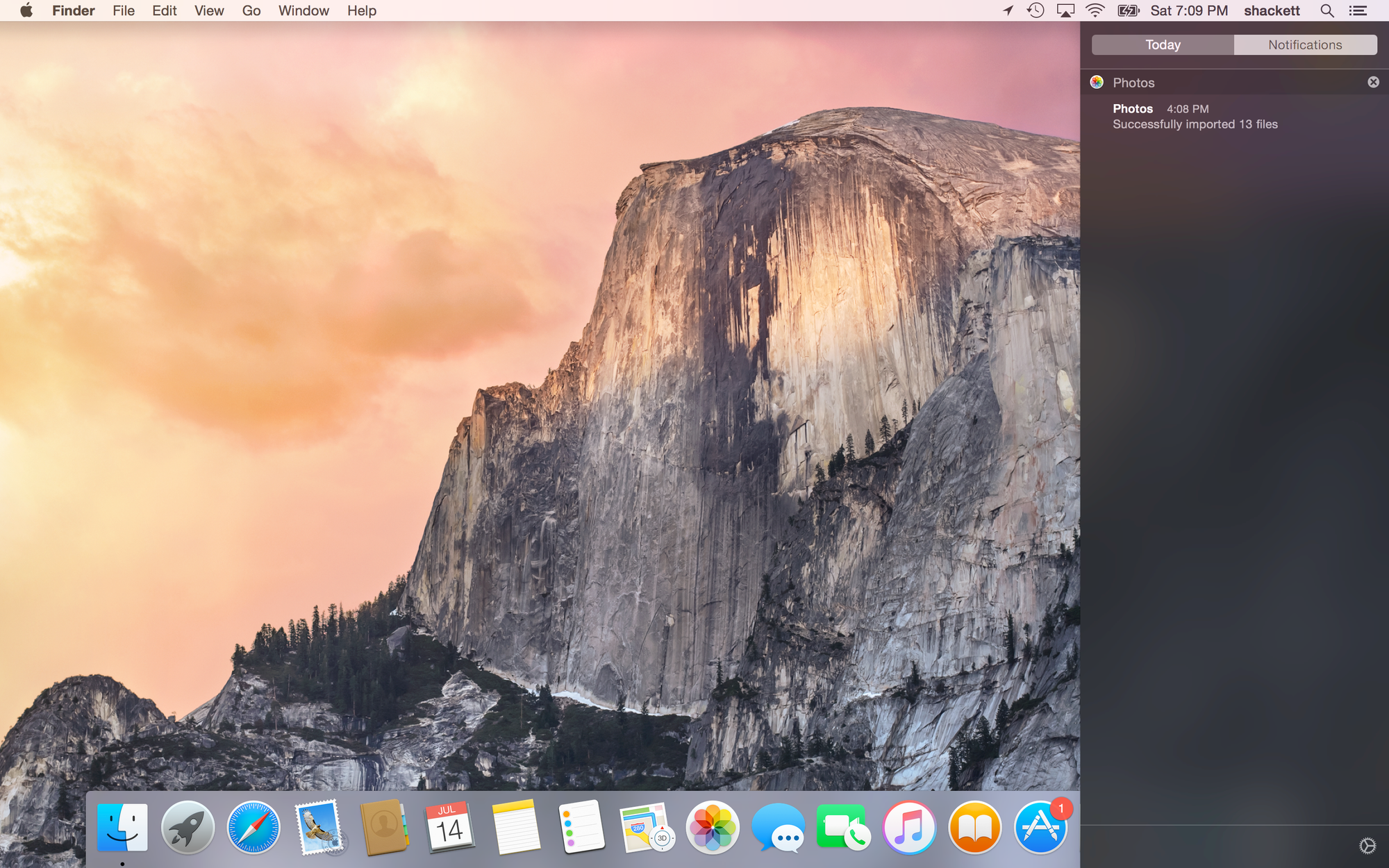
I was recently summoned to a meeting in Stockholm, a city I had somehow managed to avoid despite living in Copenhagen for years. My Swedish experience, up to this point, consisted entirely of trips to Malmö — the closest Swedish city to Denmark and, more importantly, home to a Costco. As an American living abroad, I am duty-bound to report there every six months so the proper authorities know I'm still alive and to procure my ceremonial barrel of peanut butter pretzels. It's less a shopping trip than a consular check-in.
Stockholm, it turns out, is much further from Copenhagen than anyone lets on. My options were to fly or take the train. Flying is technically a one-hour affair, but to make a 9 AM meeting I'd have to wake up at 4 AM, shuffle through security in a fugue state, and land in Sweden looking like a hostage video. I wasn't sure when I'd nap. This seemed insane.
Then I had what I believed, at the time, to be a genius idea: the overnight train from Malmö to Stockholm. I'd sleep en route, wake refreshed, stride into my meeting like a man who understood something about life that others did not. Plus, I love trains. Sweden has a high-speed line that does the run in four hours, but the night train takes its time, which sounded charming. It was not charming.
The first surprise came at booking. There are three tiers of experience: a seat, a couchette (whatever the fuck that is), or a private sleeping compartment. Since I wasn't paying, I chose the private compartment. This would prove to be the single smartest decision of my adult life, possibly of anyone's adult life. If you are reading this from some point in the future and you are over the age of thirty, book the private compartment. I don't care what it costs. Sell a kidney. I'll explain.
Departure
My train left Malmö at 10:30 PM. The station there is depressing in a way that's hard to articulate in that nothing is obviously wrong. There's a grocery store. There's a convenience store. And yet everyone inside looks stranded, as though they've been waiting for something that isn't coming. Small children roam in feral packs. There is a pervasive sense that this is the last train out of somewhere very bad, and that whatever is chasing everyone is still, perhaps, on its way.
Amtrak in the US has this feeling, a vibe that you are running from the law. I remember when my family used to take the train from Ohio to New Jersey, waiting for it at a train station that was basically a concrete bunker in the middle of a corn field. The concrete box would either be freezing cold due to too much AC or boiling hot due to too much heat. I would stay up late on the train and watch as parents would abandon sleeping children to jump off at stops and catch a smoke. They all had a nervous desperation that these Swedish travelers shared. It's the kind of place where you wouldn't be surprised to see someone take a SIM card out of a phone and throw it in the trash.
I stopped at the grocery store and loaded my backpack — my only luggage — with provisions: two large water bottles, wet wipes, a change of clothes, a bag of nuts, and, as an emergency measure, two Red Bulls, in case sleep failed me and I had to power through the following day on hatred and that cursed, faintly urine-themed energy drink. Then I stopped by the men's room, which featured a decorative fish tank whose sole occupant had a full-frontal view of the urinals. If reincarnation is real, Henry Kissinger is in that tank.
European train station bathrooms are often weird, but this was up there. First there was no automated system to get in, it was just a guy with a credit card reader. Also they were piping in tropical sounds to the bathroom which I assume is to cover the unspeakable horrors happening in the stalls. I felt uncomfortable that I kept looking at the fish and found it to be always staring at me. The tank was in really good condition, with incredibly clean water. I couldn't help but think maybe its better for the fish to die faster than live their entire lives staring at an endless line of men peeing.
I found my train and boarded, and I knew immediately I was in trouble.
This was an old-school train — varnished wood, worn blue upholstery, late-70s energy throughout. The regular seats were hard, upright benches with little fold-down wooden tray tables. They did not recline. Not a little. Not at all. Which raises the question: why call it a night train? Night train implies, to me, that at some point during the night, someone might sleep. But the seats also had bright lights above them that never turned off, which transformed them from sleeper seats into something closer to interrogation chairs.

The couchettes turned out to be stacked bunks — men-only, women-only, or mixed and the passengers were packed together so tightly that the gender segregation began to make a grim, practical sense. I'm not squeamish around strangers, but we're talking well within reach-out-and-stroke-someone's-hair range. My private room looked roughly like a jail cell: a cot, a light that turned off, a door that locked. In other words, everything I have ever wanted from a hotel. That's not sarcasm, I'm easy to please.
Naturally, I was far too curious about the rest of the train to actually sleep, so I set out to wander.
Train to Hell
The three conductors on duty were all wearing bodycams strapped to their chests, which is always an encouraging sign in that it suggests both that they had been attacked and that they had, at some point, done some attacking of their own. They were also wearing shorts, which felt deeply wrong. There's something unsettling about a train conductor without pants. It's a formal job. You don't want your pilot in flip-flops and you don't want your conductor showing knee.
I don't know what it is about shorts on men specifically that come across as clownish, but there is a ranking of jobs where one shouldn't wear shorts all the way to one cannot wear shorts. Doctors, pilots, lawyers, accountants are all pants jobs. Train conductor felt like a no-brainer that it would be a pants job, also frankly I think they should also have to wear a cool hat and have a pocket watch. In the same way I would bristle at a judge sentencing me to death in a Hawaiian shirt, a train conductor in shorts checking my ticket feels wrong.
I made my way a few cars down to see how the general population was faring.
The door slid open and I was hit, physically, by the smell of cheap vodka. Before me stretched a sea of Swedes, each with the specific facial expression of a person who has just realized they have made a terrible mistake and cannot un-make it. Two people were openly weeping. Three others were borderline-homeless-looking punk kids dressed exactly the way punks dressed in 1994 — I don't know who is still manufacturing M65 field jackets and military jump boots, but they're clearly still moving units in southern Sweden.
One of the punks was vomiting into a plastic bag, seated next to a very sweet-looking, deeply concerned young woman who had presumably boarded this train with hopes and plans. She had the look of a woman who had her life together. The conductors arrived, spoke to him, were told to fuck off, and then quietly relocated the young woman to a new seat the way you'd move a house plant away from a leaking radiator. The punks then began joking loudly among themselves, two of them taking turns retching up what smelled like vodka cut with unleaded gasoline.
God help anyone trying to sleep back here. Between the puking, the reek, and the punks openly hitting on every woman within shouting distance, it was like being trapped on a Greyhound bus that had sworn a blood oath never to stop. I watched a man roughly my own age attempt to sleep by laying his face directly on the wooden tray table, earplugs jammed in, arms limp at his sides, in the international posture of I have given up.
I left when a boyfriend and girlfriend began fighting because she had proven surprisingly receptive to the advances of a punk kid whose body odor was strong enough to reach me three rows back. The boyfriend — sitting directly next to her — took issue with this, which seemed reasonable. I moved on to the meal car.
The meal car was the hangout, the refugee camp, the place where people who had discovered they couldn't sleep in the bunks came to sit and stare into the middle distance. Two young women were seated at a table nearby, one of them work-shopping, in English, why she deserved better than her current boyfriend in Malmö.
"I don't think I should settle for average."
Her friend was being supportive and kept trying to inject something about her own life, only to be steamrolled every time.
"Yeah, I know exact—"
"It's just, I work so hard at school and he doesn't."
"My last boyfr—"
"Maybe when we get to Stockholm we go buy some nice dresses and go dancing."
"That sounds fu—"
"Because I really do think I deserve to feel beautiful."
After a few rounds of this, I got bored. It was all early-twenties drama, and I don't say that with contempt because it's a phase we all pass through. In your twenties, you discuss your plans and feelings as though they matter, because to you, they do. In your late thirties, you come to understand that nobody actually cares if you live or die, and you learn, mercifully, to keep it all to yourself. It's one of the small gifts of aging, along with knowing how to fold a fitted sheet and no longer pretending to enjoy helping people move.
Friends in your 20s are your therapists, your closest confidants and your relationship counselors. In your 30s, you have an actual therapist and don't have to burden the people around you. At some point in everyone's life someone they love and respect will put up their hands and say "alright ENOUGH" and you'll realize how tiring you are. These women hadn't gotten there yet, but I did think the friend should start charging for this therapy session.
I retired to my cabin and fell asleep almost instantly. The rocking of the train, the smug satisfaction of not being propped upright in a wooden pew next to a vomiting stranger, and a modest dose of melatonin combined into something close to bliss.
Stockholm
We arrived on time. I grabbed my backpack and stepped out into Stockholm Central Station at 6 AM, which was nearly deserted. I found a coffee shop, ordered a coffee, and was charged an amount that made me wonder "should I open a coffee shop in Stockholm?". As he handed it over, the barista said, cheerfully, "It's my first day."
"You shouldn't tell people that," I replied.
I then felt terrible about it for approximately one hour. He, for his part, seemed entirely unfazed, or possibly hadn't heard me at all, which somehow made it worse. I carried the guilt with me through security, out onto the street, and into the cab I hailed for the twenty-minute ride to my meeting.
The meter began climbing almost immediately, and with a kind of enthusiasm I hadn't previously known meters possessed. He asked where I was from. I said the U.S. He said he loved Americans. He said Americans were the best people which, frankly, nobody says unless they're being tortured by us. He asked if this was my first time in Stockholm. He asked what I did for work. Every question was warm and generous and I understood, dimly, that I was being courted.
But it was only twenty minutes, how bad could it be? Eleven hundred kronor later, I stepped out onto the curb while he tried to press his business card into my hand so I could call him directly for future rides. Having just paid roughly $120 to travel the distance of a decent jog, I now understood his enthusiasm. He'd hit the jackpot, and the jackpot was me.
The meeting wrapped in a few hours. I took an Uber back for a quarter of the cab fare — a small, petty vindication I savored the entire ride — and spent the next four hours walking around Stockholm. It's genuinely lovely, and denser than I expected. Copenhagen feels like a city that was designed by someone who liked people; Stockholm feels like a city that was designed by someone who respected them but wasn't sure he wanted them over for dinner. More cars, less green, wider streets, harder edges. Every Swede I passed looked as though they were on their way to something slightly more important than what I was doing. It was beautiful in the way certain people are beautiful — the kind of beauty that doesn't especially need you to notice.
Conclusion
Should you take the overnight Swedish train? Honestly? Probably not this one, unless you are terrified of flying or being sober. The only tolerable option for an adult human is the private cabin, and at that price you can usually just fly. But it was, undeniably, an experience and one I would happily repeat, provided someone else were footing the bill.