DNS. The source of and solution to every problem.
I've worked in IT for my entire life in one capacity or another. Starting out as an "intern" for a local computer repair shop in my hometown, I developed strong opinions about many technologies. None of them have been as fundamental or as frustrating as DNS. I decided to take some time to do a series of posts on what DNS is, how it works and workarounds for common problems.
At a basis level DNS is the process of allowing humans to use easy to remember names like "google.com" while still allowing computers the ability to resolve specific IP addresses to send their requests. It also allows Google to change the IP address for google.com without having to run a global advertising campaign.
Why is DNS frustrating though?
DNS is frustrating because it works such a high percentage of the time. Like any system with a high track record of success, failures don't often come to mind when you are working in the system. If I'm troubleshooting why one system can't find a resource or speak to another (especially a third party system), my first inclination is to look inside the application stack, then the hosts networking and firewall, etc etc etc. In many ways this speaks to the reliability of DNS that it doesn't pop up in my mind.
However many experienced folks resist the urge to rely on DNS for mission-critical applications if at all possible. Some of this is the result of tribal thinking, where one experienced person dislikes relying on it and everyone follows. Some of it is a desire to simplify the troubleshooting scope if there is a problem. If a host can't reach an IP address I know where I need to start working. A lot of it is though that many people today don't have a super firm grasp on what DNS is doing or how to work with the tools it provides. Especially for younger DevOps folks its just not something they think about. Route 53 or other similar DNS providers are their DNS and other than that its best not to think about it too hard.
Ah /etc/hosts
Like any good story this one begins with a bit of a hack. It's the 70s and ARPAnet, or Internet Alpha, is a small community that likes to connect with each other. Much like today when someone doesn't want to manage DNS, they rely on a single text file of host names that is then turned into /etc/hosts. Much like modern times the burder of maintaining the single text file, in this case HOSTS.TXT became too much. People were constantly wanted to add or remove from it and it became a chore to ensure you had the latest copy. A more complicated system was required. Since these are engineers it'll likely be some sort of database.
It is a database!
DNS, or Domain Name System, is at its heart a distributed database. It has a structure which allows you to control the local pieces of that database while still allowing the worldwide distribution of all data. When we say DNS servers what we're talking about are nameservers. These servers hold the information for some part of the database and make that information available to the clients when asked. These clients, called resolvers, are relatively simple programs that create queries and send them to nameservers.
So what does DNS look like? Well if you've spend some time in the Linux filesystem it should look pretty familar to you. Here is the Linux directory structure.
Ok then here is the DNS database structure:
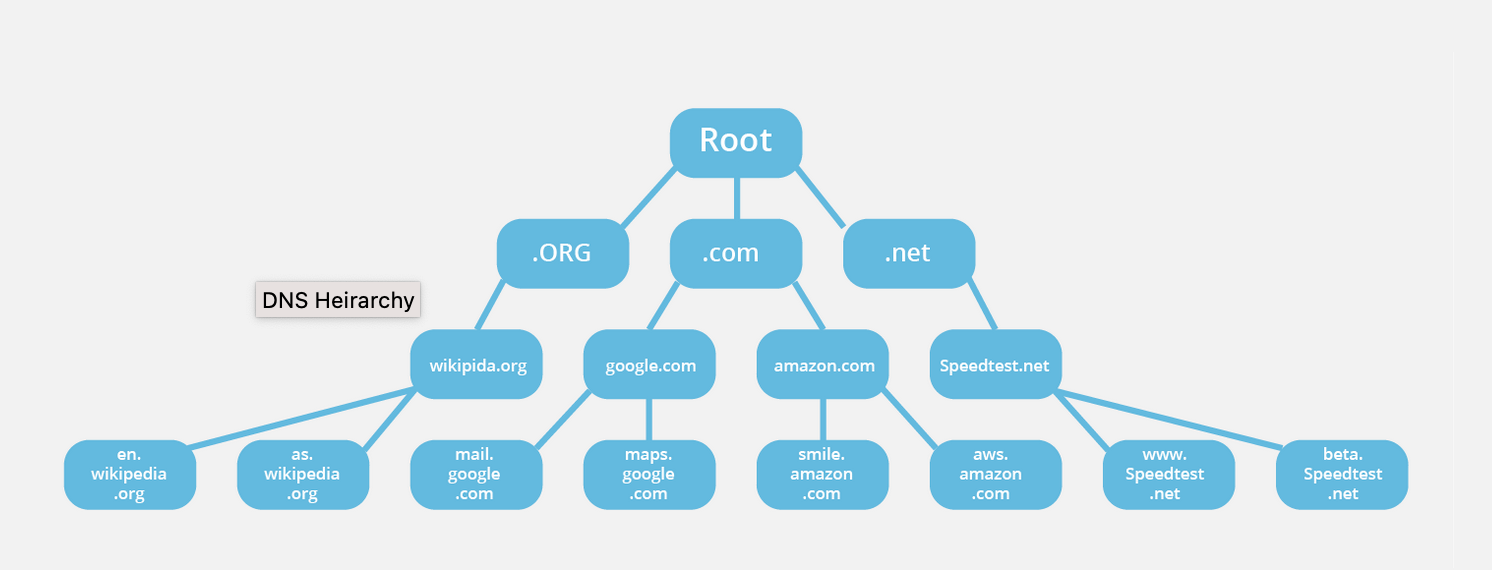
At the top is the root node or null node, shown as " " or in text as a single dot. We then break into the categories of names much like directories in Linux. Each domain name tells the DNS system where that domain name is in the database. So for instance, if I tell you to go to /var/log you read that and think "ok I'm going to start at / which is root, then go to var and inside of that I'll find log. With DNS its similar but in the opposite order. When you make a request to matduggan.com, the system is first reading that as "go to .com and then traverse from there". Much like larger file systems I have control over some parts but not others. For instance the root node is managed by ICANN (those folks who seem to keep coming up with bizarre TLDs or Top Level Domains like .genting). The .com directory is managed by Verisign (I know right? I had no idea). Finally I control the matduggan "zone" and it's managed by me. That means I can add subdomains at will. This system both prevents duplicates at the higher level while still giving me the freedom to do what I want at the lower level.
Apparently there is a level of depth to this directory structure of 127 which is pretty bonkers when you think about it. I'm not even sure how you'd get to 50.
Fun fact this is why when you are considering some DNS services you have to include a period at the end. So some software will require www.matduggan.com. since the . in this case is the root node. Domain names written in this manner are called fully qualified domain names.
So we've established that this is a database and you are accessing something. The something you are accessing is the resource records. There are different classes of records which tell you different things. We'll talk about all the records in their own post but for right now just mentally know the path ends at resource records.
Alright so we understand how a domain name works. But how does it work out practically that you control matduggan and not com. That has to do with zones. Nameservers generally have complete information about some part of the database structure, which we call a zone. That name server is then the authority for that zone. So how does that work in practice?
Starting again at www.matduggan.com. Verisign nameservers are the authority for .com and are responsible for keeping track of all the zones. In this scenario matduggan is its own zone and inside of that zone can be different zones for things like awesome.matduggan and terrible.matduggan. However if you don't have any subdomains you can just mentally think to yourself that your zone and your domain name are the same thing for now.
Nameservers
Now a bit more nuts and bolts time. The servers running this whole system are nameservers and there are two kinds. We have primary master nameservers and secondary master nameservers. A primary master nameserver for a zone has the information for that zone on a local file. The secondary master nameserver gets its zone data from the other host. You can also nest secondaries as needed.
Despite the naming both servers are authoritative for that zone. It's designed to make administration easier so you can worry about managing the one primary box and let the rest automatically update off of that nameserver. The local file the primary master nameserver is reading is the zone datafiles or just datafiles. (Which is a ridiculous name since all files have data but I guess we're going to let that go). Datafiles for secondary nameservers are generated and then used if the master can't be reached.
Resolvers
So we've got our nameservers. In this scenario I have my zone, matduggan. It's being managed by 10.20.30.40 as a primary master and 10.20.30.41 which is the secondary master. Requests are successfully flowing to each of these. But the thing actually making these requests are the resolvers. These are the clients that send the requests to our nameservers.
Resolvers have three jobs:
- Query the nameserver
- Interpreting responses (either errors or records)
- Giving the information back to the program that asked for it
With BIND (we'll talk about BIND later but its the most common DNS service) the resolver isn't even a process running all the time. It's just a set of shared libraries that programs use to put together a query, send it, wait and then resend if it doesn't work. All the complex stuff is usually happening on the server. We call these simple resolvers stub resolvers.
Getting you the answer you want
Let's say I try to ssh into test.aws.com. The request is send to 10.20.30.40 as my local DNS server. Now my nameserver isn't the authoritative nameserver for aws.com. That'll likely be an Amazon server. My name server is going to go through a process called resolution to get me the information I need as a client. It starts with a request to the root nameservers we talked about before. So in this case 10.20.30.40 goes out and hits the root nameserver (assuming it has never done any requests before since these are mostly cached) and from there is told to go to the com nameserver. The com nameserver responds and tells my server to go to the aws server. This whole time my resolver is just sitting quietly waiting because all it understands, as a stub resolver, is either "here is the record you wanted or that record doesn't exist sorry". This type of resolution query is called a recursive query where the nameserver is basically going through the whole database structure and the client is doing nothing.
There's another design though. Some clients send an iterative query. This means 10.20.30.40 would respond not with the definite answer (unless it had that answer in a cache) but with the best possible information it has. The client then hits that new DNS server that is received what we call a referral to. Basically my DNS server was like "I don't know the answer but I know this server is closer to the answer, go ask them". The client does and is told "well yes I am closer but really you want to talk to THIS server". In this way the client walks the directory structure of DNS as opposed to my DNS server.
Alright so you understand now that the way the nameserver finds the answer depends a lot on how the question is asked by the client. But how does the nameserver decide where to start asking the question? There is not one root server but 13 distinct addresses. BIND, the software running on our nameserver picks the one it is going to use with a metric called roundtrip time or RTT. This works for nameservers of all kinds. It gets a list of nameservers at first, assigns a random low RTT time, starts sending queries and measures the time. By keeping track of which took the least time to respond it now knows which servers to send requests to in the future.
Wait though, this process has to work both ways right? Like if I hit an IP address looking for a domain name I should be able to look it up. How does that work?
Databases all the way down
Let's say we're talking about our test.aws.com box we're trying to SSH into. The address for this box is 12.13.120.180. There is a domain in DNS called the in-addr.arpa domain that keeps track of all IP addresses for us. Now with the IP address since we want to follow the same "least specific to most specific pattern" reading like a normal IP address isn't going to work. Instead you reverse the order. So when the IP 12.13.120.180 is read in a domain name its actually seen as 180.120.13.12 since that lets us efficiently go through the in-addr.arpa structure. This allows us to do the same authority delegation we do with domain names. So in our example AT&T is the authoritive nameserver for the 12 block, but let's say it doesn't control the last octet and that is controlled by a different name server. I can still effectively look up that information with the same process that let me look up the domain name.
This seems really slow
Doesn't it? Well thankfully DNS servers don't need to do this whole process very often. Every time our nameserver goes out into the internet we learn a lot about the world around us and we cache it locally. This saves us a ton of time in the future. Nameservers cache both successful results and unsuccessful results so the amount of traffic flying around is kept as low as possible.
These caches don't live forever though because otherwise a lot of the dynamic updating of the internet would break. Every zone gets to decide how long the data about their zone should last. This is called the TTL or time to live. Set a short one and you'll get more traffic to your nameservers, but less delay when you implement changes. Longer one, less traffic but more delay. Like all things there are tradeoffs.
That's the basics!
There you have it folks. The basics of DNS lookups. In the next post I'll discuss BIND, how to set it up, what the different options means, etc.