We hardly knew ye.
DevOps, like many trendy technology terms, has gone from the peak of optimism to the depths of exhaustion. While many of the fundamental ideas behind the concept have become second-nature for organizations, proving it did in fact have a measurable outcome, the difference between the initial intent and where we ended up is vast. For most organizations this didn't result in a wave of safer, easier to use software but instead encouraged new patterns of work that centralized risk and introduced delays and irritations that didn't exist before. We can move faster than before, but that didn't magically fix all our problems.
The cause of its death was a critical misunderstanding over what was causing software to be hard to write. The belief was by removing barriers to deployment, more software would get deployed and things would be easier and better. Effectively that the issue was that developers and operations teams were being held back by ridiculous process and coordination. In reality these "soft problems" of communication and coordination are much more difficult to solve than the technical problems around pushing more code out into the world more often.
What is DevOps?
DevOps, when it was introduced around 2007, was a pretty radical concept of removing the divisions between people who ran the hardware and people who wrote the software. Organizations still had giant silos between teams, with myself experiencing a lot of that workflow.
Since all computer nerds also love space, it was basically us cosplaying as NASA. Copying a lot of the procedures and ideas from NASA to try and increase the safety around pushing code out into the world. Different organizations would copy and paste different parts, but the basic premise was every release was as close to bug free as time allowed. You were typically shooting for zero exceptions.
When I worked for a legacy company around that time, the flow for releasing software looked as follows.
- Development team would cut a release of the server software with a release number in conjunction with the frontend team typically packaged together as a full entity. They would test this locally on their machines, then it would go to dev for QA to test, then finally out to customers once the QA checks were cleared.
- Operations teams would receive a playbook of effectively what the software was changing and what to do if it broke. This would include how it was supposed to be installed, if it did anything to the database, it was a whole living document. The idea was the people managing the servers, networking equipment and SANs had no idea what the software did or how to fix it so they needed what were effectively step by step instructions. Sometimes you would even get this as a paper document.
- Since these happened often inside of your datacenter, you didn't have unlimited elasticity for growth. So, if possible, you would slowly roll out the update and stop to monitor at intervals. But you couldn't do what people see now as a blue/green deployment because rarely did you have enough excess server capacity to run two versions at the same time for all users. Some orgs did do different datacenters at different times and cut between them (which was considered to be sort of the highest tier of safety).
- You'd pick a deployment day, typically middle of the week around 10 AM local time and then would monitor whatever metrics you had to see if the release was successful or not. These were often pretty basic metrics of success, including some real eyebrow raising stuff like "is support getting more tickets" and "are we getting more hits to our uptime website". Effectively "is the load balancer happy" and "are customers actively screaming at us".
- You'd finish the deployment and then the on-call team would monitor the progress as you went.
Why Didn't This Work
Part of the issue was this design was very labor-intensive. You needed enough developers coordinating together to put together a release. Then you needed a staffed QA team to actually take that software and ensure, on top of automated testing which was jusssttttt starting to become a thing, that the software actually worked. Finally you needed a technical writer working with the development team to walk through what does a release playbook look like and then finally have the Operations team receive, review the book and then implement the plan.
It was also slow. Features would often be pushed for months even when they were done just because a more important feature had to go out first. Or this update was making major changes to the database and we didn't want to bundle in six things with the one possibly catastrophic change. It's effectively the Agile vs Waterfall design broken out to practical steps.
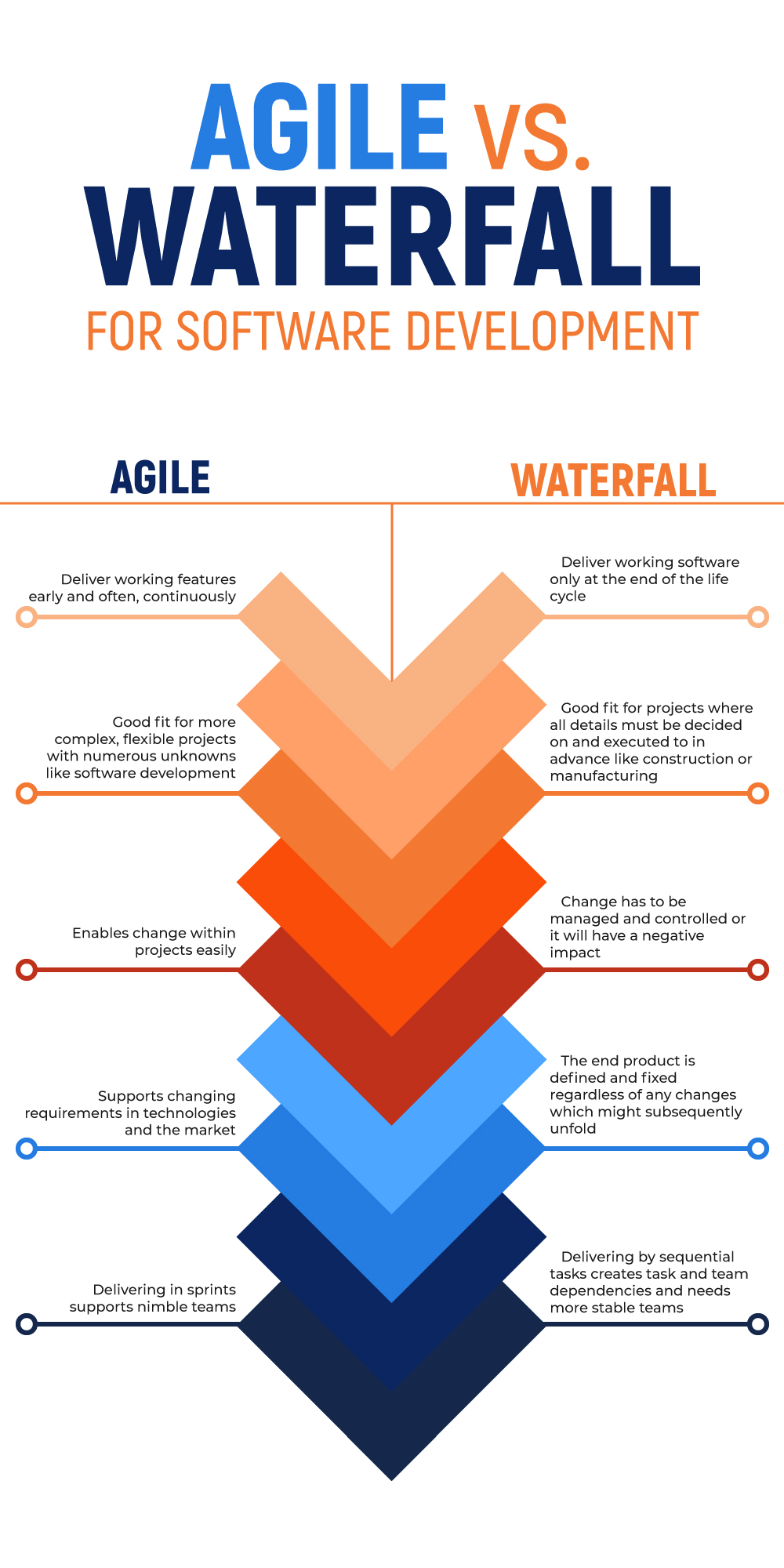
A lot of the lip service around this time that was given as to why organizations were changing was, frankly, bullshit. The real reason companies were so desperate to change was the following:
- Having lots of mandatory technical employees they couldn't easily replace was a bummer
- Recruitment was hard and expensive.
- Sales couldn't easily inject whatever last-minute deal requirement they had into the release cycle since that was often set it stone.
- It provided an amazing opportunity for SaaS vendors to inject themselves into the process by offloading complexity into their stack so they pushed it hard.
- The change also emphasized the strengths of cloud platforms at the time when they were starting to gobble market share. You didn't need lots of discipline, just allocate more servers.
- Money was (effectively) free so it was better to increase speed regardless of monthly bills.
- Developers were understandably frustrated that minor changes could take weeks to get out the door while they were being blamed for customer complaints.
So executives went to a few conferences and someone asked them if they were "doing DevOps" and so we all changed our entire lives so they didn't feel like they weren't part of the cool club.
What Was DevOps?
Often this image is used to sum it up:
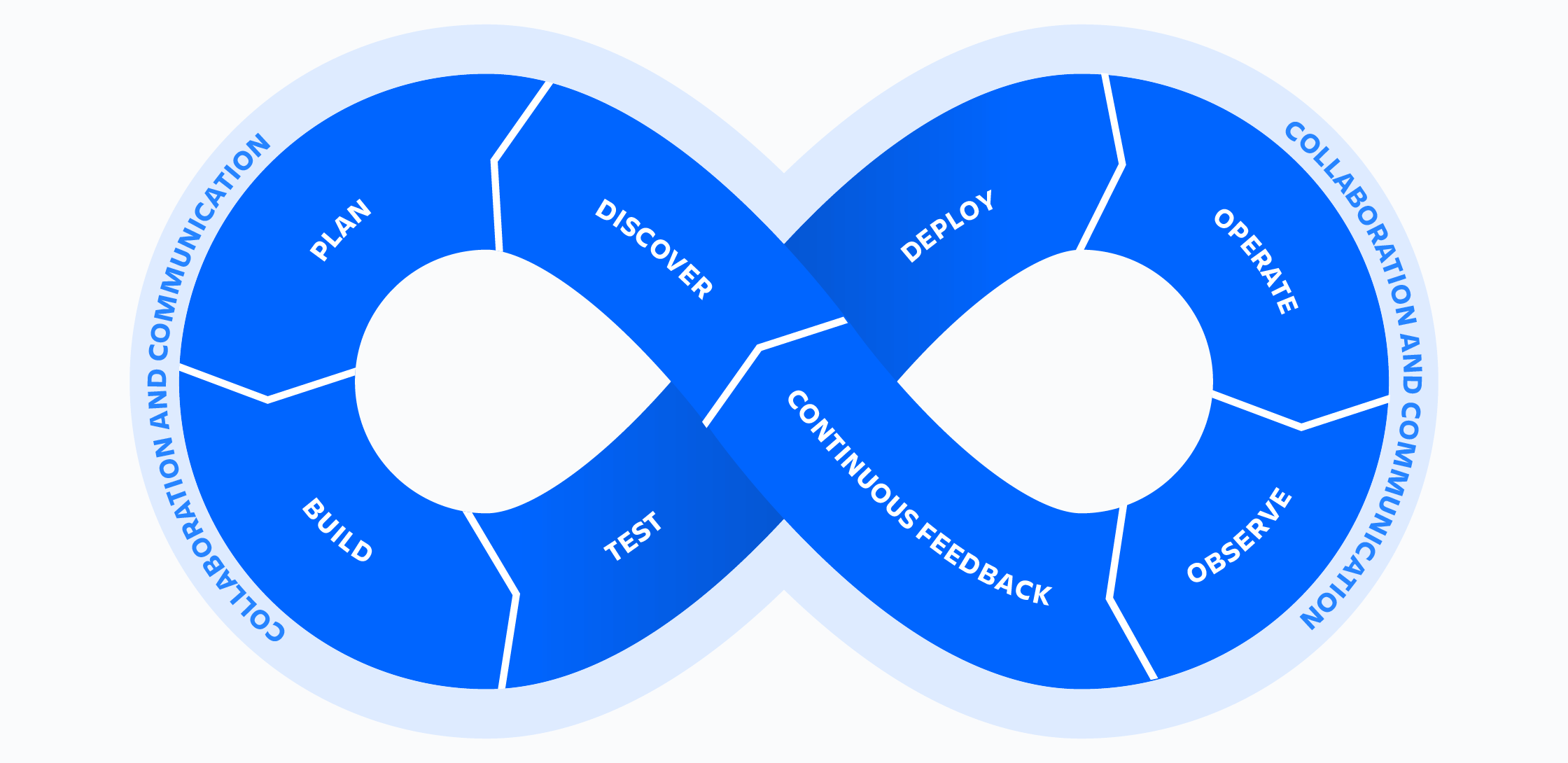
In a nutshell, the basic premise was that development teams and operations teams were now one team. QA was fired and replaced with this idea that because you could very quickly deploy new releases and get feedback on those releases, you didn't need a lengthy internal test period where every piece of functionality was retested and determined to still be relevant.
Often this is conflated with the concept of SRE from Google, which I will argue until I die is a giant mistake. SRE is in the same genre but a very different tune, with a much more disciplined and structured approach to this problem. DevOps instead is about the simplification of the stack such that any developer on your team can deploy to production as many times in a day as they wish with only the minimal amounts of control on that deployment to ensure it had a reasonably high chance of working.
In reality DevOps as a practice looks much more like how Facebook operated, with employees committing to production on their first day and relying extensively on real-world signals to determine success or failure vs QA and tightly controlled releases.
In practice it looks like this:
- Development makes a branch in git and adds a feature, fix, change, etc.
- They open up a PR and then someone else on that team looks at it, sees it passes their internal tests, approves it and then it gets merged into main. This is effectively the only safety step, relying on the reviewer to have perfect knowledge of all systems.
- This triggers a webhook to the CI/CD system which starts the build (often of an entire container with this code inside) and then once the container is built, it's pushed to a container registry.
- The CD system tells the servers that the new release exists, often through a Kubernetes deployment or pushing a new version of an internal package or using the internal CLI of the cloud providers specific "run a container as a service" platform. It then monitors and tells you about the success or failure of that deployment.
- Finally there are release-aware metrics which allow that same team, who is on-call for their application, to see if something has changed since they released it. Is latency up, error count up, etc. This is often just a line in a graph saying this was old and this is new.
- Depending on the system, this can either be something where every time the container is deployed it is on brand-new VMs or it is using some system like Kubernetes to deploy "the right number" of containers.
The sales pitch was simple. Everyone can do everything so teams no longer need as many specialized people. Frameworks like Rails made database operations less dangerous, so we don't need a team of DBAs. Hell, use something like Mongo and you never need a DBA!
DevOps combined with Agile ended up with a very different philosophy of programming which had the following conceits:
- The User is the Tester
- Every System Is Your Specialization
- Speed Of Shipping Above All
- Catch It In Metrics
- Uptime Is Free, SSO Costs Money (free features were premium, expensive availability wasn't charged for)
- Logs Are Business Intelligence
What Didn't Work
The first cracks in this model emerged pretty early on. Developers were testing on their local Mac and Windows machines and then deploying code to Linux servers configured from Ansible playbooks and left running for months, sometimes years. Inevitably small differences in the running fleet of production servers emerged, either from package upgrades for security reasons or just from random configuration events. This could be mitigated by frequently rotating the running servers by destroying and rebuilding them as fresh VMs, but in practice this wasn't done as often as it should have been.
Soon you would see things like "it's running fine on box 1,2, 4, 5, but 3 seems to be having problems". It wasn't clear in the DevOps model who exactly was supposed to go figure out what was happening or how. In the previous design someone who worked with Linux for years and with these specific servers would be monitoring the release, but now those team members often wouldn't even know a deployment was happening. Telling someone who is amazing at writing great Javascript to go "find the problem with a Linux box" turned out to be easier said than done.
Quickly feedback from developers started to pile up. They didn't want to have to spend all this time figuring out what Debian package they wanted for this or that dependency. It wasn't what they were interested in doing and also they weren't being rewarded for that work, since they were almost exclusively being measured for promotions by the software they shipped. This left the Operations folks in charge of "smoothing out" this process, which in practice often meant really wasteful practices.
You'd see really strange workflows around this time of doubling the number of production servers you were paying for by the hour during a deployment and then slowly scaling them down, all relying on the same AMI (server image) to ensure some baseline level of consistency. However since any update to the AMI required a full dev-stage-prod check, things like security upgrades took a very long time.
Soon you had just a pile of issues that became difficult to assign. Who "owned" platform errors that didn't result in problems for users? When a build worked locally but failed inside of Jenkins, what team needed to check that? The idea of we're all working on the same team broke down when it came to assigning ownership of annoying issues because someone had to own them or they'd just sit there forever untouched.
Enter Containers
DevOps got a real shot in the arm with the popularization of containers, which allowed the movement to progress past its awkward teenage years. Not only did this (mostly) solve the "it worked on my machine" thing but it also allowed for a massive simplification of the Linux server component part. Now servers were effectively dumb boxes running containers, either on their own with Docker compose or as part of a fleet with Kubernetes/ECS/App Engine/Nomad/whatever new thing that has been invented in the last two weeks.
Combined with you could move almost everything that might previous be a networking team problem or a SAN problem to configuration inside of the cloud provider through tools like Terraform and you saw a real flattening of the skill curve. This greatly reduced the expertise required to operate these platforms and allowed for more automation. Soon you started to see what we now recognize as the current standard for development which is "I push out a bajillion changes a day to production".
What Containers Didn't Fix
So there's a lot of other shit in that DevOps model we haven't talked about.
So far teams had improved the "build, test and deploy" parts. However operating the crap was still very hard. Observability was really really hard and expensive. Discoverability was actually harder than ever because stuff was constantly changing beneath your feet and finally the Planning part immediately collapsed into the ocean because now teams could do whatever they wanted all the time.
Operate
This meant someone going through and doing all the boring stuff. Upgrading Kubernetes, upgrading the host operating system, making firewall rules, setting up service meshes, enforcing network policies, running the bastion host, configuring the SSH keys, etc. What organizations quickly discovered was that this stuff was very time consuming to do and often required more specialization than the roles they had previously gotten rid of.
Before you needed a DBA, a sysadmin, a network engineer and some general Operations folks. Now you needed someone who not only understood databases but understood your specific cloud providers version of that database. You still needed someone with the sysadmin skills, but in addition they needed to be experts in your cloud platform in order to ensure you weren't exposing your database to the internet. Networking was still critical but now it all existed at a level outside of your control, meaning weird issues would sometimes have to get explained as "well that sometimes happens".
Often teams would delay maintenance tasks out of a fear of breaking something like k8s or their hosted database, but that resulted in delaying the pain and making their lives more difficult. This was the era where every startup I interviewed with basically just wanted someone to update all the stuff in their stack "safely". Every system was well past EOL and nobody knew how to Jenga it all together.
Observe
As applications shipped more often, knowing they worked became more important so you could roll back if it blew up in your face. However replacing simple uptime checks with detailed traces, metrics and logs was hard. These technologies are specialized and require detailed understanding of what they do and how they work. A syslog centralized box lasts to a point and then it doesn't. Prometheus scales to x amount of metrics and then no longer works on a single box. You needed someone who had a detailed understanding of how metrics, logs and traces worked and how to work with development teams in getting them sending the correct signal to the right places at the right amount of fidelity.
Or you could pay a SaaS a shocking amount to do it for you. The rise of companies like Datadog and the eye-watering bills that followed was proof that they understood how important what they were providing was. You quickly saw Observability bills exceed CPU and networking costs for organizations as one team would misconfigure their application logs and suddenly you have blown through your monthly quota in a week.
Developers were being expected to monitor with detailed precision what was happening with their applications without a full understanding of what they were seeing. How many metrics and logs were being dropped on the floor or sampled away, how did the platform work in displaying these logs to them, how do you write an query for terabytes of logs so that you can surface what you need quickly, all of this was being passed around in Confluence pages being written by desperate developers who were learning as they were getting paged at 2AM how all this shit works together.
Continuous Feedback
This to me is the same problem as Observe. It's about whether your deployment worked or not and whether you had signal from internal tests if it was likely to work. It's also about feedback from the team on what in this process worked and what didn't, but because nobody ever did anything with that internal feedback we can just throw that one directly in the trash.
I guess in theory this would be retros where we all complain about the same six things every sprint and then continue with our lives. I'm not an Agile Karate Master so you'll need to talk to the experts.
Discover
A big pitch of combining these teams was the idea of more knowledge sharing. Development teams and Operation teams would be able to cross-share more about what things did and how they worked. Again it's an interesting idea and there was some improvement to discoverability, but in practice that isn't how the incentives were aligned.
Developers weren't rewarded for discovering more about how the platform operated and Operations didn't have any incentive to sit down and figure out how the frontend was built. It's not a lack of intellectual curiosity by either party, just the finite amount of time we all have before we die and what we get rewarded for doing. Being surprised that this didn't work is like being surprised a mouse didn't go down the tunnel with no cheese just for the experience.
In practice I "discovered" that if NPM was down nothing worked and the frontend team "discovered" that troubleshooting Kubernetes was a bit like Warhammer 40k Adeptus Mechanicus waving incense in front of machines they didn't understand in the hopes that it would make the problem go away.

Plan
Maybe more than anything else, this lack of centralization impacted planning. Since teams weren't syncing on a regular basis anymore, things could continue in crazy directions unchecked. In theory PMs were syncing with each other to try and ensure there were railroad tracks in front of the train before it plowed into the ground at 100 MPH, but that was a lot to put on a small cadre of people.
We see this especially in large orgs with microservices where it is easier to write a new microservice to do something rather than figure out which existing microservice does the thing you are trying to do. This model was sustainable when money was free and cloud budgets were unlimited, but once that gravy train crashed into the mountain of "businesses need to be profitable and pay taxes" that stopped making sense.
The Part Where We All Gave Up
A lot of orgs solved the problems above by simply throwing bodies into the mix. More developers meant it was possible for teams to have someone (anyone) learn more about the systems and how to fix them. Adding more levels of PMs and overall planning staff meant even with the frantic pace of change it was...more possible to keep an eye on what was happening. While cloud bills continued to go unbounded, for the most part these services worked and allowed people to do the things they wanted to do.
Then layoffs started and budget cuts. Suddenly it wasn't acceptable to spend unlimited money with your logging platform and your cloud provider as well as having a full team. Almost instantly I saw the shift as organizations started talking about "going back to basics". Among this was a hard turn in the narrative around Kubernetes where it went from an amazing technology that lets you grow to Google-scale to a weight around an organizations neck nobody understood.
Platform Engineering
Since there are no new ideas, just new terms, a successor to the throne has emerged. No longer are development teams expected to understand and troubleshoot the platforms that run their software, instead the idea is that the entire process is completely abstracted away from them. They provide the container and that is the end of the relationship.
From a certain perspective this makes more sense since it places the ownership for the operation of the platform with the people who should have owned it from the beginning. It also removes some of the ambiguity over what is whose problem. The development teams are still on-call for their specific application errors, but platform teams are allowed to enforce more global rules.
Well at least in theory. In practice this is another expansion of roles. You went from needing to be a Linux sysadmin to being a cloud-certified Linux sysadmin to being a Kubernetes-certified multicloud Linux sysadmin to finally being an application developer who can create a useful webUI for deploying applications on top of a multicloud stack that runs on Kubernetes in multiple regions with perfect uptime and observability that doesn't blow the budget. I guess at some point between learning the difference between AWS and GCP we were all supposed to go out and learn how to make useful websites.

This division of labor makes no sense but at least it's something I guess. Feels like somehow Developers got stuck with a lot more work and Operation teams now need to learn 600 technologies a week. Surprisingly tech executives didn't get any additional work with this system. I'm sure the next reorg they'll chip in more.
Conclusion
We are now seeing a massive contraction of the Infrastructure space. Teams are increasingly looking for simple, less platform specific tooling. In my own personal circles it feels like a real return to basics, as small and medium organizations abandon technology like Kubernetes and adopt much more simple and easy-to-troubleshoot workflows like "a bash script that pulls a new container".
In some respects it's a positive change, as organizations stop pretending they needed a "global scale" and can focus on actually servicing the users and developers they have. In reality a lot of this technology was adopted by organizations who weren't ready for it and didn't have a great plan for how to use it.
However Platform Engineering is not a magical solution to the problem. It is instead another fabrication of an industry desperate to show monthly growth in cloud providers who know teams lack the expertise to create the kinds of tooling described by such practices. In reality organizations need to be more brutally honest about what they actually need vs what bullshit they've been led to believe they need.
My hope is that we keep the gains from the DevOps approach and focus on simplification and stability over rapid transformation in the Infrastructure space. I think we desperately need a return to basics ideology that encourages teams to stop designing with the expectation that endless growth is the only possible outcome of every product launch.