write AppArmor or some security tooling as shown here.
- Turning User Namespaces on by default if you are root. This allows a container root user to be mapped to a non uid-0 user outside the container and reduces the value of escaping the container.
Instead we've all adopted containers as a fundamental building block of our technologies and mostly did it wrong. Podman solves a lot of these problems btw and should be what you use from now on. By starting fresh they skipped a lot of the issues with Docker and have a much more sustainable and well-designed approach to containers and security in general. Hats off to that team.
How do I tell if my containers are correctly made?
Docker made a great tool to help with this which you can find here. Called Docker Bench for Security, it allows you to scan containers, see if they're made securely and suggests recommendations. I'm a big fan and have learned a lot about the correct ways to use Docker from using it.
Kubernetes
I was introduced to Kubernetes years ago as "the system Google uses". Now this turns out not to actually be true, the internal Google system branched off from the design of K8s a long time ago, but it still represented a giant leap forward in terms of application design. Overnight organizations started to adopt it aggressively, often not truly understanding what it was or the problem it tried to solve. Like all tools, Kubernetes is good at some problem areas and terrible at others.
I personally love k8s and enjoy working with it. But many of the early pitches promised things that, in retrospect, were insane. K8s is neither easy to understand or easy to implement, with many sharp edges and corner cases which you run into with surprising frequency. Minikube demos are not a realistic representation of what the final product looks like.
Here's the truth: k8s is a bad choice for most businesses.
The demos for Kubernetes certainly look amazing, right? You take your containers, you shove them into the cloud, it does the right thing, traffic goes to the correct place, it's all magical. Things scale up, they scale down, you aren't locked into one specific vendor or solution. There's an API for everything so you can manage every element from one single control plane. When you first start using k8s it seems magical, this overlay on top of your cloud provider that just takes care of things.

The Reality
The reality is people should have been a lot more clear when introducing k8s as to what problems it is trying to solve and which ones it isn't. K8s is designed for applications that are totally ephemeral, they don't rely on local storage, they receive requests, process them and can be terminated with very little thought. While there might (now) be options for storage, they're a bad idea to use generally due to how storage works with different AZs in cloud providers. You can do things like batch jobs and guaranteed runs inside of k8s, but that's a different design pattern from the typical application.
K8s is also not bulletproof. You'll often run into issues with DNS resolution at scale since the internal networking is highly dependent on it. It comes by default wide open, allowing you to make namespaces that do not isolate network traffic (common mistake I hear all the time). Implementing a service mesh is mandatory as is some sort of tracing solution as you attempt to find what route is causing problems. Control plane problems are rare but catastrophic when they happen. Securing API endpoints and traffic in general requires diligence.
You also need to do a ton of research before you even start k8s. What CNI is best for you, how is external DNS going to work, how are you going to load balance traffic, where is SSL termination happening, how are you going to upgrade the nodes actually running these containers, monitoring and graphs and alerting and logs all need to be mapped out and planned. Are your containers secure? Do you understand your application dependencies between apps?
In order to run k8s at scale across a few hundred developers, a few people in your org need to become extremely familiar with how it works. They will be the technical troubleshooting resource as application teams attempt to work backwards to the problem space. These people will need to be available for questions all the time. Remember you are taking:
- A entire cloud environment with IAM, VPCs, security policies, Linux servers, buckets, message queues, everything else
- Adding effectively an entirely new environment on top of that. These two systems still interact and can cause problems for each other, but they have very little visibility from one into the other. This can cause infuriatingly hard to diagnose problems.
So in order to do this correctly, you need people who understand both problem spaces and can assist with sorting where each step is happening.
So when should I use kubernetes?
- You are spending a ton of money on containers that are being underused or adding additional capacity to try and keep uptime during failures. K8s is really amazing at resource management and handling node or pod failure.
- You are deeply committed to microservices. K8s meshes well with typical microservices, allowing you to bake in monitoring and tracing along with clear relationships between microservices through service meshes.
- Multicloud is a requirement. Be super careful about making this a requirement. It's often a giant mistake.
- Vendor lock-in is a serious concern. Only applicable if you are a Fortune 500. Otherwise don't waste brain cycles on this.
- Uptime is critical above all. The complexity pays off in uptime.
- You are trying to find a bridge technology between your datacenter and the cloud
Otherwise use literally one of a million other options. Starting a new company? Use Lightsail. Too big for Lightsail? Try ECS. You can grow to an extremely large size on these much simpler technologies. If you have maxed out Lightsail, good news, you are now big enough to hire a team. If you decide to go to k8s understand and map out exactly what you want from it. Don't assume turning it on and pushing out some yaml is good enough.
Planning for k8s correctly
The best guide I've seen and one I've used a few times is the NSA k8s hardening guide. It walks through all the common issues and concerns with using k8s at scale, offering good common-sense recommendations at each step. If you are an organization considering using k8s or currently using it and are unsure whether you have it correctly set up, walking through this guide and discussing the points it brings up should at least allow you to approach the project with the correct mindset.
Node.js
Node by itself I have no issues with. I have no particular dog in that race of "should we be writing the backend and frontend in the same language". No, my issue with Node is really with NPM. After working with teams relying on NPM extensively to provide both private, internal packages and to build applications using external third-party dependencies, I'm convinced it is unsafe at any speed.

NPM: Easy over Safe
For a long time application development has followed a pretty stable path in terms of dependencies. You try to write as much as possible with the standard library of your given programming language, only pulling in third-party dependencies when it saved a tremendous amount of time or when they were taking care of something normal people shouldn't be getting involved in (like hashing passwords or creating database connections).
Typically you moved these dependencies into your project for the rest of the projects life, so during a code review process there was often a debate over "does it make sense to import x lines of code forever" in order to save time or add this new functionality. Often the debate hinged on maintenance burdens, where writing functionality using only the standard library made it relatively easy to upgrade between versions.
However dependencies, especially complicated or big dependencies, introduce a lot of possible long term issues. They themselves often have dependencies, or take advantage of more esoteric aspects of a language in order to solve for problems that your project often doesn't have (since the library has a wider use case than just you).
Here's an example. I was working on a PHP application with someone else and I needed to do some junk with S3. I (of course) added the official AWS SDK for PHP, thinking this was the correct way to do things. A more experienced developer stopped me, pointing out correctly that I was adding a ton of new code to the repo forever and maybe there was a better way to do this.
curl -s https://api.github.com/repos/aws/aws-sdk-php | jq '.size' | numfmt --to=iec --from-unit=1024
190MAs it turns out this was relatively easy to do without loading the entire SDK into our codebase forever and introducing a lot of new dependencies. However this back and forth consumes time and often requires folks to becomes much more familiar with the services their applications consume. Client libraries for SaaS often hide this complexity behind very simple methods that allow you to quickly drop in an API key and keep going.
Rise of Node
Node emerged onto the scene with a very different promise as compared to most server-side languages. What if, instead of front and backend teams working on different applications forever waiting for new API endpoints to get added, they were maintained by the same group. Driven by these potential cost and effort savings, Node was introduce to the world and has (mostly) lived up to this core promise.
I remain impressed by the concurrency model for Node, which I feel I need to say in order to stop people from accusing me of attacking the platform simply because it is Javascript. I've worked with teams that have exclusively lived inside of Node for years, many of them have extremely positive things to say. There is certainly a part of me that is jealous of their ability to become deep experts on Javascript and using that skillset across a wide variety of tooling.
The real advantage of Node though was the speed by which teams could build complex functionality even with limited backend knowledge. The low barrier to entry to NPM meant anyone was able to very quickly take some classes and make them available to the entire internet. At first this seemed fine, with developers enjoying how easy it was to have reproducible builds across different workspaces and machines with NPM.
As time went on these endless lists of dependencies started to introduce real maintenance burdens well in excess of their value. By emphasizing speed over safety NPM (and by extension Node) has now become dangerous to recommend for anyone to use in handling customer data in virtually any capacity.
NPM Problems
My first large Node application, I was shocked when I measured the count of third-party code to code in the actual application. We had almost a million lines of external code to our several thousand lines of application code. Graphing out these dependencies was like attempting to catch a money-laundering operation. Unlike, say, the PHP applications I had worked on in the past, it was impossible to even begin to vet this many external vendors. Since they're all required, we were open to security issues from any of them.
Let's walk through how I attempted to fix the problem.
- Obviously started with the basics like
npm audit, which works but is a purely reactionary element. It relies on developers maintaining the package, reporting the issue, someone initially reporting the issue. In a Python world where I am using maybe 6 big common dependencies, that makes sense. However in NPM land when I have thousands, many of which are maintained by one person, this isn't practical - Fine, can we vet each package before we add it? Even assuming I had the technical ability to assess each package against some sort of "known-good" parameter, the scale of the task would require a thousand people working full-time. Look at the dependency graph for just NPM itself which, remember, is often called by the root user in many tutorials.
- Alright well that's an impossible task. Maybe we can at least mitigate the problem by sticking with packages that are scoped. At least then we know its from the right org and isn't the result of a typo. Turns almost almost none of the most-downloaded packages from NPM are scoped. React, lodash, express, the list goes on and on. You can see the top NPM packages here.
- Fine, is there a way I can tell if the NPM package at least requires 2FA to upload the thing? As far as I can tell, you cannot. Package maintainers can enforce 2FA, but I can't check to see if its there.
- Now NPM has actually taken some great steps here to ensure the package hasn't been tampered with through ECDSA which you can see here for an example: https://registry.npmjs.org/underscore/1.13.6 under the
"signatures": [{ "keyid": "SHA256:{{SHA256_PUBLIC_KEY}}", "sig": "a312b9c3cb4a1b693e8ebac5ee1ca9cc01f2661c14391917dcb111517f72370809..."section. - But I still have the same underlying issue. While I can verify that the person publishing the package signed it (which is great), I'm still importing thousands of them. Plus signing the package isn't required so while many of the big packages have it, many don't.
In Practice
What this means is Node apps start to "rot" at an extremely aggressive rate. While they're fast to write and get stood up, they require constant monitoring against security issues with dependency trees spanning thousands of packages. You also constantly run into nested dependency version conflicts (which NPM handles through nesting). In order to keep a Node application patched you need to be willing to override some package dependencies to get a secure version (however you don't know if the actual higher-level dependency will function with the new version or not).
Example of a common pattern in Node application dependencies
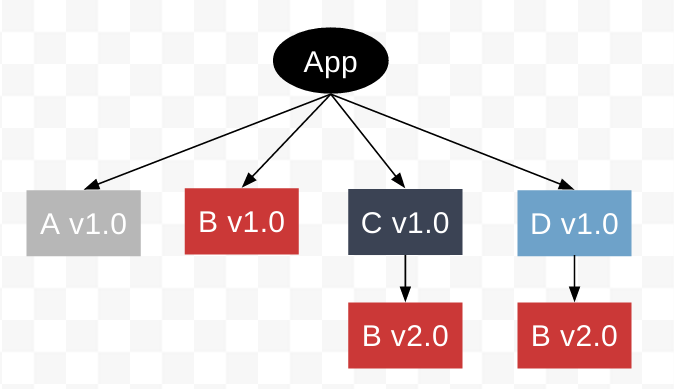
You are installing the same thing over and over with slightly different versions. You need to constantly monitor the entire dependency graph and check for declared issues, then hope against hope that everyone is checking everything for you on the internet and reporting like they should. Finally you need to hope that none of these maintainers get their stuff hijacked or simply give up.
Sustainable model of Node
I'm not sure what can be done now to fix this problem. I suspect a great option might be to force packages to "flatten" the dependency space, only allowing for top-level dependencies and not allowing for nested dependencies. However at this point the train has likely left the station.
If you are looking to write safe, long-term Node code, I think your only option is to be extremely aggressive about not allowing packages into your codebase and trying to use the Node Core Modules as outlined here as much as possible. I want to praise the NPM team for switching to a more sustainable signing system and hope it gains widespread adoption (which it seems on track to). Otherwise you basically need to hope and pray that nobody in the thousands of people you rely on decides to blow up your app today.
However in the desire to demonstrate how fast it is to start writing Node by using NPM, we have doomed Node by ensuring that long-term maintenance is nearly impossible. If you fix packages with known-security issues manually and tests starting failing, it can be a massive task to untangle the ball of yarn and figure out what specifically changed.
Conclusion
All of these technologies mostly deliver real, measurable value. They are often advancements over what came before. However organizations were often misled by tutorials and demos that didn't accurately portray the realities of running this technology, instead attempting to encourage adoption by presenting the most positive light possible. I don't blame enthusiasts for this, but I think as a field we should be more honest when showing new technology to peers.
As for the maintainers of these technologies, it ultimately hurts you and your reputation when you don't frontload the complexity into either the tooling or the documentation. I'm going to hit those sharp edges eventually, so why not prepare me for it from the beginning? If at some point I'm going to need to rewrite all of my containers, why not help me do it correctly from the start? If you know I'm going to need to constantly patch my NPM dependencies, maybe add a more robust chain of dependencies so I can audit what is coming in and from where.
Ultimately we help each other by being more honest. I want you to use my tool and get the maximum value out of it, even if the maximum value for you is not to use my tool.