Around 2016, the term "serverless functions" started to take off in the tech industry. In short order, it was presented as the undeniable future of infrastructure. It's the ultimate solution to redundancy, geographic resilience, load balancing and autoscaling. Never again would we need to patch, tweak or monitor an application. The cloud providers would do it, all we had to do is hit a button and deploy to internet.
I was introduced to it like most infrastructure technology is presented to me, which is as a veiled threat. "Looks like we won't need as many Operations folks in the future with X" is typically how executives discuss it. Early in my career this talk filled me with fear, but now that I've heard it 10+ times, I adopt a "wait and see" mentality. I was told the same thing about VMs, going from IBM and Oracle to Linux, going from owning the datacenter to renting a cage to going to the cloud. Every time it seems I survive.
Even as far as tech hype goes, serverless functions picked up steam fast. Technologies like AWS Lambda and GCP Cloud Functions were adopted by orgs I worked at very fast compared to other technology. Conference after conference and expert after expert proclaimed that serverless was inevitable. It felt like AWS Lambda and others were being adopted for production workloads at a breakneck pace.
Then, without much fanfare, it stopped. Other serverless technologies like GKE Autopilot and ECS are still going strong, but the idea of a serverless function replacing the traditional web framework or API has almost disappeared. Even cloud providers pivoted, positioning the tools as more "glue between services" than the services themselves. The addition of being able to run Docker containers as functions seemed to help a bit, but it remains a niche component of the API world.
What happened? Why were so many smart people wrong? What can we learn as a community about hype and marketing around new tools?
Promise of serverless
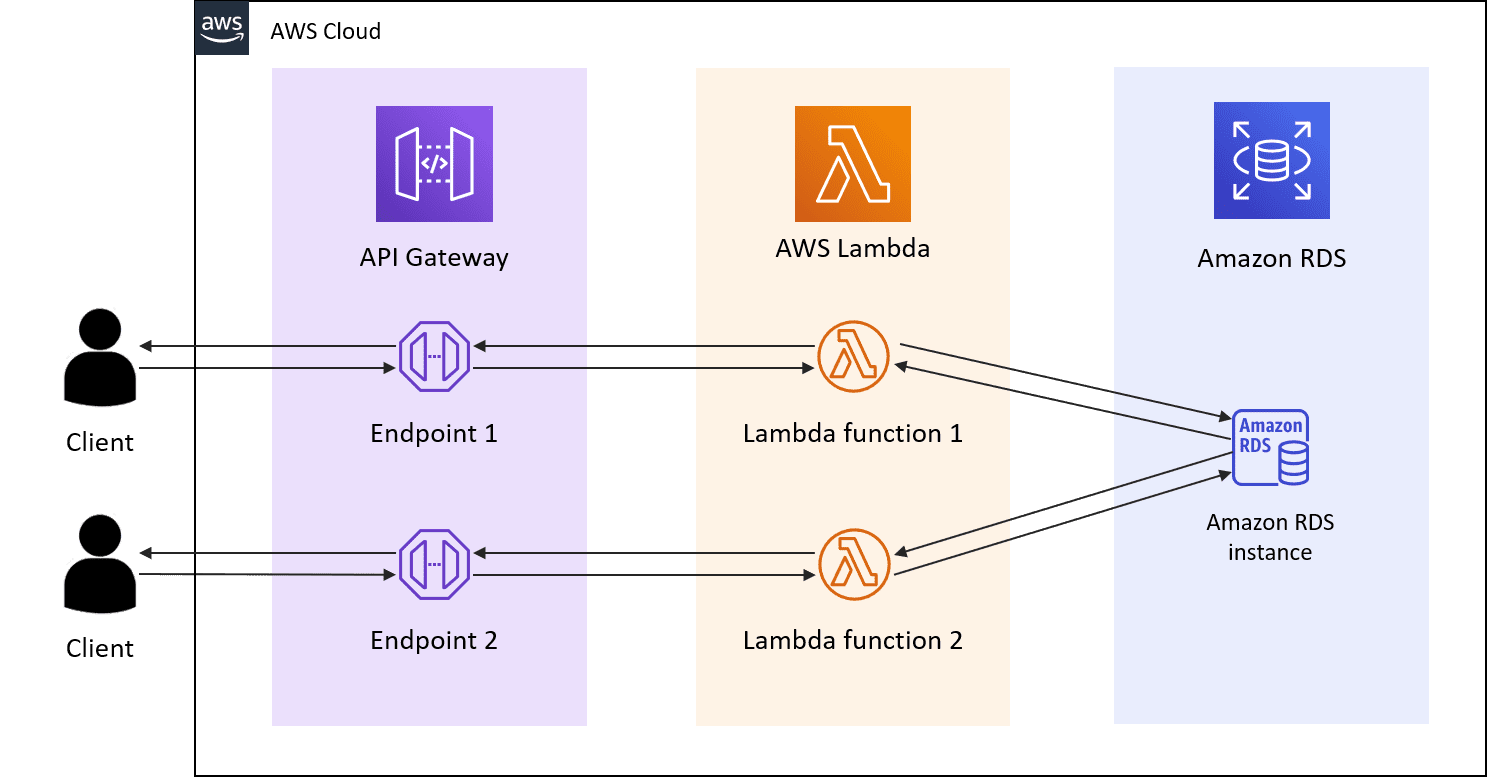
Above we see a serverless application as initially pitched. Users would ingress through the API Gateway technology, which handles everything from traffic management, CORS, authorization and API version management. It basically serves as the web server and framework all in one. Easy to test new versions with multiple versions of the same API at the same time, easy to monitor and easy to set up.
After that comes the actual serverless function. These could be written in whatever language you wanted and could run for up to 15 minutes as of 2023. So instead of having, say, a Rails application where you are combining the Model-View-Controller into a monolith, you can break it into each route and use different tools to solve for each situation.
Since these were only invoked in response to a request coming from a user, it was declared a cost savings. You weren't paying for server resources you weren't using, unlike traditional servers where you would provision the expected capacity beforehand based on a guess. The backend would also endlessly scale, meaning it would be impossible to overwhelm the service with traffic. No more needing to worry about DDoS or floods of traffic.
Finally at the end would be a database managed by your cloud provider. All in all you aren't managing any element of this process, so no servers or software updates. You could deploy a thousand times a day and precisely control the rollout and rollback of code. Each function could be written in the language that best suited it. So maybe your team writes most things in Python or Ruby but then goes back through for high volume routes and does those in Golang.
Combined with technologies like S3 and DynamoDB along with SNS you have a compelling package. You could still send messages between functions with SNS topics. Storage was effectively unlimited with S3 and you had a reliable and flexible key-value store with DynamoDB. Plus you ditched the infrastructure folks, the monolith, any dependency on the host OS and you were billed by your cloud provider for your actual usage based on the millisecond.
Initial Problems
The initial adoption of serverless was challenging for teams, especially teams used to monolith development.
- Local development. Typically a developer pulls down the entire application they're working on and runs it on their device to be able to test quickly. With serverless, that doesn't really work since the application is potentially thousands of different services written in different languages. You can do this with serverless functions but it's way more complicated.
- Hard to set resources correctly. How much memory did this function need under testing can be very different from how much it needs under production. Developers tended to set their limits high to avoid problems, wiping out much of the cost savings. There is no easy way to adjust functions based on real-world data outside of doing it by hand one by one.
- AWS did make this process easier with AWS Lambda Power Tuning but you'll still need to roll out the changes yourself function by function. Since even a medium sized application can be made up of 100+ functions, this is a non-trivial thing to do. Plus these aren't static things, changes can get rolled out that dramatically change the memory usage with no warning
- Is it working? Observability is harder with a distributed system vs a monolith and serverless just added to that. Metrics are less useful as are old systems like uptime checks. You need, certainly in the beginning, to rely on logs and traces a lot more. For smaller teams especially, the monitoring shift from "uptime checks + grafana" to a more complex log-based profile of health was a rough adjustment.
All these problems were challenges but it seems many were able to get through it with momentum intact. We started to see a lot of small applications launch that were serverless function based, from APIs to hobby developer projects. All of this is reflected by the Datadog State of Serverless report for 2020 which you can see here.
At this point everything seems great. 80% of AWS container users have adopted Lambda in some capacity, paired with SQS and DynamoDB. NodeJS and Python are the dominant languages, which is a little eyebrow raising. This suggests that picking the right language for the job didn't end up happening, instead picking the language easiest for the developer. But that's fine, that is also an optimization.
What happened? What went wrong?
Production Problems
Across the industry we started to hear feedback from teams that had gone hard into serverless functions backing back out. I started to see problems in my own teams that had adopted serverless. The following trends came up in no particular order.
- Latency. Traditional web frameworks and containers are fast at processing requests, typically hitting latency in database calls. Serverless functions were slow depending on the last time you invoked them. This led to teams needing to keep "functions warm." What does this mean?
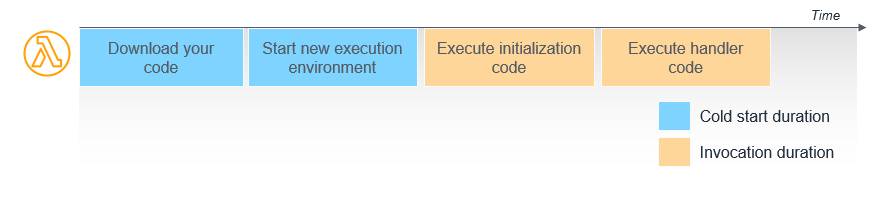
When the function gets a request it downloads the code and gets ready to run it. After that for a period of time, the function is just ready to rerun until it is recycled and the process needs to be run again. The way around this at first was typically an EventBridge rule to keep the function running every minute. This kind of works but not really.
Later Provisioned Concurrency was added, which is effectively....a server. It's a VM where your code is already loaded. You are limited per account to how many functions you can have set to be Provisioned Concurrency, so it's hardly a silver bullet. Again none of this happens automatically, so its up to someone to go through and carefully tune each function to ensure it is in the right category.
- Scaling. Serverless functions don't scale to infinity. You can scale concurrency levels up every minute by an additional 500 microVMs. But it is very possible for one function to eat all of the capacity for every other function. Again it requires someone to go through and understand what Reserved Concurrency each function needs and divide that up as a component of the whole.
In addition, serverless functions don't magically get rid of database concurrency limits. So you'll hit situations where a spike of traffic somewhere else kills your ability to access the database. This is also true of monoliths, but it is typically easier to see when this is happening when the logs and metrics are all flowing from the same spot.
In practice it is far harder to scale serverless functions than an autoscaling group. With autoscaling groups I can just add more servers and be done with it. With serverless functions I need an in-depth understanding of each route of my app and where those resources are being spent. Traditional VMs give you a lot of flexibility in dealing with spikes, but serverless functions don't.
There are also tiers of scaling. You need to think of KMS throttling, serverless function concurrency limit, database connection limits, slow queries. Some of these don't go away with traditional web apps, but many do. Solutions started to pop up but they often weren't great.
Teams switched from always having a detailed response from the API to just returning a 200 showing that the request had been received. That allowed teams to stick stuff into an SQS queue and process it later. This works unless there is a problem in processing, breaking the expectations from most clients that 200 means the request was successful, not that the request had been received.
Functions often needed to be rewritten as you went, moving everything you could to the initialization phase and keeping all the connection logic out of the handler code. The initial momentem of serverless was crashing into the rewrites as teams learned painful lesson after painful lesson.
- Price. Instead of being fire and forget, serverless functions proved to be very expensive at scale. Developers don't think of routes of an API in terms of how many seconds they need to run and how much memory they use. It was a change in thinking and certainly compared to a flat per-month EC2 pricing, the spikes in traffic and usage was an unpleasant surprise for a lot of teams.
Combined with the cost of RDS and API Gateway and you are looking at a lot of cash going out every month.
The other cost was the requirement that you have a full suite of cloud services identical to production for testing. How do you test your application end to end with serverless functions? You need to stand up the exact same thing as production. Traditional applications you could test on your laptop and run tests against it in the CI/CD pipeline before deployment. Serverless stacks you need to rely a lot more on Blue/Green deployments and monitoring failure rates.
- Slow deployments. Pushing out a ton of new Lambdas is a time-consuming process. I've waited 30+ minutes for a medium-sized application. God knows how long people running massive stacks were waiting.
- Security. Not running the server is great, but you still need to run all the dependencies. It's possible for teams to spawn tons of functions with different versions of the same dependencies, or even choosing to use different libraries. This makes auditing your dependency security very hard, even with automation checking your repos. It is more difficult to guarantee that every compromised version of X dependency is removed from production than it would be for a smaller number of traditional servers.
Why didn't this work?
I think three primary mistakes were made.
- The complexity of running a server in a modern cloud platform was massively overstated. Especially with containers, running a linux box of some variety and pushing containers to it isn't that hard. All the cloud platform offer load balancers, letting you offload SSL termination, so really any Linux box with Podman or Docker can run listening on that port until the box has some sort of error.
Setting up Jenkins to be able to monitor Docker Hub for an image change and trigger a deployment is not that hard. If the servers are just doing that, setting up a new box doesn't require the deep infrastructure skills that serverless function advocates were talking about. The "skill gap" just didn't exist in the way that people were talking about. - People didn't think critically about price. Serverless functions look cheap, but we never think about how many seconds or minute a server is busy. That isn't how we've been conditioned to think about applications and it showed. Often the first bill was a shocker, meaning the savings from maintenance had to be massive and they just weren't.
- Really hard to debug problems. Relying on logs and X-Ray to figure out what went wrong is just much harder than pulling the entire stack down to your laptop and triggering the same requests. It is a new skill and one that people had not developed up to that point. The first time you have a long-running production issue that would have been trivial to fix in the old monolith application design style that persists for a long time in the serverless function world, the enthusiasm from leadership evaporates very quickly.
Conclusion
Serverless functions fizzled out and it's important for us as an industry to understand why the hype wasn't real. Important questions were skipped over in an attempt to increase buy-in to cloud platforms and simplify the deployment and development story for teams. Hopefully this provides us a chance to be more skeptical of promises like this in the future. We should have adopted a much more wait and see to this technology instead of rushing straight in and hitting all the sharp edges right away.
Currently serverless functions live as what they're best at, which is either glue between different services, triggering longer-running jobs or as very simple platforms that allow for tight cost control by single developers who are putting together something for public use. If you want to use something serverless for more, you would be better off looking at something like ECS with Fargate or Cloud Run in GCP.