Until recently the LLM tools I’ve tried have been, to be frank, worthless. Copilot was best at writing extremely verbose comments. Gemini would turn a 200 line script into a 700 line collection of gibberish. It was easy for me to, more or less, ignore LLMs for being the same over-hyped nonsense as the Metaverse and NFTs.
This is great for me because I understand that LLMs represent a massive shift in power from an already weakened worker class to an increasingly monarch-level wealthy class. By stealing all human knowledge and paying nothing for it, then selling the output of that knowledge, LLMs are an impossibly unethical tool. So if the energy wasting tool of the tech executive class is also a terrible tool, easy choice.
Like boycotting Tesla for being owned by an evil person and also being crappy overpriced cars, or not shopping at Hobby Lobby and just buying directly from their Chinese suppliers, the best boycotts are ones where you aren’t really losing much. Google can continue to choke out independent websites with their AI results that aren’t very good and I get to feel superior doing what I was going to do anyway by not using Google search.
This logic was all super straight forward right up until I tried Claude Code. Then it all got much more complicated.
Some Harsh Truths
Let’s just get this out of the way right off the bat. I didn't want to like Claude Code. I got a subscription with the purpose of writing a review on it where I would find that it was just as terrible as Gemini and Copilot. Except that's not what happened.
Instead it was like discovering the 2AM kebab place might actually make the best pizza in town. I kept asking Claude to do annoying tasks where it was easy for me to tell if it had made a mistake and it kept doing them correctly. It felt impossible but the proof was right in front of me.
I’ve written tens of thousands of lines of Terraform in my life. It is a miserable chore to endlessly flip back and forth between the provider documentation and Vim, adding all the required parameters. I don’t learn anything by doing it, it’s just a grind I have to push through to get back to the meaningful work.
The amount of time I have wasted on this precious time on Earth importing all of a companies DNS records into Terraform, then taking the autogenerated names and organizing them so that they make sense for the business is difficult to express. It's like if the only way I knew how to make a hamburger bun was to carefully put every sesame seed by hand on the top only to stumble upon an 8 pack of buns for $4 at the grocery store after years of using tiny tweezers to put the seeds in exactly the right spot.
I feel the same way about writing robust READMEs, k8s YAML and reorganizing the file structure of projects. Setting up more GitHub Actions is as much fun as doing my taxes. If I never had to write another regex for the rest of my life, that would be a better life by every conceivable measure.
These are tasks that sap my enthusiasm for this type of work, not feed it. I’m not sad to offload them and switch to mostly reviewing its PRs.
But the tool being useful doesn’t remove what’s bad about it. This is where a lot of pro-LLM people start to delude themselves.
Pro-LLM Arguments
In no particular order are the arguments I keep seeing about LLMs from people who want to keep using them for why their use is fine.
IP/Copyright Isn’t Real
This is the most common one I see and the worst. It can be condensed down to “because most things on the internet originally existed to find pornography and/or pirate movies, stealing all content on the internet is actually fine because programmers don’t care about copyright”.
You also can’t have it both ways. OpenAI can’t decide to enforce NDAs and trademarks and then also declare law is meaningless. If I don’t get to launch a webmail service named Gmail+ then Google doesn’t get to steal all the books in human existence.
The argument basically boils down to: because we all pirated music in 2004, intellectual property is a fiction when it stands in the way of technology. By this logic I shoplifted a Snickers bar when I was 12 so property rights don't exist and I should be allowed to live in your house.
Code Quality Doesn't Matter (According to Someone Who Might Be Right)
I have an internet friend I met years ago playing EVE Online that is a brutally pragmatic person. To someone like him, code craftsmanship is a joke. For those of you who are unaware, EVE Online is the spaceship videogame where sociopaths spend months plotting against each other.
His approach to development is 80% refining requirements and getting feedback. He doesn’t care at all about DRY, he uses Node because then he can focus on just JavaScript, he doesn’t invest a second into optimization until the application hits a hard wall that absolutely requires it. His biggest source of clients? Creating fast full stacks because internal teams are missing deadlines. And he is booked up for at least 12 months out all the time because he hits deadlines.
When he started freelancing I thought he was crazy. Who was going to hire this band of Eastern European programmers who chain smoke during calls and whose motto is basically "we never miss a deadline". As it turns out, a lot of people.
Why doesn't he care?
Why doesn't he care about these things? He believes that programmers fundamentally don't understand the business they are in. "Code is perishable" is something he says a lot and he means it. Most of the things we all associate with quality (full test coverage, dependency management, etc) are programmers not understanding the rate of churn a project undergoes over its lifespan. The job of a programmer, according to him, is delivering features that people will use. How pleasant and well-organized that code is to work with is not really a thing that matters in the long term.
He doesn't see LLM-generated code as a problem because he's not building software with a vision that it will still be used in 10 years. Most of the stuff typically associated with quality he, more or less, throws in the trash. He built a pretty large stack for a automotive company and my jaw must have hit the table when he revealed they're deploying m6g.4xlarge for a NodeJS full-stack application. "That seems large to me for that type of application" was my response.
He was like "yeah but all I care about are whether the user metrics show high success rate and high performance for the clients". It's $7000 a year for the servers, with two behind a load balancer. That's absolutely nothing when compared with the costs of what having a team of engineers tune it would cost and it means he can run laps around the internal teams who are, basically, his greatest competition.
To be clear, he is very technically competent. He simply rejects a lot of the conventional wisdom out there about what one has to do in order to make stuff. He focuses on features, then securing endpoints and more or less gives up on the rest of it. For someone like this, LLMs are a logical choice for him.
Why This Argument Doesn't Work for Me
The annoying thing about my friend is that his bank account suggests he's right. But I can't get there. If I'm writing a simple script or something as a one-off, it can sometimes feel like we're all wasting the companies time when we have a long back and forth on the PR discussing comments or the linting or whatever. So it's not that this idea is entirely wrong.
But the problem with programming is you never know what is going to be "the core" of your work life for the next 5 years. Sometimes I write a feature, we push it out, it explodes in popularity and then I'm a little bit in trouble because I built a MVP and now it's a load-bearing revenue generating thing that has to be retooled.
I also just have trouble with the idea that this is my career and the thing I spend my limited time on earth doing and the quality of it doesn't matter. I delight in craftsmanship when I encounter it in almost any discipline. I love it when you walk into an old house and see all the hand crafted details everywhere that don't make economic sense but still look beautiful. I adore when someone has carefully selected the perfect font to match something.
Every programmer has that library or tool that they aspire to. That code base where you delight at looking at it because it proves perfection is possible even if you have never come close to reaching that level. For me its always been looking through the source code of SQLite that restores my confidence. I might not know what I'm doing but it's good to be reminded that someone out there does.
Not everything I make is that great, but the concept of "well great doesn't matter at all" effectively boils down to "don't take pride in your work" which is probably the better economic argument but feels super bad to me. In a world full of cheap crap, it feels bad to make more of it and then stick my name on it.
So Why Are People Still Using Them?
The best argument for why programmers should be using LLMs is because it's going to be increasingly difficult to compete for jobs and promotions against people who are using them. In my experience Claude Code allows me to do two tasks at once. That's a pretty hard advantage to overcome.
Last Tuesday I had Claude Code write a GitHub Action for me while I worked on something else. When it was done, I reviewed it, approved it, and merged it. It was fine. It was better than fine, actually — it was exactly what I would have written, minus the forty-five minutes of resentment. I sat there for a moment, staring at the merged PR, feeling the way I imagine people feel when they hire a cleaning service for the first time: relieved, and then immediately guilty about the relief, and then annoyed at myself for feeling guilty about something that is, by any rational measure, a completely reasonable thing to do. Except it isn't reasonable. Or maybe it is. I genuinely don't know anymore, and that's the part that bothers me the most — not that the tool works, but that I've lost the clean certainty that it shouldn't.
So now I'm paying $20 a month to a company that scraped the collective knowledge of humanity without asking so that I can avoid writing Kubernetes YAML. I know what that makes me. I just haven't figured out a word for it yet that I can live with.
When I asked my EVE friend about it on a recent TeamSpeak session, he was quiet for awhile. I thought that maybe my moral dilemma had shocked him into silence. Then he said, "You know what the difference is between you and me? I know I'm a mercenary. You thought you were an artist. We're both guys who type for money."
I couldn't think of a clever response to that. I still can't.
The impact of Large Language Models (LLMs) on the field of software development is arguably one of the most debated topics in developer circles today, sparking discussions at meetups, in lunchrooms, and even during casual chats among friends. I won't attempt to settle that debate definitively in this post, largely because I lack the foresight required. My track record for predicting the long-term success or failure of new technologies is, frankly, about as accurate as a coin flip. In fact, if I personally dislike a technology, it seems destined to become an industry standard.
However, I do believe I'm well-positioned to weigh in on a much more specific question: Is GitHub Copilot beneficial for me within my primary work environment, Vim? I've used Vim extensively as my main development tool for well over a decade, spending roughly 4-5 hours in it daily, depending on my meeting schedule. My work within Vim involves a variety of technologies, including significant amounts of Python, Golang, Terraform, and YAML. Therefore, while I can't provide a universal answer to whether an LLM is right for you, I can offer concrete opinions based on my direct experience with GitHub Copilot as a dedicated Vim user today.
Testing
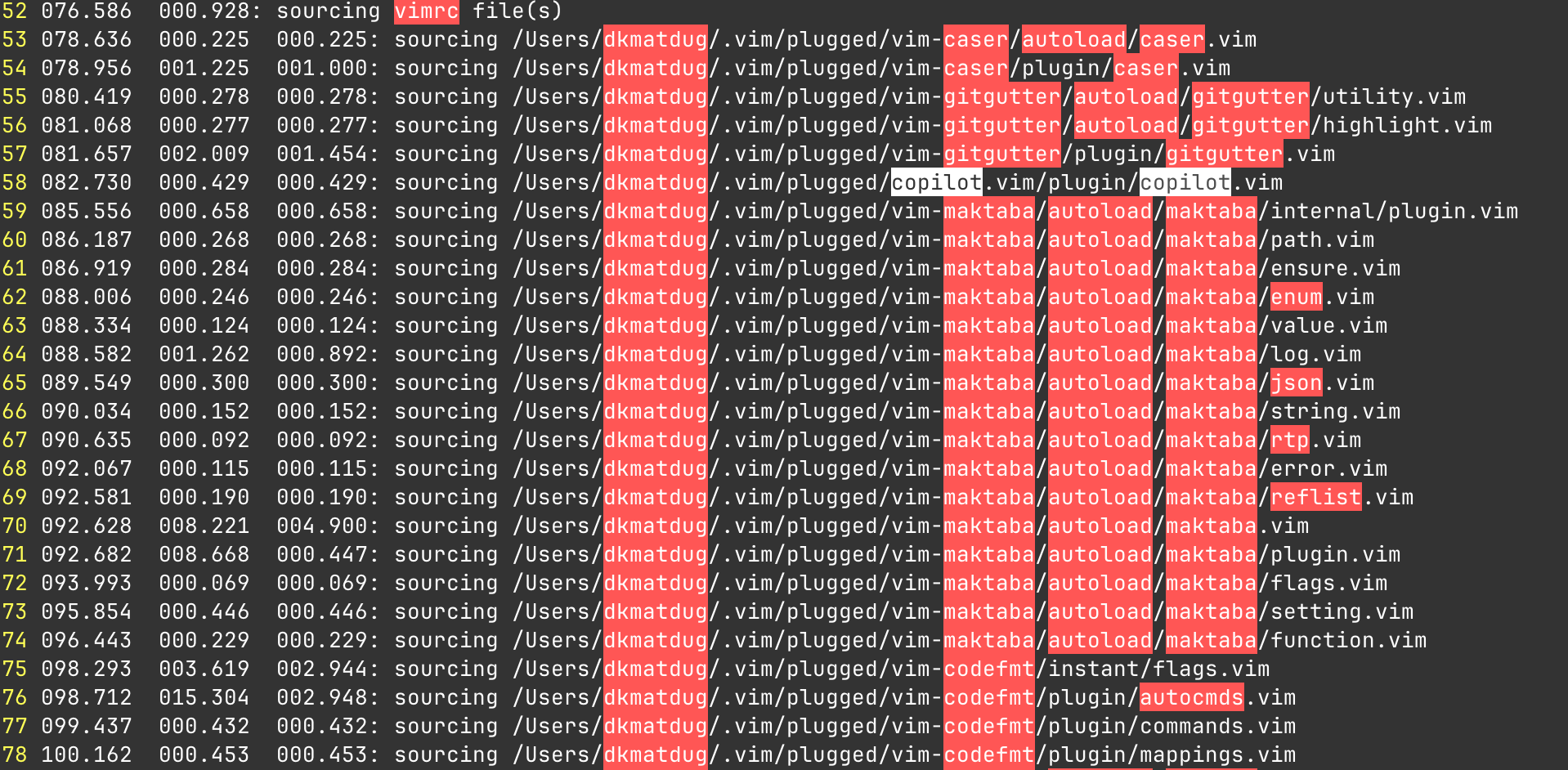
So just to prove I really set it up:
It's a real test, I've been using it every day for this time period. I have it set up in what I believe to be the "default configuration".
The plugin uses Vimscript to capture the current state of the editor. That includes stuff like:
The entire content of the current buffer (the file being edited).
The current cursor position within the buffer.
The file type or programming language of the current buffer.
The Node.js language server receives the request from the Vim/Neovim plugin. It processes the provided context and constructs a request to the actual GitHub Copilot API running on GitHub's servers. This request includes the code context and other relevant information needed by the Copilot AI model to generate suggestions.
The plugin receives the suggestions from the language server. It then integrates these suggestions into the Vim or Neovim interface, typically displaying them as "ghost text" inline with the user's code or in a separate completion window, depending on the plugin's configuration and the editor's capabilities.
How it feels to use
As you can tell from the output of vim --startuptime vim.log the plugin is actually pretty performant and doesn't add a notable time to my initial launch.
In terms of the normal usage, it works like it says on the box. You start typing and it shows the next line it thinks you might be writing.
The suggestions don't do much on their own. Basically the tool isn't smart enough to even keep track of what it has already suggested. So in this case I've just tab completed and taken all the suggestions and you can tell it immediately gets stuck in a loop.
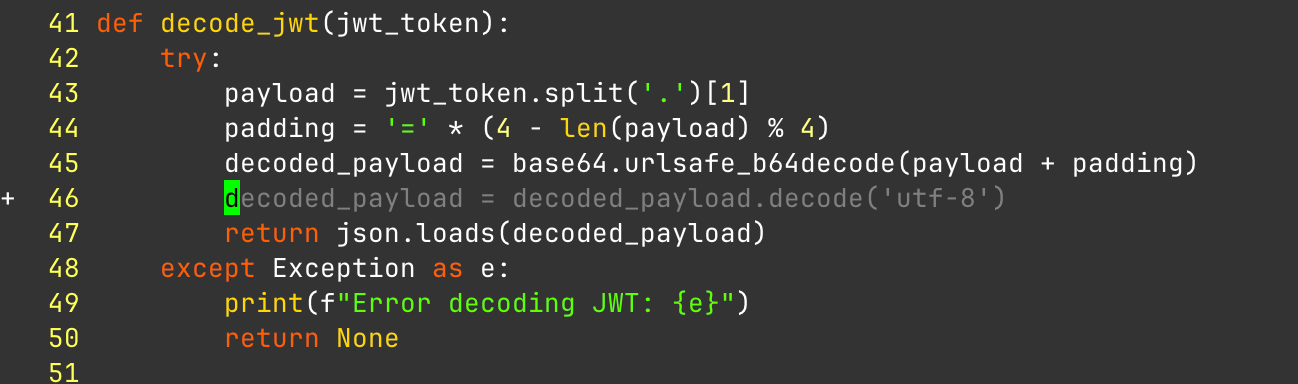
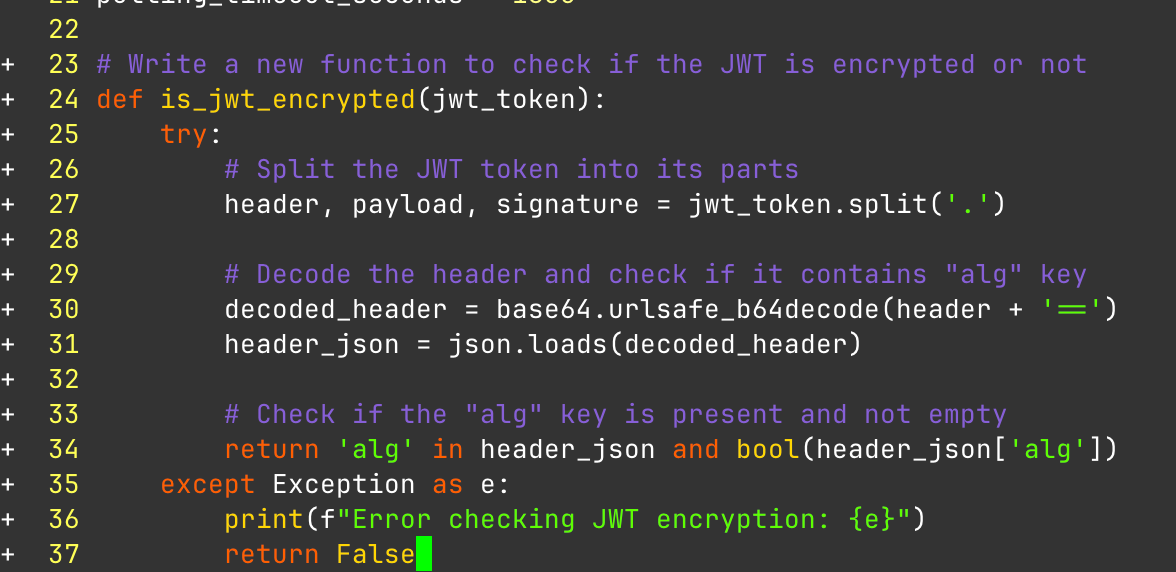
Now you can use it to "vibe code" inside of Vim. That works by writing a comment describing what you want to do and then just tab accepting the whole block of code. So for example I wrote Write a new function to check if the JWT is encrypted or not. It produced the following.
So I made a somewhat misleading comment on purpose. I was trying to get it to write a function to see if a JWT was actually a JWE. Now this python code is (obviously) wrong. The code is_jwt_encrypted assumes the token will always have exactly three parts separated by dots (header, payload, signature). This is the structure of a standard JSON Web Token (JWT). However, a JSON Web Encryption (JWE), which is what a wrapped encrypted JWT is, has five parts:
Protected Header
Encrypted Key
Initialization Vector
Ciphertext
Authentication Tag
So this gives you a rough idea of the quality of the code snippets it produces. If you are writing something dead simple, the autogenerate will often work and can save you time. However go even a little bit off the golden path and, while Copilot will always give it a shot, the quality is all over the place.
Scores Based on Common Tasks
Reviewing a product like this is extremely hard because it does everything all the time and changes daily with no notice. I've had weeks where it seems like the Copilot intelligence gets cranked way up and weeks where its completely brain dead. However I will go through some common tasks I have to do all the time and rank it on how well it does.
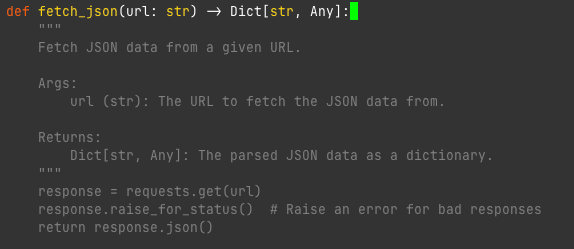
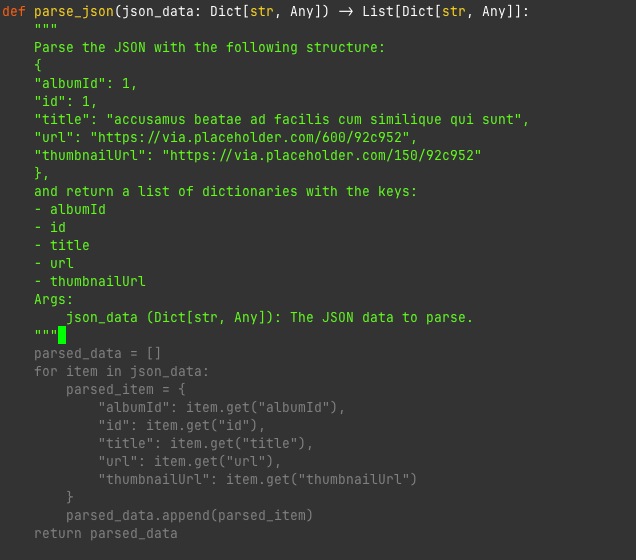
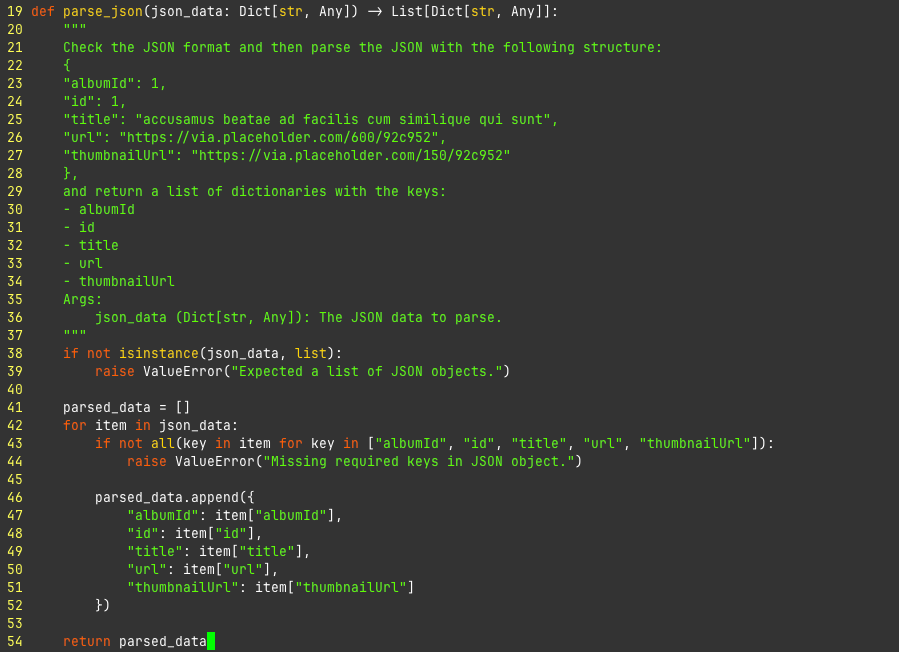
Parsing JSON
90/100
This is probably the thing Copilot is best at. You have a JSON that you are getting from some API and then Copilot helps you fill in the parsing for that so you don't need to type the whole thing out. So just by filling in my imports it already has a good idea of what I'm thinking about here.
So in this example I write the comment with the example JSON object and then it fills in the rest. This code is....ok. However I'd like it to probably check the json_data to see if it matches the expectation before it parses. Changing the comment however changes the code.
This is very useful for me as someone who often needs to consume JSONs from source A and then send JSONs on to target B. Saves a lot of time and I think the quality looks totally acceptable to me. Some notes though:
Python Types greatly improve the quality of the suggestions
You need to check to make sure it doesn't truncate the list. Sometimes Copilot will "give up" like 80% through writing out all the items. It doesn't often make up ones, which is nice, but you do need to make sure everything you expected to be there ends up getting listed.
Database Operations
40/100
I work a lot with databases, like everyone on Earth does. Copilot definitely understands the concepts of databases but your experience can vary wildly depending on what you write and the mood it is in.
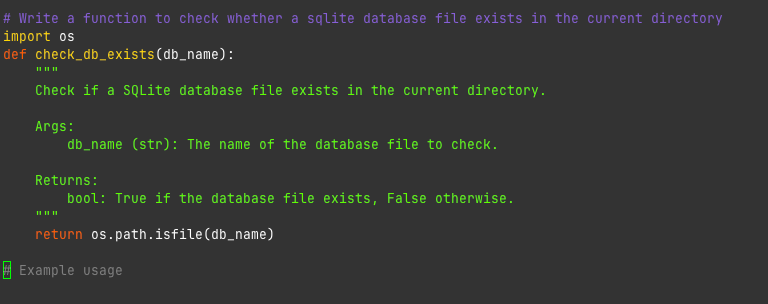
I mean this is sort of borderline making fun of me. Obviously I don't want to just check if the file named that exists?
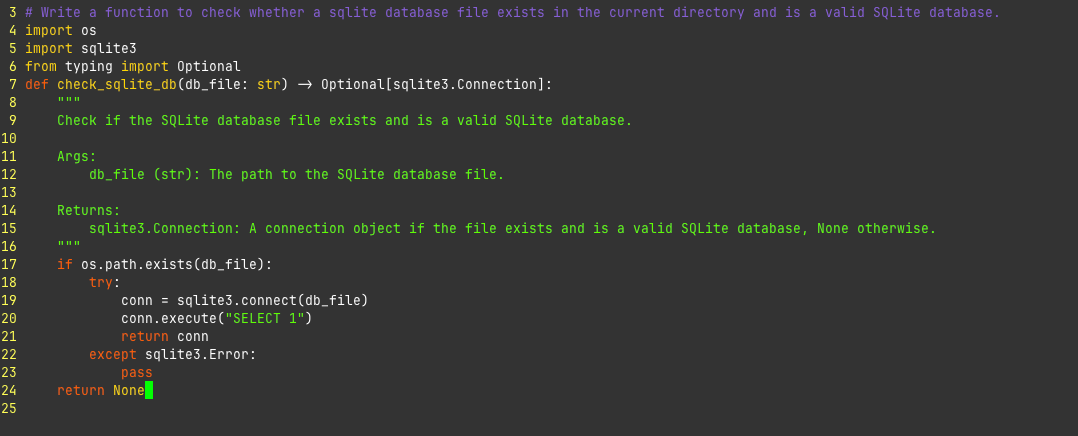
This is better but it's still not good. If there is a file sitting there with the right name that isn't a database, sqlite3.connect will just make it. The except sqlite3.Error part is super shitty. Obviously that's not what I want to do. I probably want to at least log something?
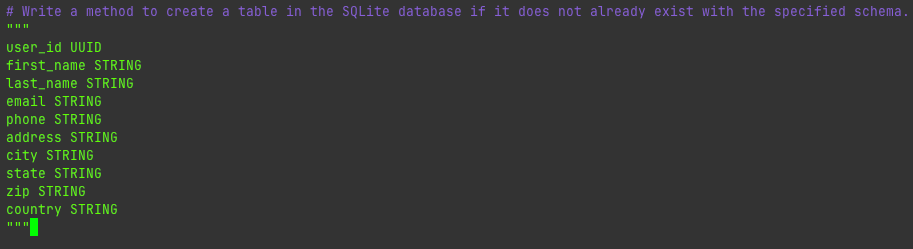
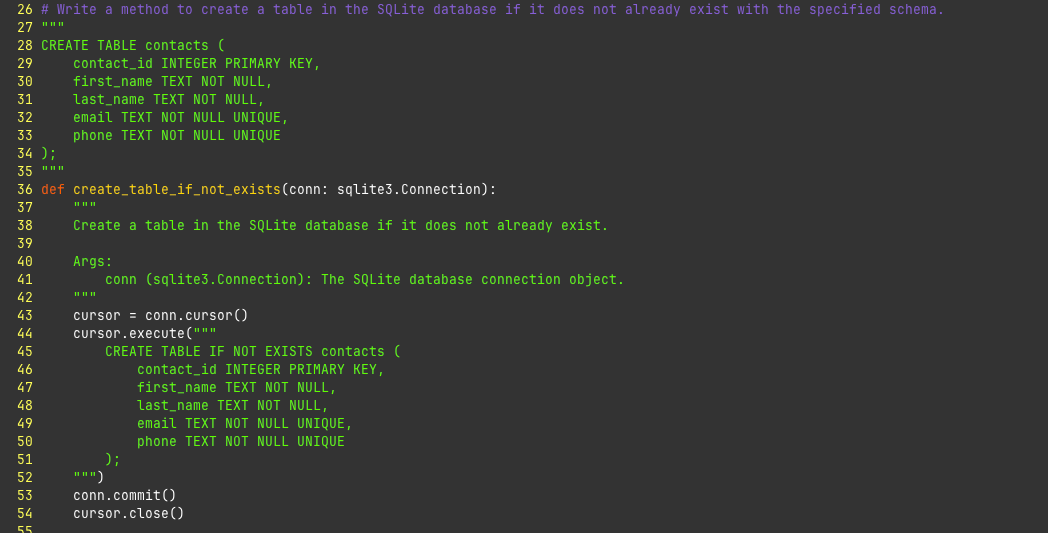
Let me show another example. I wrote Write a method to create a table in the SQLite database if it does not already exist with the specified schema. Then I typed user_ID UUID and let it fill in the rest.
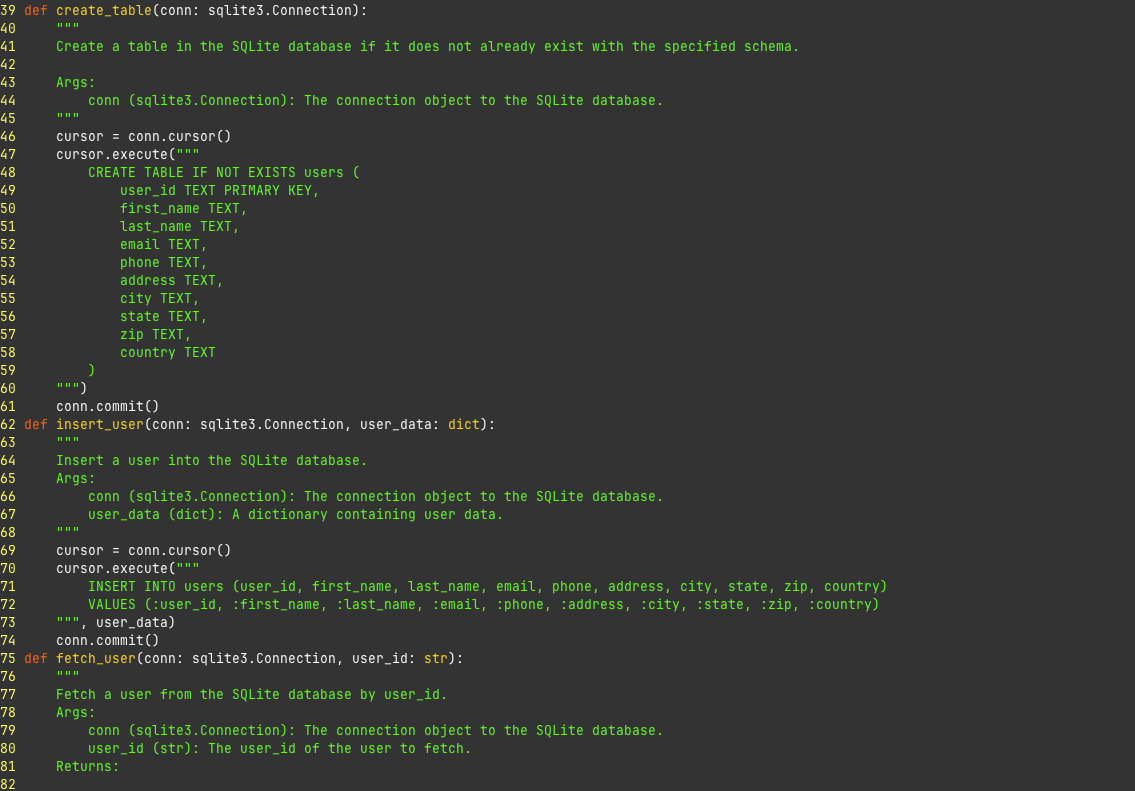
Not great. What it ended up making was even worse.
We're missing error handling, no try/finally blocks with the connection cursor, etc. This is pretty shitty code. My experience is it doesn't get much better the more you use. Some tips:
If you write out the SQL in the comments then you will have a way better time.
CREATE TABLE users (
contact_id INTEGER PRIMARY KEY,
first_name TEXT NOT NULL,
last_name TEXT NOT NULL,
email TEXT NOT NULL UNIQUE,
phone TEXT NOT NULL UNIQUE
);
Just that alone seems to make it a lot happier.
Still not amazing but at least closer to correct.
Writing Terraform
70/100
Not much to report with Terraform.
So why the 70/100? I've had a lot of frustrations with Copilot hallucinations with Terraform where it will simply insert arguments that don't exist. I can't reliably reproduce it, but this is something that can really burn a lot of time when you hit it.
My advice with Terraform is to run something like terrascan after which will often catch weird stuff it inserts. https://github.com/tenable/terrascan
However I will admit it saves me a lot of time, especially when writing stuff that is mind-numbing like 1000 DNS entries. So easily worth the risk on this one.
Tips:
Make sure you use the let g:copilot_workspace_folders = ['/path/to/my/project1', '/path/to/another/project2']
That seems to ground the LLM with the rest of the code and allows it to detect things like "what is the cloud account you are using".
Writing Golang
0/100
This is a good summary of my experience with Copilot with Golang.
I don't know why. It will work fine for awhile and then at some point, roughly when the golang file hits around 300-400 lines, seems to just lose it. Maybe there's another plugin I have that's causing a problem with Copilot and Golang, maybe I'm holding it wrong, I have no idea.
There's nothing in the logs I can find that would explain why it seems to break on Golang. I'm not going to file a bug report because I don't consider this my job to fix.
Summary
Is Copilot worth $10 a month? I think that really depends on what your day looks like. If you are someone who is:
Writing microservices where the total LoC rarely exceeds 1000 per microservice
Spends a lot of your time consuming and producing JSONs for other services to receive
Are capable of checking SQL queries and confirming how they need to be fixed
Has good or great test coverage
Then I think this tool might be worth the money. However if your day looks like this:
Spends most of your day inside of a monolith or large codebase carefully adding new features or slightly modifying old features
Doesn't have any or good test coverage
Doesn't have a good database migration strategy.
I'd say stay far away from Copilot for Vim. It's going to end up causing you serious problems that are going to be hard to catch.
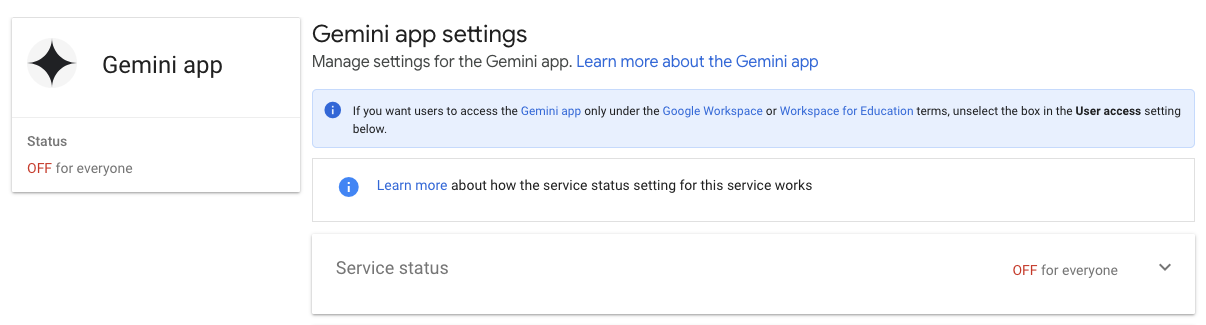
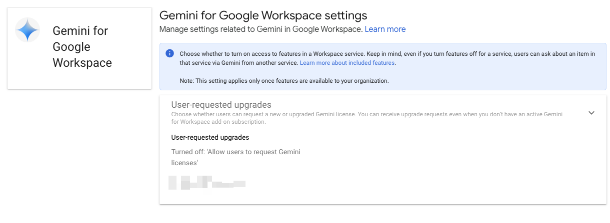
Last week I awoke to Google deciding I hadn't had enough AI shoved down my throat. With no warning they decided to take the previously $20/user/month Gemini add-on and make it "free" and on by default. If that wasn't bad enough, they also decided to remove my ability as an admin to turn it off. Despite me hitting all the Off buttons I could find:
Users were still seeing giant Gemini chat windows, advertisements and harassment to try out Gemini.
This situation is especially frustrating because we had already evaluated Gemini. I sat through sales calls, read the documentation, and tested it extensively. Our conclusion? It’s a bad service, inferior to everything on the market including free LLMs. Yet, now, to disable Gemini, I’m left with two unappealing options:
upgrade my account to the next tier up and pay Google more money for less AI garbage.
Beg customer service to turn it off, after enduring misleading responses from several Google sources who claimed it wasn’t possible.
Taking how I feel about AI out of the equation, this is one of the most desperate and pathetic things I've ever seen a company do. Nobody was willing to pay you for your AI so, after wasting billions making it, you decide to force enable it and raise the overall price of Google Workspaces, a platform companies cannot easily migrate off of. Suddenly we've repriced AI from $20/user/month to "we hope this will help smooth over us raising the price by $2/user/month".
Plus, we know that Google knew I wouldn't like this because they didn't tell me they were going to do it. They didn't update their docs when they did it, meaning all my help documentation searching was pointless because they kept pointing me to when Gemini was a per-user subscription, not a UI nightmare that they decided to force everyone to use. Like a bad cook at a dinner party trying to sneak their burned appetizers onto my place, Google clearly understood I didn't want their garbage and decided what I wanted didn't matter.
If it were just Google, I might dismiss this as the result of having a particularly lackluster AI product. But it’s not just Google. Microsoft and Apple seem equally desperate to find anyone who wants these AI features.
Google’s not the only company walking back its AI up-charge: Microsoft announced in November that its own Copilot Pro AI features, which had also previously been a $20 monthly upgrade, would become part of the standard Microsoft 365 subscription. So far, that’s only for the Personal and Family subscriptions, and only in a few places. But these companies all understand that this is their moment to teach people new ways to use their products and win new customers in the process. They’re betting that the cost of rolling out all these AI features to everyone will be worth it in the long run. Source
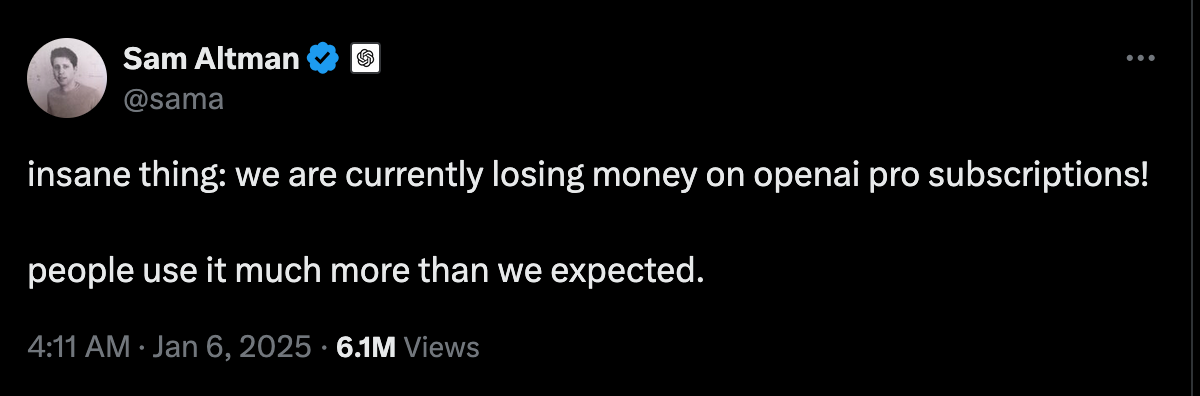
Despite billions in funding, stealing the output of all humans from all time and being free for consumers to try, not enough users are sufficiently impressed that they are going to work and asking for the premium package. If that isn't bad enough, it also seems that these services are extremely expensive to offer, with even OpenAI's $200 a month Pro subscription losing money.
Watch The Bubble Burst
None of this should be taken to mean "LLMs serve no purpose". LLMs are real tools and they can serve a useful function, in very specific applications. It just doesn't seem like those applications matter enough to normal people to actually pay anyone for them.
Given the enormous cost of building and maintaining these systems, companies were faced with a choice. Apple took its foot off the LLM gas pedal with the following changes in the iOS beta.
When you enable notification summaries, iOS 18.3 will make it clearer that the feature – like all Apple Intelligence features – is a beta.
You can now disable notification summaries for an app directly from the Lock Screen or Notification Center by swiping, tapping “Options,” then choosing the “Turn Off Summaries” option.
On the Lock Screen, notification summaries now use italicized text to better distinguish them from normal notifications.
In the Settings app, Apple now warns users that notification summaries “may contain errors.”
Additionally, notification summaries have been temporarily disabled entirely for the News & Entertainment category of apps. Notification summaries will be re-enabled for this category with a future software update as Apple continues to refine the experience.
This is smart, it wasn't working that well and the very public failures are a bad look for any tech company. Microsoft has decided to go pretty much the exact opposite direction and reorganize their entire developer-centric division around AI. Ironically the Amazon Echo teams seems more interested in accuracy than Apple and have committed to getting hallucinations as close to zero as possible. Source
High level though, AI is starting to look a lot like executive vanity. A desperate desire to show investors that your company isn't behind the curve of innovation and, once you have committed financially, doing real reputational harm to some core products in order to be convincing. I never imagined a world where Google would act so irresponsibly with some of the crown jewels of their portfolio of products, but as we saw with Search, they're no longer interested in what users want, even paying users.
Recently Mozilla announced the first of what will presumably be a number of LLM-powered tools designed to assist them with advancing a future with "trustworthy AI". You can read their whole thing here. This first stab at the concept is a browser extension called "Orbit". It's a smart, limited risk approach to AI, unlike what Apple did which was serve everyone raw cake and tell you it's cooked with Apple Intelligence. Or Google destroying their search results, previously the "crown jewels" of the company.
Personally I'm not a huge fan of LLMs. I don't really think there is something like a "trustworthy LLM". But I think this is an interesting approach by Mozilla setting up what seems like a very isolated from their core infrastructure LLM appliance running Mistral LLM (Mistral 7B).
Going through this file, it seems to be mostly doing what you would expect a "background.js" file does. I was originally thrown off by the chrome. thing until I saw that this is a convention for the WebExtensions API and many WebExtensions APIs in Firefox use the chrome.* namespace for compatibility with Chrome extensions, even though they also support the browser.* namespace as an alias.
Sentry: I'm surprised a Mozilla add-on uses Sentry. However it does have a _sentryDebugIdIdentifier.
Event listeners: The code sets up event listeners for various WebExtensions API events:
chrome.runtime.onConnect: Listens for incoming connections from the background script.
chrome.runtime.onMessage: Listens for messages from the browser.
chrome.runtime.onInstalled: Listens for installation and update events.
chrome.contextMenus: Listens for context menu clicks.
chrome.tabs: Listens for tab updates and removals.
Background script: The code creates a background script that listens for incoming messages from the browser and executes various tasks, including:
Handling popup initialization.
Updating the "isEnabled" setting when the extension is installed or updated.
Creating new tabs with a welcome page URL (or an onboarding page).
Aborting video playback when the tab is removed.
Context menu items: The code creates two context menu items: "Summarize selection with Orbit" and "Summarize page with Orbit". These items trigger messages to be sent to the browser, which are then handled by the background script.
Server Elements
So it looks like Mozilla has a server set up to run the LLM powering Orbit.
De = function (t, e) {
return fetch("https://orbitbymozilla.com/v1/orbit/prompt/stream", { method: "POST", headers: { "Content-Type": "application/json" }, body: JSON.stringify({ prompt: t, chat_token: e }) });
},
$e = function (t, e) {
return fetch("https://orbitbymozilla.com/v1/orbit/chat_history/reinstate_session", { method: "POST", headers: { "Content-Type": "application/json", Authorization: e }, body: JSON.stringify({ token: t.sessionToken }) });
},
Me = function (t) {
return fetch("https://orbitbymozilla.com/v1/orbit/chat_history/clear_session", { method: "POST", headers: { "Content-Type": "application/json" }, body: JSON.stringify({ token: t }) });
},
Re = function (t, e, n) {
return fetch("https://orbitbymozilla.com/v1/orbit/chat_history/update_context_history", {
method: "POST",
headers: { "Content-Type": "application/json", Authorization: e },
body: JSON.stringify({ prev_resp: t, token: n }),
});
},
Ge = function (t, e) {
return fetch("https://orbitbymozilla.com/v1/orbit/chat_history/index", { method: "POST", headers: { "Content-Type": "application/json", Authorization: e }, body: JSON.stringify({ page: t }) });
},
Ue = function (t, e, n, r, o, i, a, s) {
return fetch("https://orbitbymozilla.com/v1/orbit/prompt/update", {
method: "POST",
headers: { "X-Orbit-Version": chrome.runtime.getManifest().version, "Content-Type": "application/json", Authorization: a },
body: JSON.stringify({ prompt: t, ai_context: o, context: e, title: n, chat_token: i, type: s, icon_url: r }),
});
},
ze = function (t, e, n) {
return fetch("https://orbitbymozilla.com/v1/orbit/prompt/store_result", { method: "POST", headers: { "Content-Type": "application/json", Authorization: n }, body: JSON.stringify({ ai_context: t, chat_token: e }) });
},
Fe = function (t) {
return fetch("https://orbitbymozilla.com/v1/users/show", { method: "GET", mode: "cors", headers: { "Content-Type": "application/json", Authorization: t } });
},
qe = function (t, e) {
return fetch("https://orbitbymozilla.com/v1/users/sign_in", { method: "POST", mode: "cors", headers: { "Content-Type": "application/json" }, body: JSON.stringify({ user: { email: t, password: e } }) });
},
He = function (t, e) {
return fetch("https://orbitbymozilla.com/v1/users", { method: "POST", headers: { "Content-Type": "application/json" }, body: JSON.stringify({ user: { email: t, password: e } }) });
},
Ye = function (t) {
return fetch("https://orbitbymozilla.com/v1/users/provider_auth", { method: "POST", headers: { "Content-Type": "application/json" }, body: JSON.stringify({ provider_name: "google", token: t }) });
},
We = function (t) {
return fetch("https://orbitbymozilla.com/v1/users/sign_out", { method: "DELETE", headers: { "Content-Type": "application/json", Authorization: t } });
},
Be = function (t) {
return fetch(t, { method: "GET", headers: { Host: "docs.google.com", origin: "https://docs.google.com", Accept: "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8" } });
},
Je = function (t) {
return fetch("https://orbitbymozilla.com/v1/orbit/feedback", { method: "POST", headers: { "Content-Type": "application/json" }, body: JSON.stringify(t) });
},
Ke = function (t, e) {
return fetch("".concat("https://orbitbymozilla.com/", "v1/orbit/chat_history/").concat(t), { method: "DELETE", headers: { "Content-Type": "application/json", Authorization: e } });
},
Ve = function (t) {
return fetch("".concat("https://orbitbymozilla.com/", "v1/orbit/chat_history/delete_all"), { method: "DELETE", headers: { "Content-Type": "application/json", Authorization: t } });
};
function Xe(t) {
return (
(Xe =
"function" == typeof Symbol && "symbol" == typeof Symbol.iterator
? function (t) {
return typeof t;
}
: function (t) {
return t && "function" == typeof Symbol && t.constructor === Symbol && t !== Symbol.prototype ? "symbol" : typeof t;
}),
Xe(t)
);
}
Nothing too shocking here. I don't fully understand what the Google Docs is doing there.
content.js
This is where Orbit gets initialized. The code sets up several event listeners to handle incoming messages from the browser's runtime API
This code sets up event listeners for several message types, including "startup", "updatedUrl", and "responseStream". The chrome.runtime.onMessage function is used to listen for incoming messages from the browser's runtime API.
Slightly Mysterious Stuff
So multiple times in the code you see reference to gmail, youtube, outlook specifically. It seems that this plugin is geared towards providing summaries on those specific websites. Not to say that it won't attempt it on other sites, but those are the ones where it is hardcoded to work. The google.json is as follows:
This selector targets div elements that have an attribute called jsaction with a value that starts with CyXzrf: and ends with .CLIENT. This suggests that the plugin is trying to select elements that contain a specific JavaScript action.
This selector targets two types of elements: * Elements with an attribute called data-thread-perm-id that has a value starting with thread-f. * Elements with an attribute called data-thread-perm-id that has a value starting with thread-a.
The double quotes around the selectors indicate that they are using the CSS attribute selector syntax, which allows selecting elements based on their attributes.
This selector targets two types of elements: * Elements with a class called h7 that have an attribute called role with a value containing the substring "listitem". * Elements with a class called kv that have an attribute called role with a value containing the substring "listitem".
Weirdly the outlook.json and the youtube.json are both empty. I'm guessing for YouTube it grabs the text transcript and ships that off to the server. I don't see any reference to Outlook in the JS code, so I'm not clear how that works.
Orbit Network Traffic
So going into about:debugging#/runtime/this-firefox I grabbed the Network Inspector for this plugin.
Running a summary on a random Ars Technica article looked like this:
Inspecting the requests, it looks like this is how it works.
'Here is a page: Skip to content Story text * Subscribers only Learn more As many of us celebrated the year-end holidays, a small group of researchers worked overtime tracking a startling discovery: At least 33 browser extensions hosted in Google’s Chrome Web Store, some for as long as 18 months, were surreptitiously siphoning sensitive data from roughly 2.6 million devices.The compromises came to light with the discovery by data loss prevention service Cyberhaven that a Chrome extension used by 400,000 of …Worlds 10 Most Breathtakingly Beautiful Women.OMGIFactsUndoShe Was Everyones Dream Girl In 90s, This Is Her Recently.InvestructorUndoShe Was Everyones Dream Girl In 90s, This Is Her RecentlyBoite A ScoopUndo20 Classic Cars That Remain In High Demand For a ReasonChillingHistory.comUndo2024 Latest Stair Lifts: Ideal for Elderly, No Installation NeededStair Lift | Search AdsUndoCopenhagen - StairLift Elevators Could Be A Dream Come True For SeniorsStair Lift | Search AdUndo Search dialog... Sign in dialog...'
The response is clearly a reference for the plugin to wait and grab the result later: "orbit_message_store:488b357b-20cc-408d-a55e-bfa5219b102f_e057453954543a1733eaaa2996904b81d0fa3cef6fe15efeccdfe644228173f0"
Then we POST to https://prod.orbit-ml-front-api.fakespot.prod.webservices.mozgcp.net/invoke
This service clearly generates the "suggested questions" in the plugin as seen in the response.
" Question 1: Which Chrome extensions were found to have surreptitiously collected sensitive data from users' devices, and how many users were affected?\n\nQuestion 2: How did the attackers exploit the Google OAuth permission system to upload malicious versions of the Chrome extensions to the Chrome Web Store?\n\nQuestion 3: What types of sensitive data were stolen by the malicious Chrome extensions, and which websites' authentication credentials were targeted?\n\nQuestion 4: What steps should organizations take to manage and secure the use of browser extensions in their security programs?\n\nQuestion 5: What is the potential impact on users who ran one of the compromised Chrome extensions, and what actions should they take to protect themselves?"
Finally we run a GET to prod.orbit-ml-front-api.fakespot.prod.webservices.mozgcp.net which seems to get the actual summary.
" At least 33 malicious Chrome extensions, some of which had been available in Google's Chrome Web Store for up to 18 months, were discovered to have been stealing sensitive data from approximately 2.6 million devices. The compromises came to light when a Chrome extension used by 400,000 of Cyberhaven's customers was found to have been updated with malicious code. The malicious version, available for 31 hours between Christmas Day and Boxing Day, automatically downloaded and installed on Chrome browsers running Cyberhaven during that window. The attacker gained access to the extension by sending a spear phishing email to the developers, posing as Google and warning that the extension would be revoked unless immediate action was taken. The attacker then used the granted permission to upload the malicious version. Other extensions were also targeted using the same method, with at least 19 identified as of Thursday afternoon. The earliest known compromise occurred in May 2023."
I'm a little confused by this. I thought the summary wasn't stored server-side as explained by this:
Does Orbit save the content of the pages I visit or summaries generated?
No, it does not.
When you use Orbit, we receive a payload back that contains the contents of your query; information about the model queried (such as the name and version number); information about technical problems with processing the query, if any; the number of tokens required to process the query; and the model outputs in response to the query. We do not store this data beyond temporarily caching it to process your query and return the outputs to you.
Orbit summaries are only available on the page that you are actually on. As soon as you navigate away from that page, Orbit erases the session.
I'm not exactly clear how this can be true if it seems like I'm sending the summary back to Mozilla to an endpoint called store_result. They do say they "temporarily cache" the results so I guess they are covered in terms of how it works. It doesn't appear to me like an endpoint called store_result is a temporary storage endpoint, but who knows.
Does it work well?
So now that I've checked the extension and installed it, agreeing to this somewhat alarming permission screen:
It gives me a strange....hovering black hole icon?
When you click on the hovering black hole you get the following options:
You can do the following:
Ask Orbit, which is asking the plugin about anything on the specific page you are on.
Settings.
I strongly recommend "Minimal" to get rid of the large Bonzi Buddy type floating icon on the screen.
At least 33 malicious Chrome extensions, some of which had been available in Google's Chrome Web Store for up to 18 months, were discovered to have been stealing sensitive data from approximately 2.6 million devices. The compromises came to light when a Chrome extension used by 400,000 of Cyberhaven's customers was found to have been updated with malicious code. The malicious version, available for 31 hours between Christmas Day and Boxing Day, automatically downloaded and installed on Chrome browsers running Cyberhaven during that window. The attacker gained access to the extension by sending a spear phishing email to the developers, posing as Google and warning that the extension would be revoked unless immediate action was taken. The attacker then used the granted permission to upload the malicious version. Other extensions were also targeted using the same method, with at least 19 identified as of Thursday afternoon. The earliest known compromise occurred in May 2023.
Switching the settings to have it produce "paragraphs" resulted in a much more robust answer.
At least 33 malicious Chrome extensions, some of which had been available in Google's Chrome Web Store for up to 18 months, were discovered to have been stealing sensitive data from approximately 2.6 million devices. The compromises came to light when data loss prevention service Cyberhaven discovered that their own extension, used by 400,000 of its customers, had been updated with malicious code that stole their sensitive data. The malicious version was available for just 31 hours, from December 25 at 1:32 AM UTC to Dec 26 at 2:50 AM UTC, and automatically downloaded and installed on Chrome browsers running Cyberhaven during that window. The malicious code was configured to work with different payloads that were downloaded from cyberhavenext.pro, a malicious site registered to give the appearance it was affiliated with the company. One recovered payload scoured user devices for browser cookies and authentication credentials for the facebook.com domain, while another stole cookies and credentials for chatgpt.com. The attacker gained access to the Cyberhaven extension by sending a spear phishing email to the developers on Christmas Eve, warning that the extension wasn't in compliance with Google terms and would be revoked unless immediate action was taken. The email contained a link to a Google consent screen requesting access permission for an OAuth application named Privacy Policy Extension. A Cyberhaven developer granted the permission, unknowingly giving the attacker the ability to upload new versions of Cyberhaven's Chrome extension to the Chrome Web Store. Other extensions were also targeted using the same spear phishing campaign, with at least 19 other Chrome extensions compromised as of Thursday afternoon. In every case, the attacker used spear phishing to push a new malicious version and custom, look-alike domains to issue payloads and receive authentication credentials. Collectively, the 20 extensions had 1.46 million downloads. The earliest compromise occurred in May 2023. The full list of affected extensions and their details is provided in the article. Browser extensions have long been a weak link in the security chain, with malicious extensions stealing sensitive data from 4 million devices in 2019, including those of companies like Tesla, Blue Origin, FireEye, Symantec, TMobile, and Reddit. To mitigate the risk of malicious extensions, organizations can compile a browser asset management list that allows only selected extensions to run and blocks all others. However, this would not have prevented the Cyberhaven customers from installing the malicious extension version unless a specific version was trusted and all others were blocked. Anyone who ran one of these compromised extensions is advised to carefully consider changing their passwords and other authentication credentials. Additional indicators of compromise can be found in the article and other posts.
The suggested questions are as follows:
According to the text, at least 33 Chrome extensions were found to have surreptitiously collected sensitive data from roughly 2.6 million devices. Some of the affected extensions include Cyberhaven, Uvoice, Internxt VPN, and Castorus. The malicious code was pushed out through a spear phishing campaign that targeted the developers of these extensions.
That's the answer to the first one. Since the article has a list of impacted extensions I would have expected it to return the full list of extensions.
The attackers exploited the Google OAuth permission system by tricking a Cyberhaven developer into granting them permission to upload new versions of the Chrome extension to the Chrome Web Store. They did this by sending a spear phishing email on Christmas Eve, posing as a Google representative and warning that the extension would be revoked unless immediate action was taken. The link in the email led to a Google consent screen, where the developer unknowingly granted the attacker the ability to upload new versions.
Second answer is a little bit stronger.
OpenAI Comparison
A recent investigation has uncovered that at least 33 malicious Chrome extensions, collectively installed on approximately 2.6 million devices, have been covertly extracting sensitive user data.
Key Findings: • Discovery and Impact: The issue came to light when Cyberhaven, a data loss prevention service, found that a Chrome extension used by 400,000 of its customers had been compromised. The malicious version was available for 31 hours between December 25 and 26, during which it harvested sensitive information from users’ devices. • Method of Compromise: Attackers employed spear-phishing emails targeting extension developers, tricking them into granting permissions that allowed the attackers to upload malicious versions of legitimate extensions to the Chrome Web Store. These versions were configured to download additional payloads from domains mimicking legitimate services, enabling the theft of browser cookies and authentication credentials. • Scope of Affected Extensions: Beyond Cyberhaven’s extension, at least 19 other Chrome extensions were similarly compromised through this method, affecting a total of 1.46 million users. The attackers used custom, look-alike domains to distribute payloads and collect stolen credentials.
Recommendations for Users: • Review Installed Extensions: Users should audit their browser extensions and remove any that are unnecessary or unfamiliar. • Stay Informed: Regularly check for updates from trusted sources regarding compromised extensions to ensure your browser remains secure. • Be Cautious with Permissions: Before installing extensions, scrutinize the permissions they request and be wary of granting access that seems excessive for the extension’s functionality.
This incident underscores the importance of vigilance when managing browser extensions, as they can become vectors for significant security breaches if compromised.
Review: Honestly they're both pretty bad. The first summary is missing a lot of relatively critical information. The second summary has most of that information, but is so long you might as well read the original source material. OpenAI decides it doesn't want to even read the article and sorta goes off on its own there.
I was hoping the plain web style would help the plugin, but it seemed to have trouble right away. I suspect the comments section threw it off.
This one was a complete failure.
provider of plugins for a CMS that has a 62% market share. That's not quite accurate. Automattic is the provider of the official plugin repository for WordPress, which is the most popular CMS. However, there are other plugin repositories and marketplaces, such as GitHub, where plugins can be distributed and installed directly. The issue here is that Automattic has taken actions to prevent WP Engine from distributing plugins through the official repository, which WP Engine argues is damaging their business. WP Engine is seeking an injunction to restore their access to the repository. The court has found that WP Engine is likely to succeed on the merits of their claim for tortious interference with contractual relations, as they have demonstrated that Automattic intentionally interfered with their contractual relationship with their customers by blocking their access to the repository. The court has also found that WP Engine is likely to suffer irreparable harm if the injunction is not granted, as they will continue to lose customers and revenue. However, it's important to note that this is just a preliminary injunction, and it does not necessarily mean that WP Engine will ultimately prevail in the case. The trial has not yet begun, and there will be further proceedings where both sides will present their evidence and arguments. Legal jargon is significant.
Samsung has announced the release of The Frame Pro, an upgraded version of its popular TV that aims to deliver both aesthetics and improved performance. The Frame Pro features Mini LED technology, which promises enhanced contrast, brightness, and black levels, although it does not offer the same level of local dimming as traditional Mini LED TVs. Additionally, the maximum refresh rate has been boosted to 144Hz for smoother visuals for PC gamers. However, Dolby Vision support is still not available. The Frame Pro also eliminates the need for a wire between the TV and Samsung's breakout box, resulting in less cable clutter. The TV is expected to ship in the spring, with pricing details yet to be announced.
The Frame Pro TV by Samsung introduces two major improvements compared to the regular model. First, it uses Mini LED technology along the bottom of the screen, which Samsung claims produces some level of local dimming. Second, it offers a higher maximum refresh rate of 144Hz for smoother visuals for PC gamers.
The Frame Pro by Samsung utilizes Mini LEDs placed along the bottom of the screen, which Samsung claims still produces some level of local dimming. However, this approach seems more similar to edge-lit TVs as it doesn't involve the large number of small dimming zones typically found in traditional Mini LED TVs.
This is fine. I think it's missing a few important things from the article. First it doesn't really convey any of the skepticism of the author.
The Frame has always been something of a compromise; maybe you’ve got a significant other who refuses to allow a dull black rectangle into the living room. So you, being the good and considerate person you are, ultimately agree to “settle” on The Frame. After first hearing about The Frame Pro, I was hopeful that it would be much less of a compromise.
But this asterisk around Mini LED has me a little less excited. Like recent models, The Frame Pro’s display has a matte finish to give your preferred art a more authentic appearance and mask the reality that you’re looking at a screen. But matte screens can sometimes lessen a display’s punch, so genuine Mini LED backlighting could’ve helped quite a bit in that regard.
It's also a pretty bare-boned summary. Here is the OpenAI comparison:
Samsung has announced The Frame Pro, an enhanced version of its popular TV model, The Frame, which combines home decor aesthetics with television functionality. 
Key Features of The Frame Pro: • Mini LED Technology: The Frame Pro transitions to Mini LED technology, aiming to improve contrast, brightness, and black levels. Unlike traditional Mini LED setups with backlighting, Samsung places the Mini LEDs along the bottom of the screen, which may still result in an edge-lit TV feel.  • Increased Refresh Rate: The maximum refresh rate is boosted from 120Hz to 144Hz, appealing to PC gamers seeking smoother visuals.  • Wireless One Connect Box: The wired connection to the breakout box is eliminated, replaced by the Wireless One Connect Box supporting Wi-Fi 7. This box can function from up to 10 meters away, reducing cable clutter and enhancing the TV’s seamless integration into home decor.  • AI-Powered Features: The Frame Pro includes AI-driven functionalities such as “Click to Search,” which provides information about actors, scenes, or clothing displayed on-screen; “Samsung Food,” recognizing dishes onscreen and offering recipes; and “Live Translate,” instantly translating closed captions on live broadcasts in up to seven languages. 
Design Considerations: • Matte Finish Display: The TV maintains a matte finish to give displayed art a more authentic appearance, aligning with its design ethos of blending seamlessly into home decor. 
Availability and Pricing: • Samsung plans to announce pricing details in the spring, coinciding with the product’s shipment schedule. The cost will be a significant factor in determining The Frame Pro’s appeal compared to the regular model. 
The Frame Pro aims to enhance the balance between aesthetic appeal and advanced television functionality, building upon the success of its predecessor by introducing technological upgrades and user-friendly features. 
This is still missing some of the subtext from the author about why the product is good or bad, but it does provide much more detail.
Review: Meh, it's pretty ok? I guess if you are really pressed for time. It seems to be missing a lot of important context about what this product is and what people might have wanted from it.
Last Test: email
I have my email on Fastmail, so we'll see how it does there. Here is the email.
At the heart of conservation are people like you — individuals who bring unique strengths to sustain and grow this vital work. This year, we’ve shared stories of the incredible women and communities driving change on the ground, and your support has been an integral part of those stories and our mission. Thanks to your generosity, Akashinga achieved remarkable milestones in 2024:
• Expanded our reach into key conservation areas, such as the Kunene Highlands in Namibia, safeguarding even more critical habitats. • Trained over 70 new female rangers, equipping them to protect wildlife and support their communities. • Protected 13 million acres of wilderness, ensuring a safe haven for countless species. • Grew our global workforce to over 900 individuals, with 98% of staff being local and/or indigenous to the countries they are working in. • Advanced community healthcare and infrastructure by implementing mobile health clinics and initiating additional solar-powered borehole projects within local communities. Every dollar you gave directly strengthened conservation efforts and empowered communities across Southern and East Africa. Your commitment doesn’t just fund our mission — it makes you part of the Akashinga family, united in protecting our planet and fostering sustainability.
Thank you for being a vital voice in the Akashinga story.
Here is the summary:
Mathew received an email from Akashinga acknowledging his support in 2024, which significantly contributed to their conservation efforts. Akashinga expanded their reach into new areas, trained new female rangers, protected 13 million acres of wilderness, and grew their global workforce. Mathew's donation also funded community healthcare and infrastructure projects. Akashinga expressed gratitude for his commitment and considered him part of their family. The email was a thank you note and update on their achievements in 2024.
Review: I mean again like it's not wrong, it's just such a short summary. It seems to be missing a lot of important information. I'm not clear why the tool doesn't give me a bit more info even when I have "paragraphs" selected.
Conclusion
I get what Mozilla is going for here, but frankly this is a miss. I'm not really clear what it is doing with my summaries of websites, but it feels like they're storing them in a cache so they don't need to redo the summary every time. Outside of privacy, the summary is just too short to provide almost any useful information.
If you are someone who is drowning in websites and emails and just needs a super fast extremely high level overview of their content, give it a shot. It works pretty well for that and you can't beat the price. But if you are looking for a more nuanced understanding of articles and emails where you can ask meaningful follow-up questions and get answers, keep looking. This isn't there yet, although since most of the magic seems to be happening in their server, I guess there's nothing stopping them from improving the results over time.
I was recently invited to try out the beta for GitHub's new AI-driven web IDE and figured it could be an interesting time to dip my toes into AI. So far I've avoided all of the AI tooling, trying the GitHub paid Copilot option and being frankly underwhelmed. It made more work for me than it saved. However this is free for me to try and I figured "hey why not".
Disclaimer: I am not and have never been an employee of GitHub, Microsoft, any company owned by Microsoft, etc. They don't care about me and likely aren't aware of my existence. Nobody from GitHub PR asked me to do this and probably won't like what I have to say anyway.
TL;DR
GitHub Copilot Workspace didn't work on a super simple task regardless of how easy I made the task. I wouldn't use something like this for free, much less pay for it. It sort of failed in every way it could at every step.
What is GitHub Copilot Workspace?
So after the success of GitHub Copilot, which seems successful according to them:
In 2022, we launched GitHub Copilot as an autocomplete pair programmer in the editor, boosting developer productivity by up to 55%. Copilot is now the most widely adopted AI developer tool. In 2023, we released GitHub Copilot Chat—unlocking the power of natural language in coding, debugging, and testing—allowing developers to converse with their code in real time.
They have expanded on this feature set with GitHub Copilot Workspace, a combination of an AI tool with an online IDE....sorta. It's all powered by GPT-4 so my understanding is this is the best LLM money can buy. The workflow of the tool is strange and takes a little bit of explanation to convey what it is doing.
Very simple, makes sense, Then I click "Open in Workspaces" which brings me to a kind of GitHub Actions inspired flow.
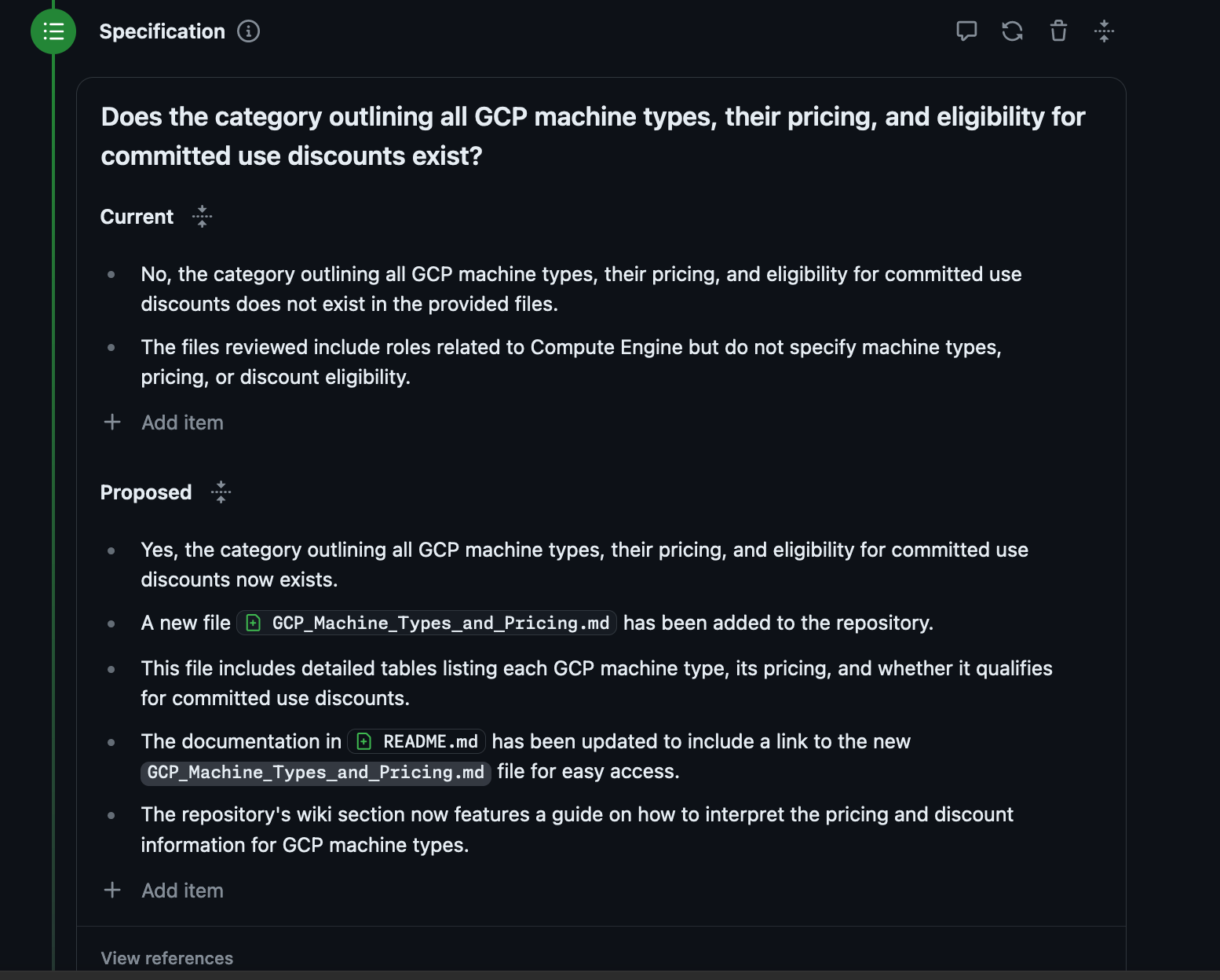
It reads the Issue and creates a Specification, which is editable.
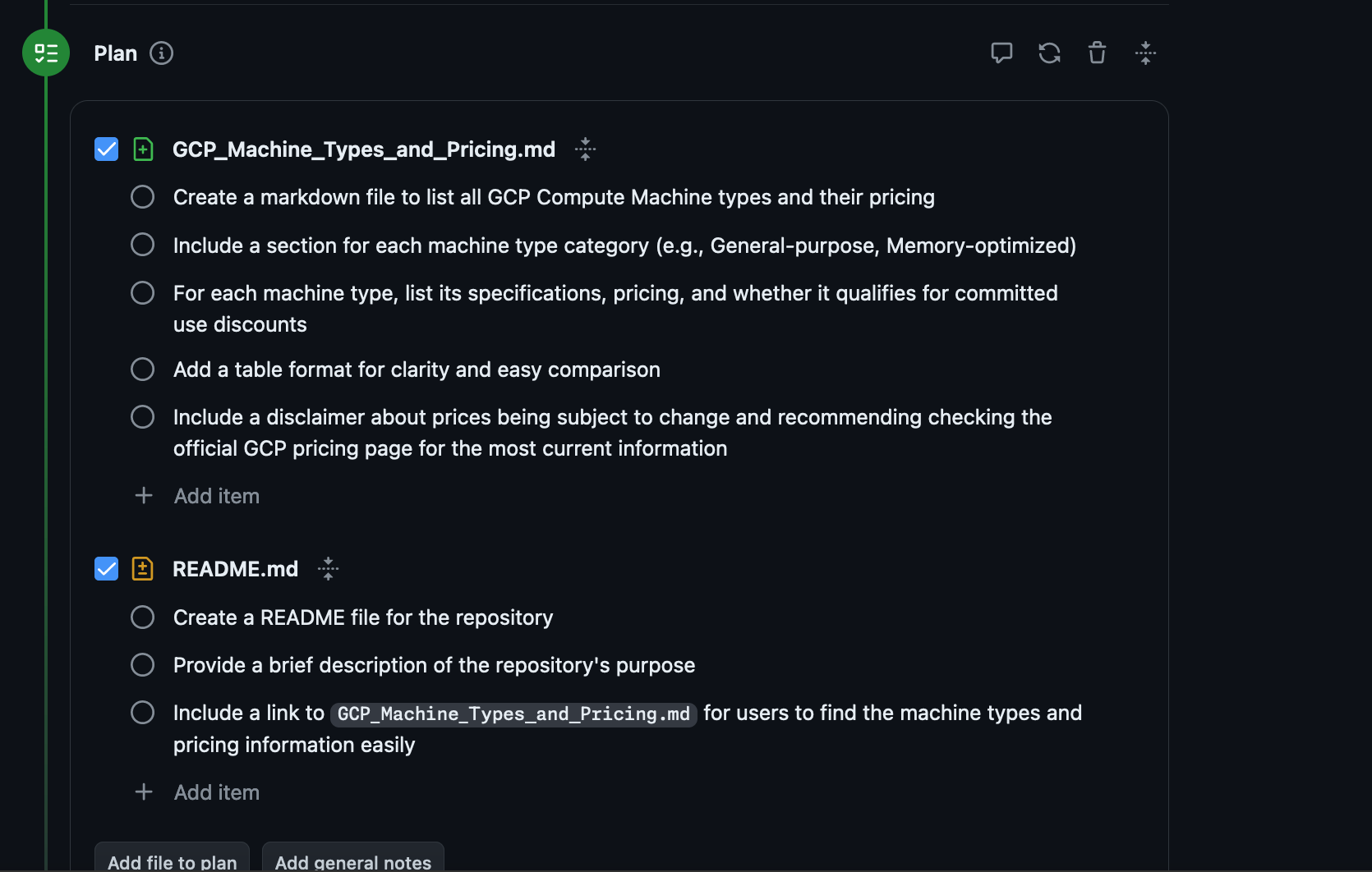
Then you generate a Plan:
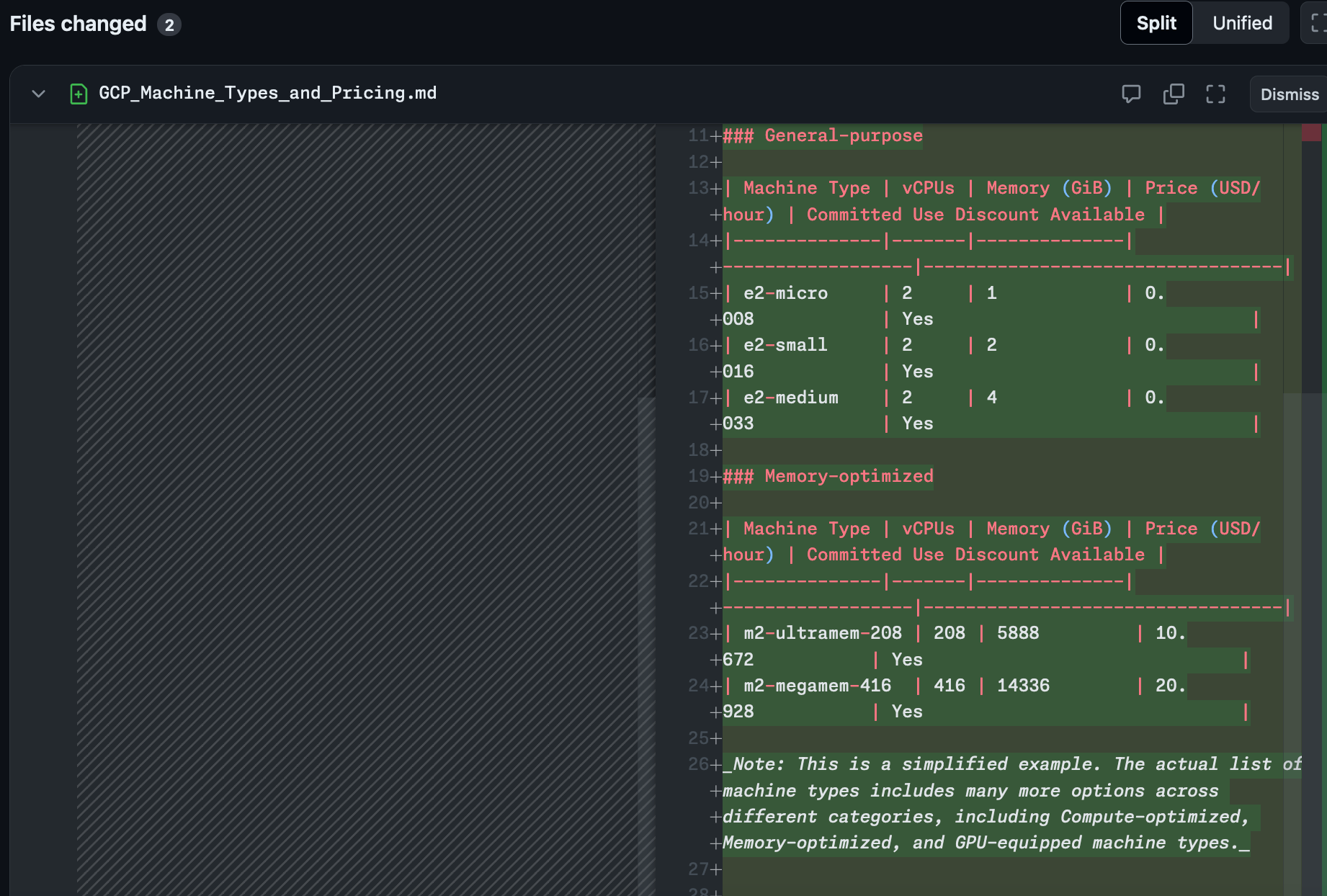
Finally it generates the files of that plan and you can choose whether to implement them or not and open a Pull Request against the main branch.
Implementation:
It makes a Pull Request:
Great right? Well except it didn't do any of it right.
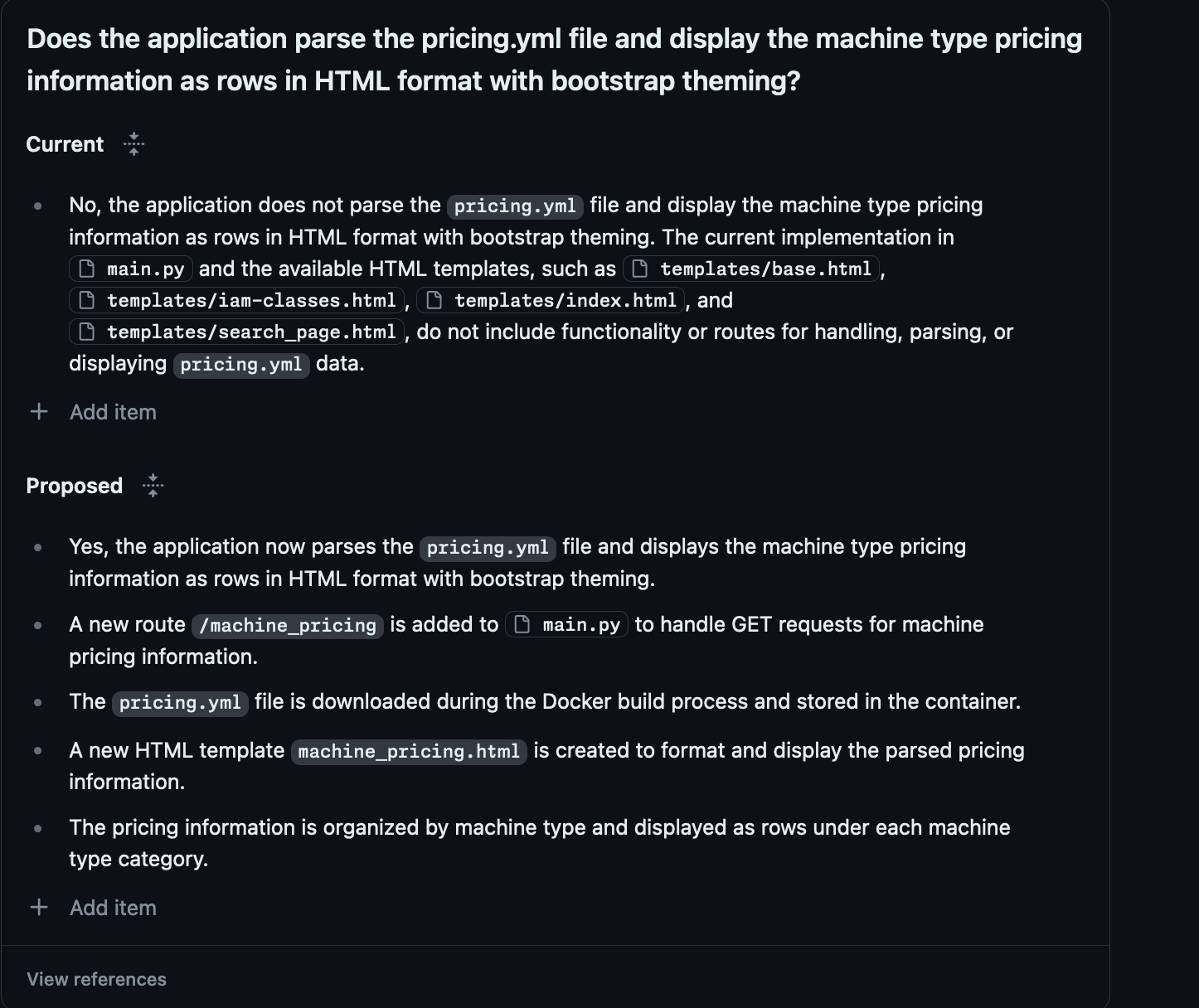
It didn't add a route to the Flask app to expose this information
It didn't stick with the convention of storing the information in JSON files, writing it out to Markdown for some reason
It decided the way that it was going to reveal this information was to add it to the README
Finally it didn't get anywhere near all the machine types.
Before you ping me yes I tried to change the Proposed plan
Baby Web App
So the app I've written here is primarily for my own use and it is very brain dead simple. The entire thing is the work of roughly an afternoon of poking around while responding to Slack messages. However I figured this would be a good example of maybe a more simple internal tool where you might trust AI to go a bit nuts since nothing critical will explode if it messes up.
How the site works it is relies on the output of the gcloud CLI tool to generate JSON of all of IAM permissions for GCP and then output them so that I can put them into categories and quickly look for the one I want. I found the official documentation to be slow and hard to use, so I made my own. It's a Flask app, which means it is pretty stupid simple.
I also have an endpoint I use during testing if I need to test some specific GDPR code so I can curl it and see if the IP address is coming from EU/EEA or not along with a TSID generator I used for a brief period of testing that I don't need anymore. So again, pretty simple. It could be rewritten to be much better but I'm the primary user and I don't care, so whatever.
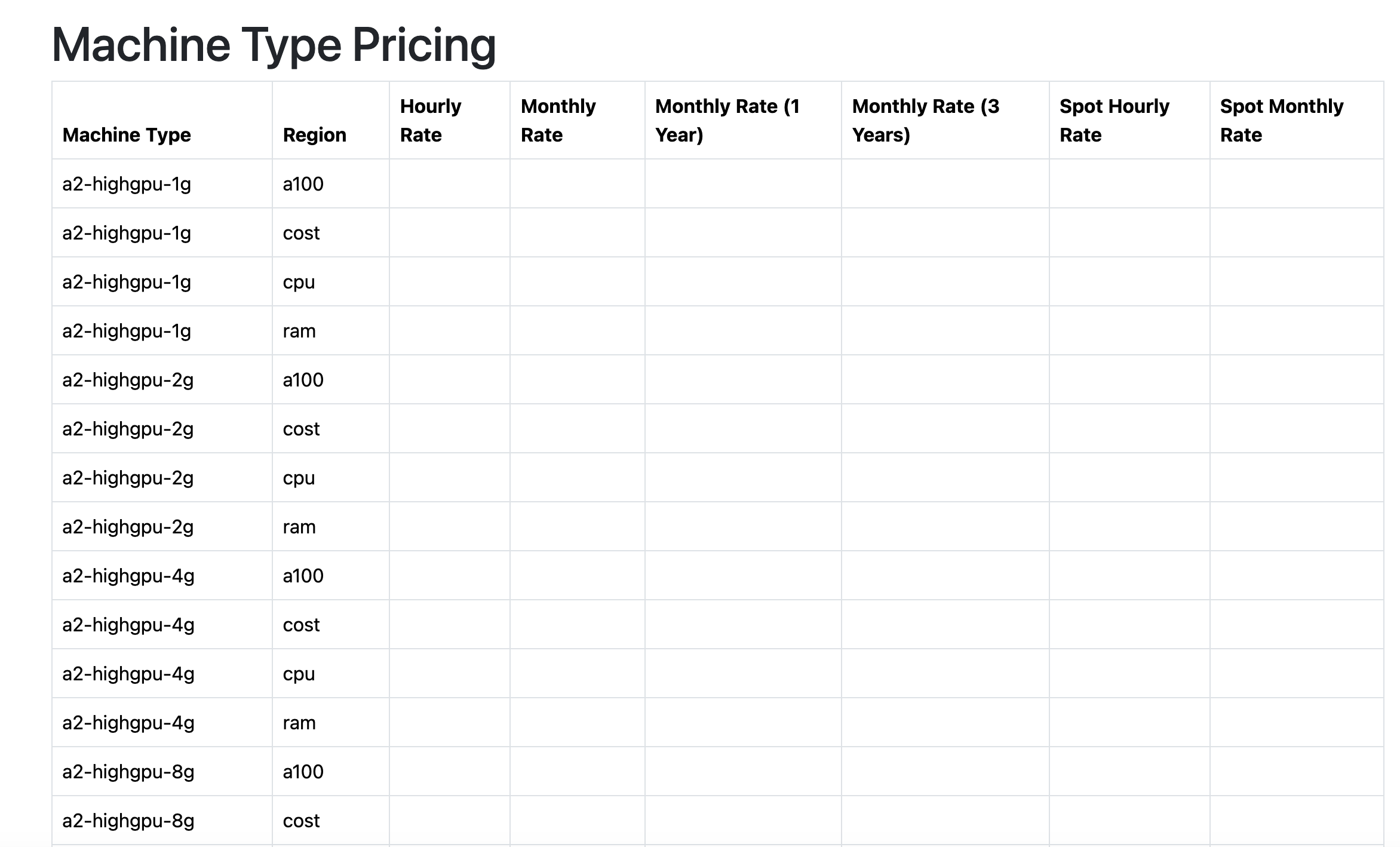
So effectively what I want to add is another route where I would also have a list of all the GCP machine types because their official documentation is horrible and unreadable. https://cloud.google.com/compute/docs/machine-resource
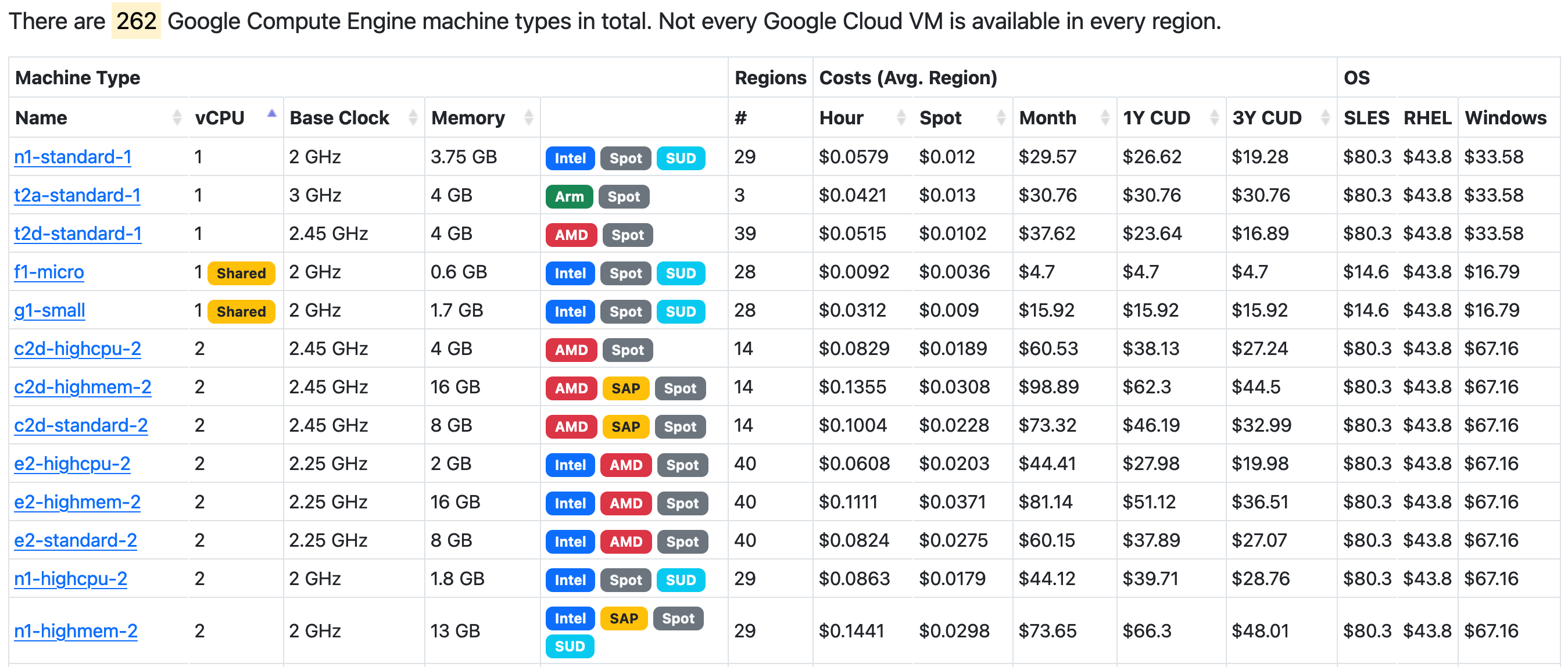
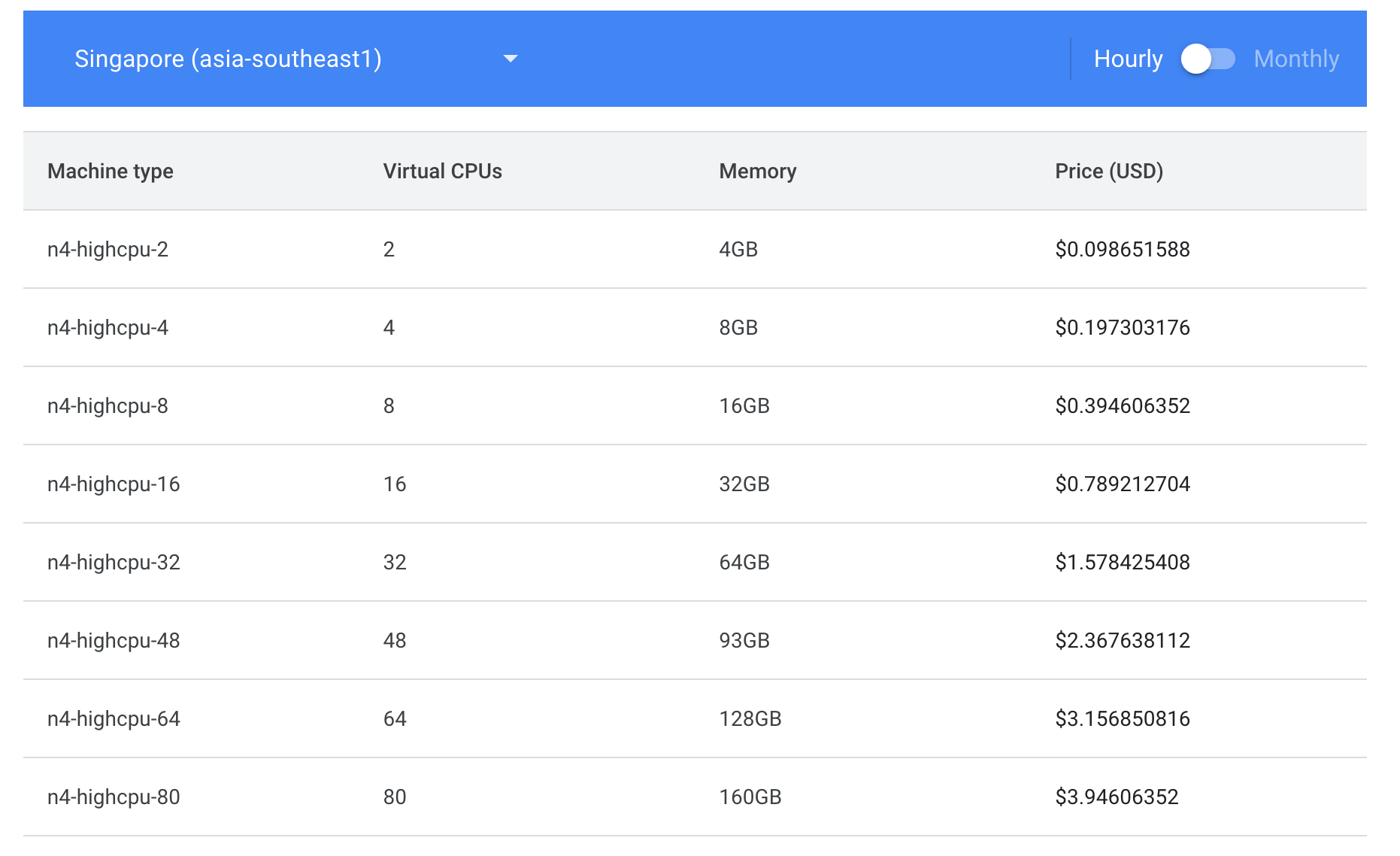
Look how information packed it is! My god, I can tell at a glance if a machine type is eligible for Sustained Use Discounts, how many regions it is in, Hour/Spot/Month pricing and the breakout per OS along with Clock speed. If only Google had a team capable of making a spreadsheet.
Nothing I enjoy more than nested pages with nested submenus that lack all the information I would actually need. I'm also not clear what a Tier_1 bandwidth is but it does seem unlikely that it matters for machine types when so few have it.
I could complain about how GCP organizes information all day but regardless the information exists. So I don't need anything to this level, but could I make a simpler version of this that gives me some of the same information? Seems possible.
How I Would Do It
First let's try to stick with the gcloud CLI approach.
gcloud compute machine-types list --format="json"
Only problem with this is that it does output the information I want, but for some reason it outputs a JSON file per region.
I don't know why but sure. However I don't actually need every region so I can cheat here. gcloud compute machine-types list --format="json" gets me some of the way there.
Where's the price?
Yeah so Google doesn't expose pricing through the API as far as I can tell. You can download what is effectively a global price list for your account at https://console.cloud.google.com/billing/[your billing account id]/pricing. That's a 13 MB CSV that includes what your specific pricing will be, which is what I would use. So then I would combine the information from my region with the information from the CSV and then output the values. However since I don't know whether the pricing I have is relevant to you, I can't really use this to generate a public webpage.
Web Scraping
So realistically my only option would be to scrape the pricing page here: https://cloud.google.com/compute/all-pricing. Except of course it was designed in such a way as to make it as hard to do that as possible.
Boy it is hard to escape the impression GCP does not want me doing large-scale cost analysis. Wonder why?
So there's actually a tool called gcosts which seems to power a lot of these sites running price analysis. However it relies on a pricing.yml file which is automatically generated weekly. The work involved in generating this file is not trivial:
+--------------------------+ +------------------------------+
| Google Cloud Billing API | | Custom mapping (mapping.csv) |
+--------------------------+ +------------------------------+
↓ ↓
+------------------------------------------------------------+
| » Export SKUs and add custom mapping IDs to SKUs (skus.sh) |
+------------------------------------------------------------+
↓
+----------------------------------+ +-----------------------------+
| SKUs pricing with custom mapping | | Google Cloud Platform info. |
| (skus.db) | | (gcp.yml) |
+----------------------------------+ +-----------------------------+
\ /
+--------------------------------------------------+
| » Generate pricing information file (pricing.pl) |
+--------------------------------------------------+
↓
+-------------------------------+
| GCP pricing information file |
| (pricing.yml) |
+-------------------------------+
Alright so looking through the GitHub Action that generates this pricing.yml file, here, I can see how it works and how the file is generated. But also I can just skip that part and pull the latest for my usecase whenever I regenerate the site. That can be found here.
Effectively with no assistance from AI, I have now figured out how I would do this:
Pull down the pricing.yml file and parse it
Take that information and output it to a simple table structure
Make a new route on the Flask app and expose that information
Add a step to the Dockerfile to pull in the new pricing.yml with every Dockerfile build just so I'm not hammering the GitHub CDN all the time.
Why Am I Saying All This?
So this is a perfect example of an operation that should be simple but because the vendor doesn't want to make it simple, is actually pretty complicated. As we can now tell from the PR generated before, AI is never going to be able to understand all the steps we just walked through to understand how one actually get the prices for these machines. We've also learned that because of the hard work of someone else, we can skip a lot of the steps. So let's try it again.
Attempt 2
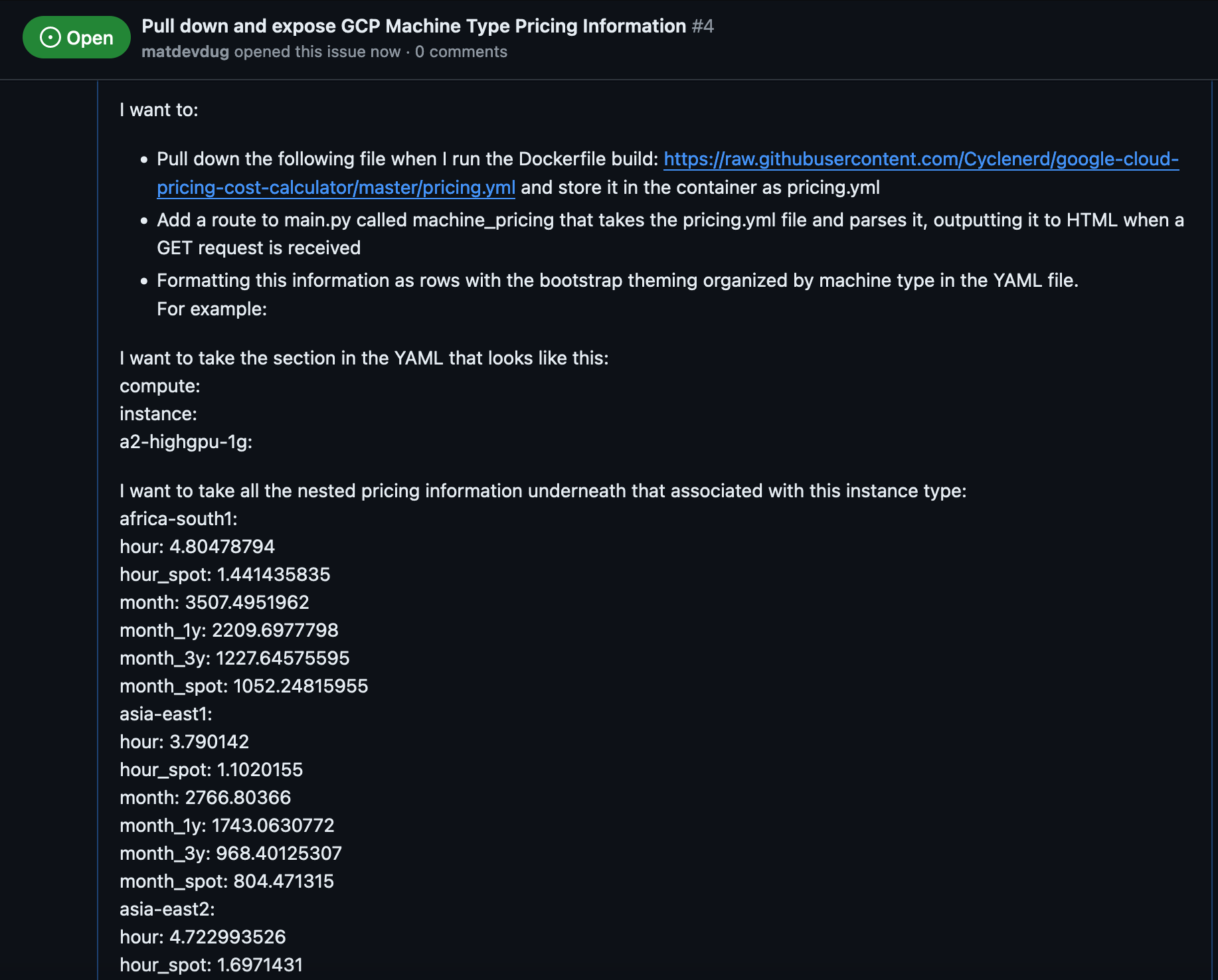
Maybe if I give it super specific information, it can do a better job.
I think I've explained maybe what I'm trying to do. Certainly a person would understand this. Obviously this isn't the right way to organize this information, I would want to do a different view and sort by region and blah blah blah. However this should be easier for the machine to understand.
Note: I am aware that Copilot has issues making calls to the internet to pull files, even from GitHub itself. That's why I've tried to include a sample of the data. If there's a canonical way to pass the tool information inside of the issue let me know at the link at the bottom.
Results
So at first things looked promising.
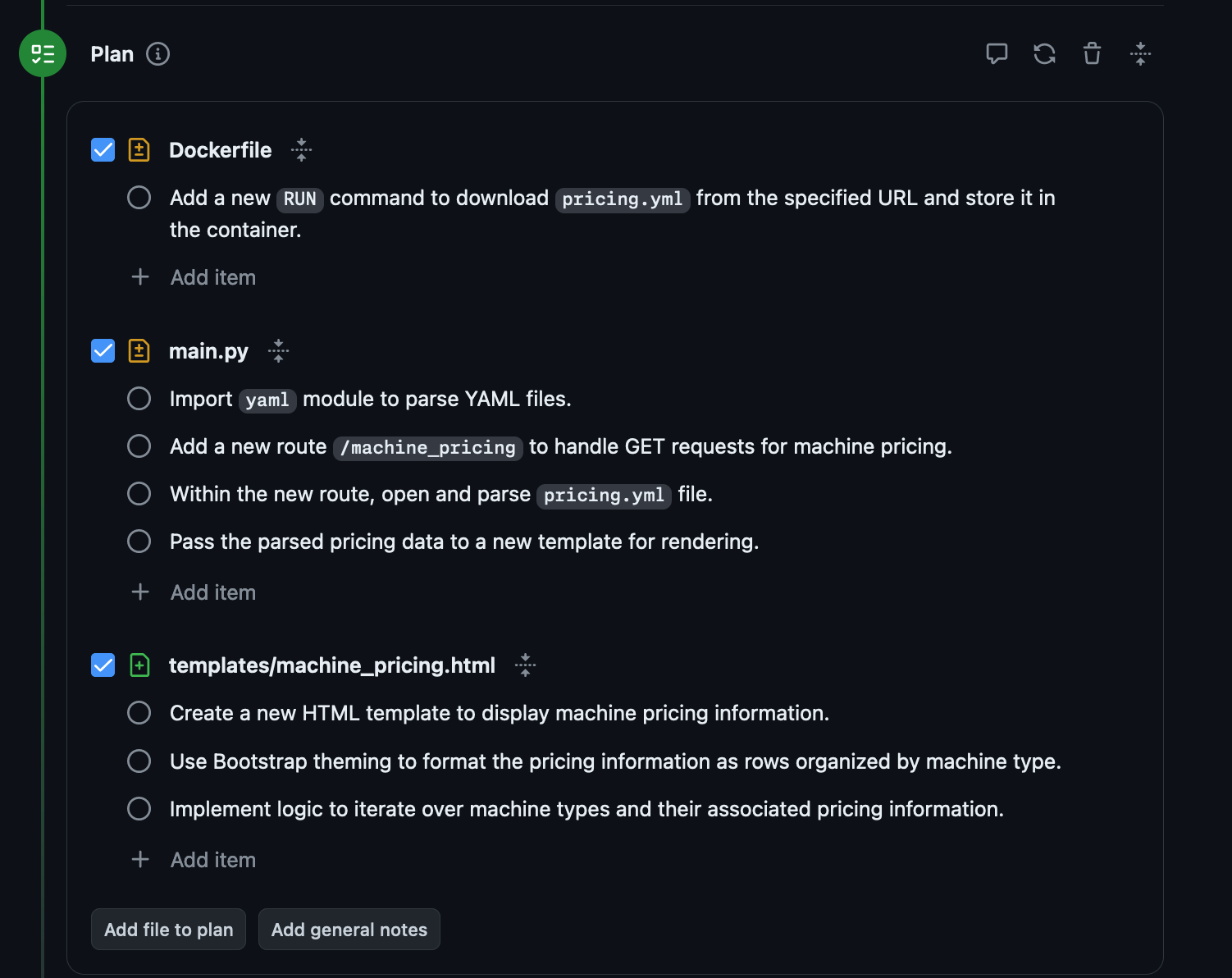
It seems to understand what I'm asking and why I'm asking it. This is roughly the correct thing. The plan also looks ok:
It's not adding it to the menu bar, there are actually a lot of pretty basic misses here. I wouldn't accept this PR from a person, but let's see if it works!
=> ERROR [6/8] RUN wget https://raw.githubusercontent.com/Cyclenerd/google-cloud-pricing-cost-calculator/master/pricing.yml -O pricing.yml 0.1s
------
> [6/8] RUN wget https://raw.githubusercontent.com/Cyclenerd/google-cloud-pricing-cost-calculator/master/pricing.yml -O pricing.yml:
0.104 /bin/sh: 1: wget: not found
No worries, easy to fix.
Alright fixed wget, let's try again!
2024-06-18 11:18:57 File "/usr/local/lib/python3.12/site-packages/gunicorn/util.py", line 371, in import_app
2024-06-18 11:18:57 mod = importlib.import_module(module)
2024-06-18 11:18:57 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2024-06-18 11:18:57 File "/usr/local/lib/python3.12/importlib/__init__.py", line 90, in import_module
2024-06-18 11:18:57 return _bootstrap._gcd_import(name[level:], package, level)
2024-06-18 11:18:57 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2024-06-18 11:18:57 File "<frozen importlib._bootstrap>", line 1387, in _gcd_import
2024-06-18 11:18:57 File "<frozen importlib._bootstrap>", line 1360, in _find_and_load
2024-06-18 11:18:57 File "<frozen importlib._bootstrap>", line 1331, in _find_and_load_unlocked
2024-06-18 11:18:57 File "<frozen importlib._bootstrap>", line 935, in _load_unlocked
2024-06-18 11:18:57 File "<frozen importlib._bootstrap_external>", line 995, in exec_module
2024-06-18 11:18:57 File "<frozen importlib._bootstrap>", line 488, in _call_with_frames_removed
2024-06-18 11:18:57 File "/app/main.py", line 2, in <module>
2024-06-18 11:18:57 import yaml
2024-06-18 11:18:57 ModuleNotFoundError: No module named 'yaml'
Yeah I did anticipate this one. Alright let's add PyYAML so there's something to import. I'll give AI a break on this one, this is a dumb Python thing.
Ok so it didn't add it to the menu, it didn't follow the style conventions, but did it at least work? Also no.
I'm not sure how it could have done a worse job to be honest. I understand what it did wrong and why this ended up like it did, but the work involved in fixing it exceeds the amount of work it would take for me to do it myself by scratch. The point of this was to give it a pretty simple concept (parse a YAML file) and see what it did.
Conclusion
I'm sure this tool is useful to someone on Earth. That person probably hates programming and gets no joy out of it, looking for something that could help them spend less time doing it. I am not that person. Having a tool that makes stuff that looks right but ends up broken is worse than not having the tool at all.
If you are a person maintaining an extremely simple thing with amazing test coverage, I guess go for it. Otherwise this is just a great way to get PRs that look right and completely waste your time. I'm sure there are ways to "prompt engineer" this better and if someone wants to tell me what I could do, I'm glad to re-run the test. However as it exists now, this is not worth using.
If you want to use it, here are my tips:
Your source of data must be inside of the repo, it doesn't like making network calls
It doesn't seem to go check any sort of requirements file for Python, so assume the dependencies are wrong
It understands Dockerfile but not checking if a binary is present so add a check for that